Xiaoxiao Long∗, Qingrui Zhao∗, Kaiwen Zhang∗, Zihao Zhang∗, Dingrui Wang∗, Yumeng Liu∗, Zhengjie Shu∗
Yi Lu∗, Shouzheng Wang∗, Xinzhe Wei∗, Wei Li, Wei Yin, Yao Yao, Jia Pan, Qiu Shen, Ruigang Yang,
Xun Cao†, Qionghai Dai
摘要:
AGI的探索将具身智能推至机器人研究的前沿。具身智能聚焦于能够在物理世界中感知、推理和行动的智能体。实现稳健的具身智能不仅需要先进的感知与控制,还需将抽象认知扎根于现实世界的交互。物理模拟器与世界模型作为两项基础技术,已成为该探索中的关键使能技术。物理模拟器提供受控、高保真环境,用于训练和评估机器人智能体,支持复杂行为的安全高效开发。相比之下,世界模型赋予机器人对周围环境的内部表征,使其能够进行超出直接感官输入的预测性规划与自适应决策。
本综述系统回顾了通过整合物理模拟器与世界模型学习具身人工智能的最新进展。我们分析了它们在增强智能机器人自主性、适应性与泛化能力方面的互补作用,并探讨了外部模拟与内部建模在弥合仿真训练与实际部署差距中的相互作用。通过整合当前进展并识别开放性挑战,本综述旨在为更强大、更泛化的具身AI系统的发展路径提供全面视角。此外,我们维护了一个活跃的代码仓库,包含最新文献和开源项目,地址为https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey。
关键词:具身智能、世界模型、物理模拟器、自动驾驶、机器人学习
1 引言
1.1 概述
随着人工智能[1], [2]和机器人技术[3], [4]的快速发展,智能体与物理世界的交互日益成为研究的核心焦点。AGI——即能够跨越不同领域匹配或超越人类认知能力的系统——的追求面临一个关键问题:如何将抽象推理扎根于现实世界的理解和行动中?
智能机器人已成为关键的具身智能体,通过提供连接计算智能与现实世界交互的物理媒介,为通向AGI铺平道路。与仅基于符号或数字数据运行的非具身智能系统不同,具身智能强调通过与环境的物理交互来实现感知、行动和认知的重要性。这一范式使机器人能够在执行任务时基于物理世界的反馈持续调整其行为和认知,使机器人技术不仅仅是AI的应用,更是通向AGI的关键组成部分。

图1:物理模拟器和世界模型在具身智能中发挥关键作用。物理模拟器提供了对现实世界的显式建模,为机器人提供了一个受控环境,使其能够训练、测试和优化行为。世界模型提供了环境的内部表征,机器人能够在认知框架内自主模拟、预测和规划行动。
具身智能的意义不仅限于物理任务的执行。依托物理身体进行行动与感知 [5],机器人能够鲁棒地从经验中学习、测试假设并通过持续交互优化策略。这种感官输入、运动控制与认知处理的闭环集成构成了真正自主性与适应性的基础,使机器人能够以更拟人化的方式推理和应对世界 [6]。

图2:综述大纲:我们将智能机器人发展分为五个级别(IR-L0至IR-L4),并综述了机器人移动、操作和交互方面的进展与关键技术(§3)、物理仿真器在学习和控制算法验证中的应用(§4),以及世界模型作为内部表征在学习、规划和决策中的设计与应用(§5–§6),强调显性和隐性学习路径,以更拟人化的方式[6]。
随着智能机器人在现实场景中的应用日益广泛,例如养老护理 [7]、医疗辅助 [8]、灾难救援 [9] 和教育 [10],其在动态、不确定环境中的自主安全运行能力变得至关重要。然而,应用的多样性和技术进步的快速步伐催生了对系统性框架的迫切需求,以评估和比较机器人能力。建立科学的机器人智能分级体系不仅能够明确技术发展路线图,还能为监管、安全评估和伦理部署提供重要指导。
为应对这一需求,近期研究探索了多种量化机器人能力的框架,例如 DARPA 机器人挑战赛评估方案 [11]、ISO 13482 服务机器人安全标准 [12] 以及自主性水平的相关综述 [13]、[14]。然而,一个整合了智能认知、自主行为和社会互动维度的综合性分级体系仍然缺失。
本文提出一种智能机器人的能力分级模型,系统性地阐述了从基础机械执行到高级完全自主社会智能的五个渐进级别(IR-L0至IR-L4)。该分类涵盖了自主性、任务处理能力、环境适应性和社会认知等关键维度,为评估和指导智能机器人在整个技术演进谱系中的发展提供了统一框架。
实现机器人智能行为的两大关键技术是物理模拟器和世界模型。两者在提升机器人控制能力及拓展其潜力方面发挥关键作用。模拟器(如Gazebo [15]或MuJoCo [16])对物理世界进行显式建模,为机器人提供受控环境,使其能在部署到现实场景前训练、测试和微调行为。模拟器作为训练场,可在无需现实世界实验高成本和高风险的情况下预测、测试和微调机器人的动作。
与模拟器不同,世界模型提供环境的内部表征,使机器人能够在认知框架内自主模拟、预测和规划动作。根据NVIDIA的定义,世界模型是“理解现实世界动态特性(包括物理和空间属性)的生成式AI模型”[17]。这一概念在Ha和Schmidhuber的开创性工作[18]中获得广泛关注,该研究展示了智能体如何学习紧凑的环境表征以进行内部规划。
模拟器与世界模型的协同作用提升了机器人在多样化场景中的自主性、适应性和任务性能。本文将探讨机器人控制算法、模拟器与世界模型之间的相互作用。通过分析模拟器如何提供结构化的外部训练环境,以及世界模型如何创建内部表征以支持更具适应性的决策,我们旨在全面理解这些组件如何协同工作以提升智能机器人的能力。
1.2 范围与贡献
范围:本综述全面分析了机器人控制算法、仿真器和世界模型之间的相互作用,主要聚焦于2018年至2025年的进展。我们的覆盖范围包括传统基于物理的仿真器和新兴世界模型,强调它们在自动驾驶和机器人领域的影响。
