
2026 年 6 月 1 日,台北 GTC,黄仁勋穿着一件看起来和往常没太大区别的皮衣,发布了 NVIDIA RTX Spark——一颗基于 Arm 架构的 PC 超级芯片。
媒体标题大多集中在"英伟达杀入 PC 处理器市场"这件事上,但如果只把它理解成一场抢地盘的游戏,就错过了真正值得关注的东西。
这不单单是一颗芯片的事儿。
放在 AI 时代,可能其意义在于"个人电脑是什么"的重新定义,而 Mac 用户——尤其是那些习惯了 Apple的 M系列芯片在笔记本领域独步天下的人——大概是最需要认真对待这场发布会的一个群体。
英伟达这次做了一件很有意思的事,它把数据中心那套逻辑,完整地搬进了一台 14 毫米厚、1.36 公斤重的轻薄本里。
看看参数——RTX Spark 集成了一个 20 核的 Grace CPU(联发科联合设计,代号 N1X)和一颗 Blackwell RTX GPU,通过 NVLink-C2C 总线连接,共享最高 128GB 的统一内存,如果用 FP4 精度来衡量AI 算力,可以达到 1 petaflop。

老黄的逻辑很清楚:既然未来 PC 的核心价值从跑 office 到了本地运行 AI 智能体、生成式模型和推理任务,那衡量一台电脑好坏的标准就得彻底重写。
所以过去的那些 CPU 单核跑分、 GPU 渲染速度已经没那么重要,「你能在我这台机器上跑多大的模型,跑多快,以及——能不能不联网也能跑」,或许才是AI 时代评判PC 的铁律。
某种程度上,我愿称之为这是英伟达的"苹果芯片时刻",但它做的比苹果更激进。
苹果在 2020 年推出 M1 的时候,做的事情是把 Arm 架构的高能效比带进 Mac,让轻薄本也能拥有桌面级的性能体验。
英伟达在 2026 年做的是同一个方向上的升级版——它不仅要把 Arm 的能效带进 Windows,还要把数据中心级别的 AI 算力一并打包塞进去。
128GB 统一内存的上限,已经超过了目前 MacBook Pro 除顶配外所有型号的配置,而 1 petaflop 的 AI 算力,更是苹果 M 系列目前难以企及的数字。