与现有文献不同,本综述全面探讨了物理模拟器与世界模型在推动具身智能中的协同关系。以往的综述通常仅关注单一组件(如机器人模拟器[19]–[21]和世界模型[22]–[24]),而本文则弥合了这两个领域,揭示了它们在智能机器人开发中的互补作用。
贡献.主要贡献如下:
• 智能机器人等级划分:提出人形机器人自主性评估的五级分级标准(IR-L0至IR-L4),涵盖自主性、任务处理能力、环境适应性和社会认知能力四个关键维度。
• 机器人学习技术分析:系统回顾智能机器人在腿式运动(双足行走、跌倒恢复)、操作(灵巧控制、双手机能协调)及人机交互(认知协作、社会嵌入性)领域的最新进展。
• 物理仿真器分析:对主流仿真器(Webots、Gazebo、MuJoCo、Isaac Gym/Sim/Lab等)进行综合对比分析,涵盖物理仿真能力、渲染质量及传感器支持。
• 世界模型的最新进展:首先回顾世界模型的主要架构及其潜在作用,例如作为具身智能的可控仿真器、动力学模型和奖励模型;此外,全面讨论了专为自动驾驶和关节机器人等特定应用设计的最新世界模型。
1.3 结构
论文结构摘要如图2所示,具体如下:
• 第1节介绍具身AI的重要性,并阐述物理仿真器和世界模型如何推动具身AI的发展。
• 第2节提供了一个五级智能机器人综合分级系统。
– 2.1 等级标准
– 2.2 等级因素
– 2.3 分级级别
• 第3节回顾智能机器人任务在移动性、灵巧性和人机交互方面的当前进展。
– 3.1 相关机器人技术
– 3.2 机器人运动
– 3.3 机器人操作
– 3.4 人机交互
• 第4节讨论当代机器人研究中主流仿真器的优缺点。
– 4.1 主流仿真器
– 4.2 仿真器的物理特性
– 4.3 渲染能力
– 4.4 传感器与关节组件类型
– 4.5 讨论与未来展望
• 第5节介绍世界模型的代表性架构和核心作用。
– 5.1 世界模型的代表性架构
– 5.2 世界模型的核心作用
• 第6节进一步回顾世界模型在智能体(包括自动驾驶和关节机器人)中的应用与挑战。
– 6.1 自动驾驶中的世界模型
– 6.2 关节机器人中的世界模型
– 6.3 挑战与未来展望
2 智能机器人级别
随着人工智能、机械工程、传感器融合和人机交互等领域的快速发展,智能机器人正逐步从实验室走向实际应用场景,包括老年护理[7]、医疗辅助[8]、灾害救援[9]和教育[10]。与传统工业机器人不同,智能机器人强调基于类人结构完成复杂的认知、感知和执行任务。真实环境中的动态性和不确定性使得能力评估成为关键问题。因此,建立科学的能力分级体系不仅有助于明确技术发展路线,还能为机器人监管和安全评估提供指导。
目前,已有若干研究尝试量化机器人能力,例如DARPA机器人挑战赛框架用于评估执行复杂任务的能力 [11]、ISO 13482服务机器人安全分级标准 [12],以及关于机器人自主性等级的综述 [13], [14]。然而,目前仍缺乏将“智能认知”与“自主行为”两个维度相结合的综合分级体系。为此,本文提出并系统阐述了从IR-L0到IR-L4的智能机器人能力分级模型,涵盖从机械操作级别到高级社会交互级别的完整技术演进路径。
2.1 级别标准
该标准依据机器人在不同环境中的任务执行能力、自主决策深度、交互复杂性及伦理认知对其进行分类。涵盖的核心维度如下:
• 机器人独立完成任务的能力,从完全依赖人工控制到完全自主。
• 机器人可处理任务的难度,从简单重复性劳动到创新性问题解决。
• 机器人在动态或极端环境中的工作能力。
• 机器人理解、互动及应对人类社会中社交情境的能力。
2.2 等级因素
机器人的智能等级根据以下五个因素进行分级。
• 自主性:机器人在各种任务中自主决策的能力
• 任务处理能力:机器人可处理任务的复杂度
• 环境适应性:机器人在不同环境中的适应能力
• 社会认知能力:机器人在社交场景中的智能水平

图3:智能机器人等级:从基础执行到完全自主
分级与层级因素的关系列于表1中。

表1:分级与层级因素的关系
分级与层级因素的关系列于表1中。
2.3 分类级别
2.3.1 IR-L0:基础执行级别
IR-L0 代表该系统中的基础执行级别,其特征是完全非智能、程序驱动型的属性。该级别机器人专注于执行高度重复、机械化、确定性任务,例如工业焊接和固定路径物料搬运。这种“低感知-高执行”的操作模式使机器人完全依赖预定义的程序指令或实时遥操作。它缺乏环境感知、状态反馈或自主决策能力,形成单向闭环系统,即“命令输入-机械执行” [25]。潜在的技术要求总结如下:
• 硬件:高精度伺服电机和刚性机械结构,运动控制器基于PLC或MCU。
• 感知:极其有限,通常仅涉及限位开关、编码器等。
• 控制算法:主要基于预定义脚本、动作序列或遥操作,无实时反馈回路。
• 人机交互:无,或仅限于简单按钮/遥操作。
2.3.2 IR-L1:程序化响应级别
IR-L1机器人具有有限的基于规则的反应能力,能够执行预定义的任务序列,例如清洁机器人和接待机器人所执行的任务。这些系统利用基本传感器(包括红外、超声波和压力传感器)来触发特定的行为模式。它们无法处理复杂或意外事件,只能在具有明确规则的封闭任务环境中保持操作稳定性。它们体现了“有限感知-有限执行”的范式,代表了基础机器人智能的开端[26]。潜在的技术要求总结如下:
• 硬件:集成基本传感器(红外、超声波、压力)与适度增强的处理器能力。
• 感知:障碍物、边界及简单人体运动的检测。
• 控制算法:规则引擎和有限状态机(FSM),辅以基本SLAM或随机游走算法。
• 人机交互:支持简单命令-响应协议的基本语音和触摸界面。
• 软件架构:嵌入式实时操作系统,具备基本的任务调度能力。
2.3.3 IR-L2:基本感知与适应层级
IR-L2机器人引入了初步的环境感知能力和自主能力,代表了机器人智能的重大进步。其特点包括对环境变化的基本响应能力以及在多种任务模式间切换的能力。例如,该级别的服务机器人能够根据语音命令执行“送水”或“导航指引”等不同任务,同时在路径执行过程中避障。这些系统需要集成感知模块(摄像头、麦克风阵列、LiDAR)和基础行为决策框架,如有限状态机(FSM)或行为树[27]。
尽管人工监督仍然必不可少,但IR-L2机器人相较于IR-L1系统展现出显著更高的执行灵活性,标志着其向真正的“上下文理解”迈进。潜在的技术要求总结如下:
• 硬件:多模态传感器阵列(摄像头、LiDAR、麦克风阵列)搭配增强的计算资源。
• 感知:视觉处理、听觉识别和空间定位能力,支持基本物体识别和环境建图。
• 控制算法:有限状态机、行为树、SLAM实现、路径规划和避障系统。
• 人机交互:语音识别与合成能力,支持基本指令的理解与执行。
• 软件架构:模块化设计框架,支持并行任务执行及初步优先级管理系统。
2.3.4 IR-L3:人形认知与协作级别
IR-L3机器人在复杂动态环境中具备自主决策能力,同时支持复杂的多模态人机交互。这些系统能够推断用户意图,相应调整行为,并在既定的伦理约束下运行。例如,在养老护理应用中,IR-L3机器人通过分析语音模式和面部表情检测老年患者的情绪状态变化,并采取相应的安慰措施或发出紧急警报。潜在的技术要求总结如下:
• 硬件:集成全面多模态传感器套件(深度摄像头、肌电传感器、力传感阵列)的高性能计算平台。
• 感知:视觉、语音和触觉输入的多模态融合;情感计算用于情绪识别和动态用户建模。
• 控制算法:用于感知和语言理解的深度学习架构(CNNs、Transformers);用于自适应策略优化的强化学习;用于复杂任务工作流管理的规划与推理模块。
• 人机交互:多轮自然语言对话支持;面部表情识别与反馈;基础共情与情绪调节能力。
• 软件架构:支持任务分解与协同执行的面向服务分布式框架;集成学习与自适应机制。
• 安全与伦理:嵌入式伦理治理体系,防止不安全或不合规行为。
2.3.5 IR-L4:完全自主级别
IR-L4代表了智能机器人的巅峰:系统在感知、决策和执行方面具备完全自主能力,能够在任何环境中独立运行而无需人工干预。这类机器人具备自我进化的伦理推理能力、高级认知能力、同理心以及长期适应性学习能力。除了处理开放式任务外,它们还参与复杂的社交互动,包括多轮自然语言对话、情感理解、文化适应和多智能体协作。潜在的技术要求总结如下:
• 硬件:高度仿生结构,具备全身多自由度关节;分布式高性能计算平台。
• 感知:全向、多尺度、多模态传感系统;实时环境建模与意图推断。
• 控制算法:集成元学习、生成式AI和具身智能的AGI框架;自主任务生成与高级推理能力。
• 人机交互:自然语言理解与生成;复杂社交情境适应;同理心与伦理考量。
• 软件架构:云-边-端协同系统;支持自进化与知识迁移的分布式智能体架构。
• 安全与伦理:嵌入式动态伦理决策系统,约束行为并确保在伦理困境中做出道德上正确的选择。
3 机器人移动性、灵巧性与交互
在各种智能机器人的形态中,人形机器人以其类人外观为特征,能够无缝融入以人类为中心的环境并提供有意义的帮助,因此它们是具身智能的关键物理体现。
近年来,机器学习技术的快速发展在机器人全身控制和通用操作方面取得了重大突破。本章首先概述智能机器人领域的基础技术方法,然后回顾机器人运动与操作的最新进展,最后探讨旨在实现自然直观的人机交互的持续研究。
3.1相关机器人技术
3.1.1 模型预测控制(MPC)
模型预测控制(MPC)[28] 是一种强大的控制策略,在过去二十年中在人形机器人领域获得了广泛应用。其核心是基于优化的方法,通过动态模型预测系统未来行为,并在每个时间步求解优化问题以计算控制动作。这使得控制器能够显式处理输入和状态的约束,特别适用于人形机器人等复杂高维系统[29]。
Tom Erez 等人提出了一套全面的实时MPC系统,将MPC应用于人形机器人的完整动力学,使其能够完成站立、行走和从扰动中恢复等复杂任务[30]。在此基础上,2015年,Jonas Koenemann、Andrea Del Prete、Yuval Tassa、Emanuel Todorov等人实现了完整的MPC,并在物理HRP-2机器人上实时应用,首次在复杂动力学机器人上实现了全身模型预测控制器的实时应用[31]。
3.1.2 全身控制(WBC)
人形机器人中的全身控制(WBC)是一个综合框架,使机器人能够同时协调所有关节和肢体以实现不同的运动。全身控制的基本方法通常涉及将机器人的运动和力目标表示为一组具有优先级的任务,例如保持平衡、跟踪期望轨迹或用手施加特定力。这些任务随后被转化为数学约束和目标,并通过优化技术或分层控制框架[32]求解。
在实现过程中,WBC通常采用动态建模、逆运动学求解和优化算法等技术,以确保机器人在满足物理约束的同时实现期望的运动行为。2000年代初,Oussama Khatib及其合作者提出了用于控制冗余机械臂的操作空间公式,并将其扩展至人形机器人[33]。基于优化的WBC具有高度灵活性,支持模块化添加或移除约束,并通过设置不同的任务层次或软任务权重来解决冲突约束[34]–[36]。近年来,随着人工智能(如强化学习)的发展,研究者提出了ExBody2[37]和HugWBC[38]等框架,这些框架在模拟环境中训练控制策略并将其迁移至实际机器人,实现了更自然、更具表现力的全身运动控制。
3.1.3 强化学习
强化学习(RL)[39] 是机器学习的一个分支,在人形机器人领域影响力日益增强。RL 的核心思想是,智能体(例如人形机器人)可以通过与环境交互并接收奖励或惩罚形式的反馈来学习执行复杂任务。与需要显式编程或行为建模的传统控制方法 [40], [41] 不同,RL 使机器人能够通过试错自主发现最优动作,特别适用于人形机器人常面临的高维、动态及不确定环境 [42]。