不过,数据好看是一回事,真正能用起来是另一回事,这才是 RTX Spark 带来多大价值的关键。
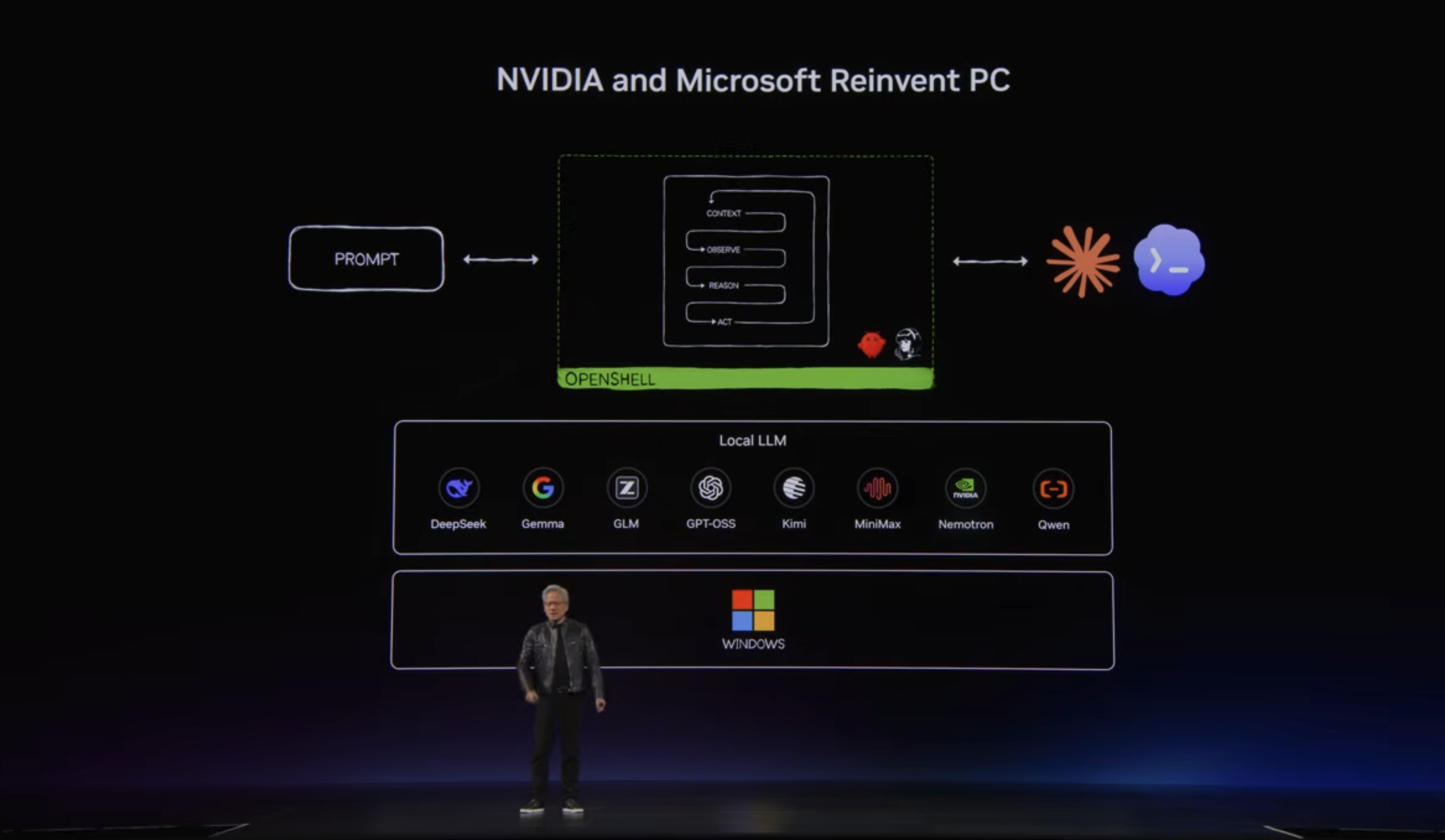
第一层影响,在 Windows on Arm 本身。
Windows on Arm 不是新东西。微软和高通已经在这条路上走了好几年,但一直有一个尴尬的问题:搭载骁龙芯片的 Windows 设备,始终被定位为"够用就行"的效率型产品,高端性能市场仍然是 x86 的天下。
这肯定不是高通的错,毕竟它的 GPU 生态和英伟达比,确实差了一个量级,没法强求。而RTX Spark 的出现,第一次让 Windows on Arm 有了一个真正意义上的旗舰平台。
目前超过 30 款笔记本和 10 款台式机已经在排队,首发厂商名单涵盖了华硕、戴尔、惠普、联想、微软 Surface 和微星——基本上,除了苹果,你叫得出名字的 PC 厂商都上了车。
这说明产业界对 Windows on Arm 的信心正在发生质变。
这种质变背后,是微软在操作系统层面给出的配合承诺:Windows 安全基元 + NVIDIA OpenShell 安全框架,共同构建了一套从身份认证到端到端安全的智能体运行环境。
微软 CEO 萨提亚的说法是"让每个使用 Windows 的家庭、每张办公桌都能获得不限量的智能"——这话的潜台词很直白:在微软的规划里,Windows 不再只是一个操作系统,而是一个 AI 智能体的宿主平台。
往大里点说,这标志着"Wintel"联盟的正式解体和"Winvidia"联盟的成型。
过去三十年,英特尔和微软定义了 PC 的标准——英特尔提供 x86 芯片,微软提供 Windows 系统,两者的升级节奏决定了整个产业的换代周期。
现在英伟达用 Arm 架构的超级芯片取代了英特尔的角色,而微软用 Windows 智能体安全框架完成了系统层面的配合,是不是有点似曾相识?