强化学习在人形机器人中的应用可追溯至20世纪90年代末和21世纪初。1998年,森本正弘(Masahiro Morimoto)和东野健二(Kenji Doya)提出了一种强化学习方法,使模拟的双关节三连杆机器人能够自主学习从躺卧状态到站立的动态动作 [43]。此后,RL 被用于实现人形机器人的复杂行为;DeepLoco [44] 及其他研究 [45], [46] 对深度强化学习在双足任务中的能力进行了广泛探索,但尚未证明适用于物理机器人。2019年,谢等人采用迭代强化学习和确定性动作随机状态(DASS)元组,逐步优化奖励函数和策略架构,使物理 Cassie 双足机器人能够实现稳健的动态行走 [47]。
3.1.4 模仿学习
模仿学习(IL)是机器人学中的一种范式,机器人通过观察和模仿人类或其他智能体提供的演示来学习执行任务。模仿学习的核心理念在于无需显式编程或手工设计的奖励函数,使仿人机器人能够更高效、直观地习得复杂行为。通过利用演示数据,机器人可以学习行走、操作或社交互动等技能,而这些技能若通过传统控制或强化学习方法则难以明确指定[3]、[48]–[50]。
在仿人机器人运动控制中,模仿学习通常利用Retargeting后的人体动作捕捉数据,或基于模型轨迹规划生成的参考步态(如自然行走、跑步等),并促使机器人在仿真中遵循这些参考轨迹,以实现更自然、稳定的运动步态[51]–[53]。
虽然IL有效利用现有知识进行学习,但其面临诸多挑战,如获取专家演示数据的成本高昂、数据多样性不足、质量担忧以及流程耗时等问题。此外,基于有限演示数据训练的策略往往泛化能力较差,难以适应新环境或任务,所学操作技能也可能较为单一。为应对这些挑战,研究人员和公司正致力于开发更高效的数据收集硬件平台或遥操作技术以扩充数据[49]、[54]、[55],同时探索新型训练数据,例如从视频数据中提取人类动作[56]。
3.1.5 VLA模型
VLA模型是一种跨模态人工智能框架,整合了视觉感知、语言理解和动作生成。其核心概念是利用LLMs的推理能力,将自然语言指令直接映射到物理机器人的动作。

图4:人形机器人非结构化环境适应进展时间线
2023年,Google DeepMind推出了RT-2,首次将这一范式应用于机器人控制,通过将机器人控制指令离散化为类语言token,实现了端到端的视觉-语言-动作映射[65]。通过利用互联网规模的视觉-语言数据进行预训练,机器人能够理解先前未见过的语义概念,并通过思维链推理生成合理的动作序列。随后,众多端到端VLA模型涌现 [4] [66] [67] [68] [69] [70] [71],进一步推动了VLA模型在机器人领域的应用与发展。
尽管当前VLA模型已取得显著进展,但仍存在若干关键挑战。这些模型往往难以可靠地处理此前未遇到的任务或环境。此外,实时推理约束限制了它们在动态场景中的响应能力。此外,训练数据集中的偏差、跨模态语义 grounding 的困难以及系统集成的高计算复杂度继续阻碍进一步发展 [72]。
3.2 机器人运动
机器人运动的目标是实现自然的运动模式,包括行走、奔跑和跳跃。通过整合感知、规划和控制等多个领域,具备运动能力的机器人可归类于IR-L2级别。这种整合使机器人能够动态适应多变地形、外部干扰和突发情况,从而实现稳健且流畅的双足运动。此外,自主从意外事件中恢复的能力减少了对人工干预的依赖,为更高智能与自主性铺平了道路。本节将探讨腿式运动的最新进展,并讨论跌倒预防与恢复策略。
3.2.1 腿式运动
双足机器人在复杂地形导航、模拟人类行为以及无缝融入以人为中心的环境中具有独特优势。双足步态控制领域的研究可分为两个任务:Unstructured Environment Adaption,强调在复杂、未知或动态环境中保持稳定行走的能力;以及High Dynamic Movements,聚焦于在跑步、跳跃等高速动态运动中实现稳定性和敏捷性的平衡
非结构化环境适应。“非结构化环境”通常指复杂的自然或人工地形,如崎岖的山路、布满碎石的地面、湿滑的草地、楼梯以及其他不可预测的障碍物。早期双足行走稳定化研究主要采用位置控制的人形机器人。2008年,桑霍·海恩[57]提出了一种基于被动性的接触力控制框架,使SARCOS人形机器人[73]能够在高度变化和倾斜角度随时间变化的室内地形上主动保持平衡。后续研究探索了多种提升运动稳定性的策略,包括用于地形适应的在线学习[74]、结合地形估计的柔顺控制[58],以及线性倒立摆模型(LIPM)与足部力控制的结合[75],这些在2010年由角田等人在HRP-4C人形机器人上得到验证。
上述方法仅使人形机器人具备有限的地形适应能力,例如在细梁、路面或平坦但倾斜的坡道上行走。这是由于位置控制关节的高减速比。这些关节具有高阻抗,在输出轴或末端执行器(hand and foot)受到较大冲击时容易损坏 [76]。为了在未知环境中实现更好的适应性,现代人形和四足机器人采用低减速比的力控关节,能够在较大冲击下提供更好的顺应性和平稳的响应 [77], [78]。
随着力控人形机器人的发展和计算能力的提升,研究人员能够开发和实施更复杂的控制算法[85],这进一步提升了机器人在多样化环境中的适应性。Jacob Reher等人提出了一种全面的全身动力学控制器,明确考虑了Cassie双足机器人中的被动弹簧机构[59],成功实现了包括户外草地在内的多种地形上能稳定双足行走。George Mesesan等人将运动发散分量(DCM)用于质心轨迹规划,并结合基于被动性的全身控制器(WBC)计算关节力矩[60],在TORO机器人上实现了软垫上的动态行走。

图5:人形机器人高动态运动发展时间线
除了本体感觉盲行外,研究人员还探索了整合外部感知与路径规划模块以应对更复杂的环境。Jiunn-Kai Huang等人将低频路径规划器与高频反应式控制器相结合,生成平滑的反馈驱动运动指令[62]。这使Cassie Blue机器人能够自主穿越更复杂的地形,例如密歇根大学Wave Field。
基于学习的方法在户外复杂环境中也展现出良好的稳定性。2020年,Joonho Lee等人[86]首次在真实世界中成功应用强化学习于腿式运动,其在户外环境中的表现优于传统方法[87]。Jonah Siekmann等人使用Cassie机器人实现了无视觉楼梯穿越[61]。他们采用域随机化方法调整楼梯尺寸和机器人动力学参数,使学习到的策略成功迁移至现实场景。研究人员还利用深度相机和LiDAR构建高程地图[63]、感知内部模型(PIM)[88]或端到端策略[64],显著提升了机器人在不同地形中的移动能力。如今,机器人能够穿越楼梯、跨越障碍物,甚至跳跃跨越宽度达0.8米的间隙。
高动态运动。跑步和跳跃等高动态运动对双足机器人的控制系统提出了更高要求。在快速运动过程中,机器人必须在极短时间内处理快速支撑转换、姿态调整和精确力控制。
早期研究采用简化的动力学模型,例如弹簧负载倒立摆(SLIP)[89]、线性倒立摆模型(LIPM)[90]和单刚体模型(SRBM)[91],以降低计算复杂度并实现实时控制。熊晓斌和Aaron D. Ames开发了一种通过基于控制李雅普诺夫函数的二次规划(CLF-QP)[79]控制的简化弹簧质量模型,成功使卡西机器人实现18 cm垂直跳跃。Qi等[80]提出了一种基于压力中心(CoP)引导的角动量控制器,通过在飞行中稳定角动量,实现了高达0.5米的垂直跳跃。近期,He等[83]引入了结合模型预测控制(MPC)框架的质心动力学模型(CDM),称为CDM-MPC,以在KUAVO人形机器人上实现连续跳跃动作。
RL方法也被应用于动态任务。学习到的隐式机器人动力学在跑步[81]、跳跃[82]和离散地形跑酷[92]等活动中取得了有前景的结果,显著提升了双足运动能力。
从零开始训练高度动态的动作通常需要繁琐的奖励函数设计和参数调优。模仿学习利用大量人类运动数据集[93],实现了表现力强且动态的机器人行为。对抗性运动先验(AMP)[94]从动作捕捉数据中提取基于风格的奖励,增强了机器人动作的自然性。Exbody [37,95]、OmniH2O [96]和ASAP [84]等框架实现了自然且敏捷的全身运动。ASAP专门解决仿真到现实的差距,实现了诸如后仰跳投等复杂动作。
3.2.2 跌倒防护与恢复
人形机器人易因不稳定而跌倒,可能导致硬件损坏或操作中断。因此,人形机器人的跌倒防护及跌倒后高效恢复站立姿势已成为人形机器人研究中的重要课题。
基于模型的方法。早期基于模型的跌倒防护与恢复控制主要借鉴生物力学原理,模仿人类跌倒过程的生物力学特征,并结合优化控制方法生成运动轨迹,以减少跌倒时的损伤并实现稳定站立恢复。
UKEMI [97] 控制机器人在跌倒时的姿态,以分散冲击力并减少对关键部件的损伤。他们还设计了特定的关节运动模式和控制策略,以实现机器人跌倒恢复 [98]。孟立波等人通过人体跌倒的生物力学分析提出了一种跌倒运动控制方法,实现了适应不同跌倒方向的冲击保护控制 [99]。董等人提出了一种柔顺控制框架,使机器人能够根据外部扰动调整刚度和阻尼特性,类似于人类调节肌肉刚度以维持平衡的方式 [100]。
基于学习的方法。这类方法不依赖高精度模型且具备强大的泛化能力,能够更好地应对该任务。HiFAR [102] 通过多阶段课程学习方法逐步提升场景难度,训练人形机器人在多种真实场景中实现高成功率的摔倒恢复。HoST [101] 利用平滑正则化和隐式动作速度限制,在Unitree G1机器人上实现了多种环境中的稳健自然站立动作。Embrace Collisions [103] 通过全身接触扩展了机器人与环境的交互能力,突破了仅限于手和脚的限制;通过模仿翻滚起立、侧躺及其他多接触行为,该方法提升了人形机器人在现实场景中的运动范围和适应性。

图6:Tao Huang等[101]提出的HOST,使Unitree G1机器人能在复杂环境中从多种姿势起身。
3.3 机器人操作
机器人操作任务涵盖从拾取物体等简单动作到涉及装配或烹饪的复杂序列的广泛活动。本节将回顾机器人操作领域的研究进展,重点关注不同任务所需协调复杂度的逐步提升。从使用单个末端执行器(如手或夹爪)的操作开始,逐步过渡到双臂协调,最后探讨需要对整个机器人进行集成控制的全身操作任务。
3.3.1 单手操作任务
单手操作指的是使用单个末端执行器与物体交互并进行操作,例如平行夹爪或灵巧机械手。此类任务从基础的拾取和放置操作到更复杂的动作,如推动、插入、工具使用以及操作可变形或关节式物体不等。这些任务的复杂程度取决于末端执行器的性能及其交互环境。
夹爪操作。平行双指夹爪[104]是用于抓取、放置和工具使用等操作的最常见末端执行器,依靠简单的开合动作。早期研究侧重于精确的物理模型和预编程[105],在工业自动化等结构化环境中(如具有预定轨迹)或采用视觉伺服[106]进行反馈时效果良好。这些方法在非结构化环境、物体多样性以及复杂交互(如摩擦、变形)中适应性不足。

图 7:DexCap [54] 是一种便携式动作捕捉系统,能够采集人手动作,使机器人能够完成从简单抓取到复杂操作(如Tea preparing)等任务。
基于学习的方法克服了这些限制。在感知方面,PoseCNN [107] 实现了实例级6D位姿估计,而NOCS [108] 推进了类别级估计以实现泛化。功能affordance学习方面,AffordanceNet [109] 通过监督学习识别可操作区域,Where2Act [110] 利用自监督模拟交互。模仿学习方面,神经描述场(NDFs)[111] 增强了策略泛化能力,Diffusion Policy [3] 利用扩散模型处理多模态动作,RT-2 [112] 整合基础模型以解析复杂指令。
任务导向的操纵随着这些进展而扩展。除了基本抓取 [3] 外,机器人通过避碰(例如CollisionNet [113]、PerAct [114])处理杂乱环境,操作可变形和关节式物体 [115]–[118],并执行双臂协调 [49]、灵巧手操作 [54] 和全身控制 [119]。这一演进凸显了基于夹爪的操纵在多样复杂任务中能力的提升。