第二层影响,在创意工作者和 AI 开发者。
这是 Mac 用户尤其需要关注的部分。长期以来,Mac 在创意专业领域有一个几乎不可撼动的优势:Adobe 全家桶、Final Cut Pro、Logic Pro 这些专业软件,在 macOS 上的体验远好于 Windows。
但这次发布会上,Adobe 明确宣布 Photoshop 和 Premiere Pro 将从底层重构,推出原生 Arm 版,深度集成 RTX Spark 的 AI 加速能力,性能最高提升两倍,而包括Blackmagic Design、Blender、剪映、ComfyUI 等超过 100 个创意工具合作伙伴也全部入局。
逻辑很简单:如果 Adobe 开始在 Windows on Arm 上提供比 Mac 更好的 AI 原生体验,那"创意工作必选 Mac"这个信条就不再成立了,这当然不是说所有 Mac 用户明天就会叛逃——迁移成本、使用习惯、生态惯性都是真实存在的摩擦力——但至少,选择的天平不再天然倾向苹果那一端。
对 AI 开发者来说,RTX Spark 的吸引力可能更直接。
完整的 CUDA 生态——6,144 个 CUDA 核心、第五代 Tensor Core、DLSS 4.5、TensorRT——被完整地继承到了一台轻薄本上。用老黄的话说——这是"我们将 33 年所学凝聚于一枚芯片的结晶"。
换句话说,一名 AI 开发者不再需要一台笨重的游戏本或远程连接云 GPU 来跑模型,一台 14 寸笔记本就能本地跑 120B 参数的大模型,上下文长度可以达到 100 万 token,这对于降低开发迭代周期和 API 调用成本的意义,怎么强调都不为过。
第三层影响,才是对苹果 Mac 的直接挑战——而这一层恰恰是最需要冷静看待的。
RTX Spark 在纸面上确实把苹果 M 系列的几个核心优势逐一对标了:统一内存架构?我有,而且最大 128GB。Arm 能效比?我也有,台积电 3nm 工艺。轻薄设计?首批产品最薄 14 毫米,最轻 1.36 公斤。但有一个关键数据,英伟达在整个发布会上一个字都没提——功耗。
苹果 M 系列芯片真正的护城河,从来不只是统一内存或者 Arm 架构,而是每瓦性能。
一台 MacBook Air 可以无风扇运行,续航轻松超过 15 小时,这是苹果花了五年时间、三代芯片迭代才打磨出来的工程成果。
RTX Spark 挂着 1 petaflop 的算力和 6,144 个 CUDA 核心,在 14 毫米的机身里到底能跑多久才需要充电?风扇噪音有多大?这些问题的答案,要等秋季产品上市后的独立评测才能揭晓。在此之前,所有对"Mac 完蛋了"的判断,都是过早的。
那么,如果 RTX Spark 的续航和散热达不到 Mac 的水平,那它的市场定位就从"M 系列杀手"变成了一个更窄的东西——一台专为 AI 开发者和重度创作者设计的高端 Windows 设备——但是,这个市场本来就不属于 Mac。
不过,即使把能效比的不确定性考虑进去,RTX Spark 对 Mac 生态的战略压力仍然是真实存在的。
原因不是某一款产品的胜负,更在于方向。英伟达把 AI 算力定义为 PC 的核心价值指标,这个定义一旦被市场接受,苹果就必须跟上,而苹果目前在端侧大模型运行上的能力——至少从公开可用的产品层面来看——和 RTX Spark 的差距是显著的。
更有意思的是英伟达公开的三代路线图。
黄仁勋承诺,未来每一代 NVIDIA 平台都将包含 Spark 芯片,算得上是一张十年期的战略牌。
当一个手握数据中心 AI 市场 80% 以上份额的公司,决定把自己的技术栈完整下沉到消费级 PC,相当是是在"重写"这个市场的底层规则。
问题在于,RTX Spark 的成功需要几个前提同时成立:Windows on Arm 的 x86 兼容性要足够好(微软 Prism 模拟器届时将经历两年优化,但实际表现仍需验证);首批产品的定价——顶配预计超过 3,000 美元——不能高到劝退除了发烧友之外的所有人;以及最重要的,开发者真的会为这个新平台开发原生应用,而不是继续守着 x86 的摊子。
所幸的是,第三个条件看起来是最有可能被满足的。
因为英伟达带来了别家都没有的东西——CUDA。一个 AI 开发者只要把现有的 CUDA 代码原样搬过来就能跑,不需要重写、不需要适配、不需要学新框架,这种零迁移成本,是曾经所有 Arm PC 平台都无法提供的。
所以,英伟达打的算盘是:我不需要说服你买 RTX Spark,我只需要保证,当你想在笔记本上本地跑大模型的时候,你找不到比 RTX Spark 更快的东西,需求会自动完成说服。
从这个意义上说,RTX Spark 不仅是一颗芯片的发布,而是英伟达从云端向下游渗透的战略支点,是 Windows 生态从 x86 向 Arm 迁移的加速器,也是苹果在 Arm PC 领域享受了六年独孤求败之后,第一个值得认真对待的竞争者。
至于 Mac 用户该不该慌——这取决于你是为了什么买 Mac——如果是因为系统流畅、生态稳定、能效出色,那大概率还没到该紧张的时候。但如果是因为"除了 Mac,没什么机器能认真做 AI 开发"的理由,从 2026 年秋天开始,可能就不再成立了。
这就是当一家 GPU 公司决定造 CPU 时,整个行业的座次表,都得重新排一遍的道理。