灵巧手操作。灵巧操纵旨在使机器人能够以复杂、精确的方式与物理世界交互,类似于人手,这是机器人学数十年来的核心挑战 [120]。该领域致力于实现类人般的多功能性和精确性,处理需要精细控制和适应性的任务。
早期灵巧操作研究集中在硬件设计和理论基础。开创性设计如Utah/MIT Hand [121]和Shadow Hand [122]探索了高自由度和仿生结构(例如肌腱驱动机制),而BarrettHand [123]展示了用于自适应抓取的欠驱动设计。同时,Napier对人类抓握模式的分类[124]以及Salisbury和Craig对多指力控制与运动学的分析[125]为后续研究奠定了基础。传统基于模型的控制方法在高维状态空间和复杂接触动力学方面存在困难,限制了其在现实世界中的有效性。基于学习的方法,包括两阶段和端到端方法,此后已成为主流,利用机器学习应对这些挑战。
两阶段方法首先生成抓取位姿,随后控制灵巧手实现这些位姿。关键挑战在于从视觉观测中生成高质量位姿,这通过基于优化[126]-[128]、基于回归[129][130]或基于生成[131]-[140]的策略解决,常与运动规划结合。例如,UGG [136] 使用扩散模型统一位姿与物体几何生成,而SpringGrasp [141] 则通过建模部分观测中的不确定性来提升位姿质量。尽管这些方法得益于解耦的感知与控制以及仿真数据,但由于缺乏闭环反馈,仍对干扰和标定误差敏感。
端到端方法直接通过强化学习或模仿学习建模抓取轨迹。强化学习在仿真中训练策略以实现现实世界迁移[142]–[144],例如DexVIP[145]和GRAFF[146]将视觉affordance线索与强化学习相结合。DextrAH-G[147]和DextrAH-RGB[148]通过大规模仿真实现现实世界泛化,但sim-to-real差距和样本效率问题仍具挑战性。由人类演示驱动的模仿学习[54][146][149]在复杂任务中表现优异,但泛化能力不足。创新方法如SparseDFF[150]和Neural Attention Field[151]通过三维特征场提升泛化能力,而DexGraspVLA[152]采用视觉-语言-动作框架:结合预训练的视觉-语言模型与基于扩散的动作控制器。在零样本设置下,其在1,287种未见过的对象、光照和背景组合中达到90.8%的成功率。
3.3.2 双臂操作任务
双臂操作是指机器人需要协调使用双臂完成的任务,使机器人能够执行诸如协同运输、精密装配以及处理柔性或可变形物体等复杂操作[155]。与单臂操作相比,这些双臂任务面临更大的挑战,包括高维状态-动作空间、臂间及环境碰撞的潜在风险,以及有效双臂协调和动态角色分配的必要性。
早期研究通过引入归纳偏差或结构分解来简化学习与控制,从而应对这些挑战。例如,BUDS [156] 将双臂操作任务分解为稳定器和执行器两种功能角色,这不仅降低了双臂动作空间的复杂性,还促进了双臂间的有效协作。该框架在切菜、拉拉链和盖标记笔帽等任务中表现出稳健的性能。同时,SIMPLe [157] 利用图高斯过程(GGP)表征双臂操作中的运动基元,确保轨迹稳定性,并借助运动学反馈从单臂演示中学习双臂协调。

图8:(1)ALOHA系列[49,153]是一款低成本开源硬件系统,支持细粒度、复杂及长时程移动双臂操作任务的学习,例如slot battery和cooking shrimp,为后续研究奠定机器人平台基础。(2)RoboTwin 2.0[154]通过模拟器生成模拟数据增强双臂操作能力,提供50个双臂任务、731种不同物体和5种实体,全面支持研究与开发。
随着大规模数据收集和模仿学习的进步,端到端方法在双臂操作研究中日益突出。ALOHA系列[49][153][158]通过利用现成硬件和定制3D打印组件,高效收集用于高精度双臂操作的多样化、大规模演示数据,体现了这一趋势。这些数据集促进了具有强大泛化能力的端到端神经网络的训练。特别是,ACT [49]将动作分块与条件变分自编码器(CVAE)框架结合,使机器人能够从仅10分钟的演示数据中学习有效策略,并在电池插入和杯盖开启等具有挑战性的任务中实现高成功率。在此基础上,Mobile ALOHA [153]引入移动底盘并进一步简化ACT流程,实现移动双臂任务的高效完成。此外,RDT-1B [50]提出基于扩散DiT架构的双臂操作基础模型,统一异构多机器人系统的动作表征。该方法通过零样本泛化到新任务和平台,解决了数据稀缺问题。
尽管这些研究显著推动了双臂操作领域的发展,但其重点主要集中在配备平行夹爪的系统上。相比之下,灵巧手的双臂操作带来了额外的挑战,特别是在精细协调和高维控制方面。最近,几项研究 [140], [159], [160] 探索了基于RL的方法,将人类双臂操作技能迁移到灵巧手上,从而实现更复杂的操作能力。

图9:江云帆等[119]提出的BRS使人形机器人能够执行需要Whole-Body Manipulation Control的多种复杂家务,例如清洁马桶、倒垃圾和整理架子。
总结来说,双臂操作研究已从依赖任务特定的强先验和结构简化的方法,发展为利用大规模演示的数据驱动端到端框架。这些进展显著提升了双臂机器人系统的鲁棒性、通用性和多功能性,使其能够处理日益多样化的复杂操作任务。此外,旨在将这些方法适配到灵巧手的持续研究正在扩展双臂操作的能力,使机器人能够执行越来越复杂且类人的任务。
3.3.3 全身操作控制
全身操作是指人形机器人利用全身(包括双臂[155]、躯干[161]、轮式或腿式底盘[162]及其他部件[163])与物体交互并操作的能力。
近年来,人形机器人基于学习的全身操控技术取得了显著进展,聚焦于提升机器人在复杂环境中的自主性、适应性和交互能力。趋势之一是利用大型预训练模型(如LLMs、VLMs和生成模型)来增强语义理解和泛化能力。例如,TidyBot [164] 利用LLMs的归纳能力,从少量示例中学习个性化的家庭整理偏好。MOO [165] 通过VLMs将语言指令中的物体描述映射到视觉观测,实现对未见过的物体类别的零样本操作泛化。HAR-MON [166] 结合人类运动生成先验与VLM编辑技术,基于自然语言生成多样且富有表现力的人形机器人动作。
视觉演示同样指导操作技能的学习。OKAMI [167] 提出了一种物体感知重定向方法,使人形机器人能够从单一的人体RGB-D视频中模仿技能,并适应不同的物体布局。iDP3 [168] 通过改进的3D扩散策略,实现了从单场景遥操作数据训练的多场景任务执行策略。为实现稳健灵活的全身控制,OmniH2O [96] 采用强化学习Sim-to-Real方法,训练协调运动与操作的全身控制策略,并设计了一个与VR遥操作和自主智能体兼容的通用运动学接口。
HumanPlus [6] 系统将基于Transformer的底层控制策略与视觉模仿策略相结合,使仅需单目RGB相机的人形机器人能够进行全身动作示范并自主学习复杂技能。该系统能够在现实世界中学习全身操作和运动技能,例如穿鞋、站立和行走。WB-VIMA [119] 通过自回归动作去噪建模全身动作的层次结构及特定人形机器人形态中组件间的相互依赖关系,预测协调的全身动作,有效学习全身操作以完成具有挑战性的现实世界家庭任务。
3.3.4 人形机器人操作中的基础模型
基础模型(FMs)是指在海量互联网数据上预训练的大规模模型,包括大型语言模型(LLMs)、视觉模型(VMs)和视觉-语言模型(VLMs)。凭借其在语义理解、世界知识整合、逻辑推理、任务规划和跨模态表征方面的强大能力,这些模型可直接部署或微调以应用于广泛的下游任务。
Foundation Models使人形机器人能够在复杂、动态和非结构化环境中执行操作任务,通常涉及复杂的环境感知与建模、抽象任务理解以及长序列和多步骤任务的自主规划。图10展示了利用foundation models驱动人形机器人操作的两种主要技术范式。
层次化方法利用预训练的语言或视觉-语言基础模型作为高级任务规划与推理引擎,以理解用户指令、解析场景信息并将复杂任务分解为子目标序列。这些高级输出(通常是可操作的知识或image-language tokens)随后传递给底层动作策略(通常为通过模仿学习或强化学习训练的专家策略),以执行物理交互动作。Transformer已成为此类底层策略的常见选择,因其可扩展性。
该分层架构利用基础模型强大的语义和逻辑推理能力,同时结合底层策略在特定动作执行中的高效性,使机器人在多任务处理和跨场景泛化方面表现出色[169]–[173]。该方法的优势在于模块化和可解释性,但也面临高层与底层之间的信息瓶颈和语义鸿沟等挑战。例如,Figure AI展示了用于灵巧操作和双人形机器人协作的分层VLA模型Helix[174],而NVIDIA开发了通用人形机器人基础模型GR00T N1[175]。π0模型[176]将预训练的视觉-语言模型与流匹配架构相结合,实现对多种机器人平台的通用控制,高效执行洗衣折叠和物体分类等复杂灵巧任务。
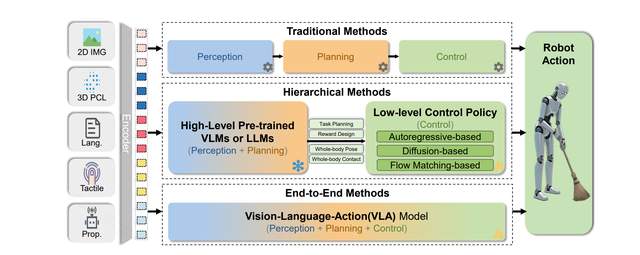
图10:三种常见人形机器人操作框架(传统、分层和端到端)的示意图,展示了输入→动作的数据流及结构差异。
端到端方法直接将机器人操作数据整合到基础模型的训练或微调过程中,构建端到端的视觉-语言-动作(VLA)模型[4]、[68]、[177]、[178]。这些模型直接学习从多模态输入(如图像和语言指令)到机器人动作输出的映射。通过在大量机器人交互数据上进行预训练或微调,VLA模型可以隐式地学习任务规划、场景理解和动作生成,无需显式分层。这种端到端方法允许模型针对下游部署任务进行整体优化,可能实现更优的性能和更快的响应速度,但通常需要大量机器人专用数据,且模型可解释性相对较弱。例如,Google DeepMind的RT(机器人Transformer)系列[112]、[177]是典型的操作VLA模型。
3.4 人机交互(HRI)
人机交互(HRI)专注于使机器人能够理解并响应人类的需求和情感,促进高效协作、陪伴及个性化服务,广泛应用于家庭、医疗保健、教育和娱乐等领域[179]。为了准确理解和适应多样化的人类行为,机器人需要具备类人能力,如多模态感知、自然语言处理和协同控制。
人机交互研究可分为三个主要维度:Cognitive Collaboration、Physical Reliability 和 Social Embeddedness。这些维度分别关注机器人如何感知和理解人类认知模式、协调物理动作以及有效融入人类社会环境。
以机器人在拥挤环境中导航为例,Cognitive Collaboration指机器人识别行人的潜在紧迫性;Physical Reliability通过调整速度和轨迹避免碰撞来体现;Social Embeddedness则通过机器人主动使用语言提示或肢体语言协商通行权、建立临时社交规范来体现。此类综合能力使机器人能够无缝融入日常人类活动,提升交互的自然性与效率。后续章节将详细阐述各维度的理论基础、当前研究进展、主要研究方向及代表性文献。

图11:认知交互分析实现装配任务中的人机有效协作[180]
3.4.1 认知协作:理解与对齐人类认知
在人机交互中,认知协作指机器人与人类之间的双向认知对齐,实现自然直观的交流与合作。这种协作不仅强调机器人对人类行为的被动响应,还强调深度认知理解和动态适应,形成类似人类高效协作的模式。其核心目标是使机器人不仅能理解人类的明确指令(如语音指令和手语指令[181]),还能理解隐含意图(如情绪和上下文),动态调整行为以匹配人类的认知模式和期望[13]。该能力的实现对提升机器人在复杂场景中的适应性及自然交互体验至关重要。
研究表明,实现认知协作依赖于复杂的认知架构和多模态信息处理能力。例如,Lemaignan等人[182]探讨了社会人机交互中机器人认知所需的关键技能,包括几何推理、情境评估和多模态对话。机器人需要通过这些技能理解人类意图并与人类协作完成共同任务[180]。
此外,多模态意图学习已被确定为实现认知协作的关键因素[183]。例如,整合面部表情和肢体动作以解读口头指令的情感基调和潜在意图,可显著减少误解并提升人机交互的自然性[184]。
进一步地,认知协作要求机器人具备对环境和交互情境的深入语义理解。Laplaza等人[185]的研究展示了如何通过人类动作的上下文语义分析来推断交互意图。他们提出了一种基于动态语义分析的模型,可实时解析人类动作的潜在目标并结合环境信息进行预测,从而让机器人更准确地协作完成任务。
在无需直接人类参与的交互任务中,认知协作同样扮演着重要角色。例如,在家用服务机器人场景中,机器人可通过环境语义理解完成目标导向的导航任务。该任务要求机器人在未知环境中定位特定目标物体(如杯子、沙发或电视)或指定区域(如卧室和浴室)。L3mvn [186]、Sg-Nav [187]、Trihelper [188]、CogNav [189] 和 UniGoal [190] 等工作通过利用LLMs模拟多种人类认知状态(如广泛搜索和上下文搜索),提升了机器人在目标导向导航任务中的性能。
总之,人机交互中认知协作的进步需要跨学科合作,包括认知科学、语义理解,以及涉及语言、视觉和音频感知的多模态大模型的开发。随着认知协作能力的不断提升,机器人将更加熟练地支持实际应用场景中的各类任务。
3.4.2 物理可靠性:物理动作的协调与安全
人机交互中的物理可靠性是指人类与机器人之间在力量、时序和距离上的有效协调,以确保安全、高效且人机兼容的任务执行。其核心目标是使机器人能够动态响应人类动作的实时变化,包括调整运动策略、避免物理冲突,并在交互中保障人身安全。为此,研究主要聚焦于两个方向:物理交互中的实时控制和基于仿真平台的大规模生成数据集构建。

图12:物理可靠性通过感知和规划得到确保 [191]
人机交互中的物理可靠性保障依赖于先进的运动规划与控制策略,这些策略需同时处理人与机器人之间的协调与安全问题[192]。基于采样的规划器,如概率路线图(PRM)[193]、快速探索随机树(RRT)[194]及其扩展方法,已被广泛应用于共享工作空间中生成无碰撞且考虑人类因素的轨迹[195-199]。基于优化的规划器,包括CHOMP [200]、STOMP [201]、IT-OMP [202]、TrajOpt [203, 204]和GPMP [205],通过最小化动态场景中可行性和平滑性相关的成本,进一步提升了轨迹质量。这些方法非常适合应用于人机协作环境以确保物理可靠性[206, 207]。
在控制方面,阻抗控制和导纳控制能够对物理接触作出柔顺且安全的响应,而自适应控制器和混合控制器则进一步增强了对干扰和不确定性的鲁棒性 [208]–[211]。这些方法确保机器人可靠且可预测地运行,从而降低人类合作者受伤和不适的风险。
然而,随着机器人在多样且非结构化环境中的部署日益增多,实现安全稳健的物理协作仅靠传统控制策略已不足。感知、意图预测与实时适应的融合已成为机器人应对动态变化和复杂人类行为的关键 [212], [213]。基于这些进展,近期研究探索了模仿学习和强化学习方法,使机器人能够直接从数据和经验中习得自适应运动策略 [214]–[216]。然而,这些学习方法的有效性高度依赖于高质量交互数据的可用性。
因此,通过物理仿真生成的大规模生成式数据集已成为提升机器人动作可靠性和安全性的重要资源。例如,Handover-14 Sim [217] 提供了一个用于人机物体传递的仿真与基准测试平台,利用物理引擎和轨迹优化来确保无碰撞及标准化的安全评估。在此基础上,GenH2R [218] 引入了包含大量3D模型和灵巧抓取生成的仿真环境,通过模仿学习训练通用的传递策略。此外,MobileH2R [191] 整合了由CHOMP [200] 生成的专家演示,以应对动态场景中移动机器人安全高效物体传递的挑战。
尽管当前研究已取得显著进展,但确保HRI中的物理可靠性仍面临高计算成本和复杂场景下鲁棒性有限等挑战。未来需要进一步探索以开发更高效的算法并提升适应性,从而在多样且动态的环境中实现可靠的HRI。
3.4.3 社会嵌入性:与社会规则和文化规范的整合
人机交互中的社会嵌入性指机器人能够识别并适应社会规范、文化期望和群体动态,从而无缝融入人类环境的能力。这不仅限于任务完成,还包括协商、礼仪和情感表达等行为。如图13所示,机器人正与人类伙伴进行协商。为促进机器人无缝融入社交场景,近期研究探索了多种策略,这些策略同时关注社会空间理解和行为理解。这两个互补方面是实现人机交互中有效社会嵌入性的关键。
一方面,社交空间理解使机器人能够理解和适应人类群体的空间动态。通过在社交场景中应用空间理解,机器人能够借助近体空间[219]、[220]等概念更好地解读协作或防御行为。典型应用是使机器人在社交环境中更有效地导航和互动,从而为视障人士提供更合适、自然的协助[221]–[223]。
另一方面,行为理解侧重于从语言和非语言角度解码人类交流的复杂性。语言学研究探讨对话建模、会话结构和话语分析等方面[224]–[228],而非语言研究则侧重于手势、眼神和情感表达的解读[229]、[230]。为捕捉这些多样的社交信号,已提出多种方法用于建模和识别非语言行为,涵盖从个体手势分析到多方现实世界互动的范围[231]–[236]。
尽管取得了这些进展,稳健的社会嵌入性仍面临挑战。机器人必须在任务效率与社会适宜性之间准确平衡,这需要提升多模态感知、长期适应能力以及将社会知识融入决策的能力。未来研究还应关注终身学习、跨文化适应以及社会嵌入式机器人的伦理问题,为IR-L4自主性铺平道路。

图13:机器人通过可穿戴触觉界面向人类传达其意图的社交导航场景[237]