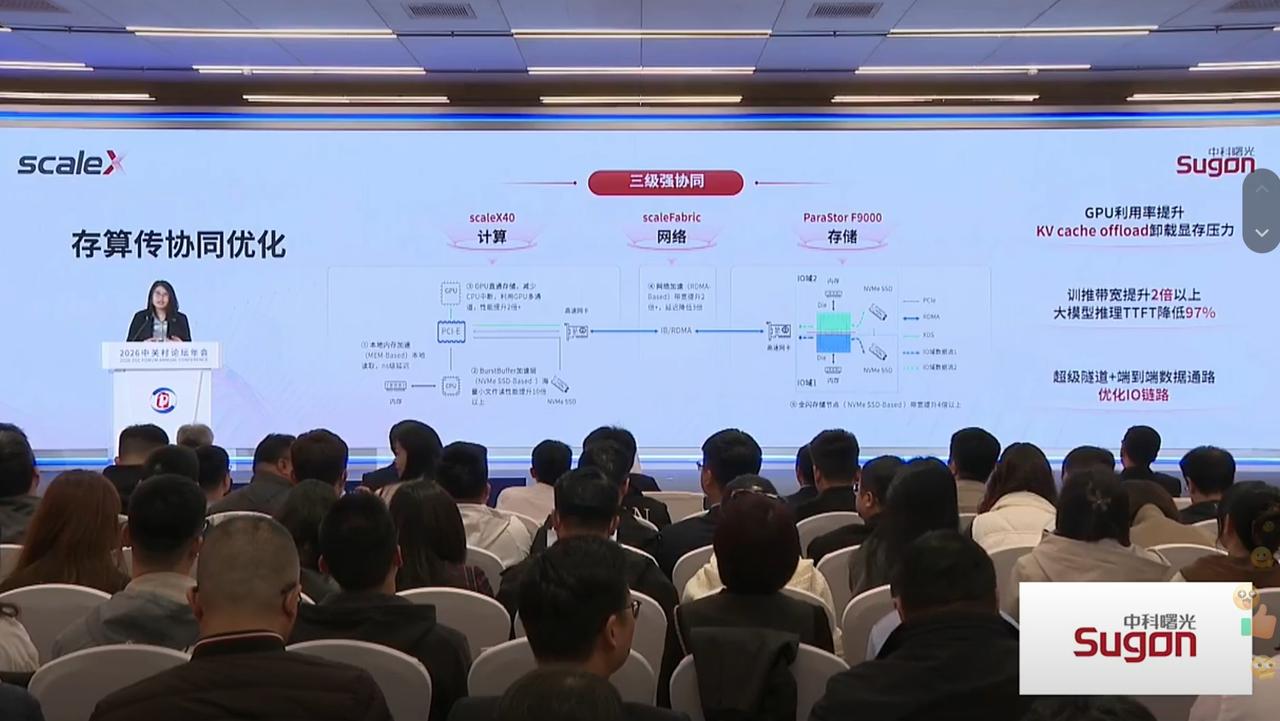
从曙光scaleX40发布,看Token时代的算力普惠! 刚刚,曙光发布scaleX40超节点,打出“让超节点成为中国算力标配”口号。这背后折射出的,是AI基础设施领域一个正在发生的转变:超节点正从头部大厂的“专属玩具”,走向千行百业的“通用工具”。 这条路并不平坦。从scaleX40的产品逻辑中,我们可以透视出超节点真正走向普惠,必须跨越的三重门槛。 (1)算力普惠的前提,是全栈协同能力,而非单一硬件性能。 过去两年,行业陷入“算力不足恐惧症”,厂商纷纷堆卡、堆带宽、堆显存。但用户的实际痛点往往不在单点性能,而在系统瓶颈:存储带宽不足导致GPU利用率普遍低于50%,网络抖动让训练任务频繁中断,运维复杂度让中小企业望而却步。 曙光此次将ParaStor存储和SothisAI管理平台与scaleX40进行架构上深度耦合,本质上是在回应一个现实:超节点要“用得好”,必须算、存、传、管全栈协同。这是一个行业共识正在形成的信号。 (2)超节点规格正在从“越大越好”转向“场景适配”。 当基础大模型训练被少数头部玩家垄断后,绝大多数企业的需求其实是模型微调、行业适配、大规模推理,这类场景对算力的需求恰恰落在几十卡的“甜点区间”。 40卡之所以成为多家厂商的共识规格,是因为它处于一级互连技术的效能边界内,同时兼顾了性能、成本、运维复杂度和机房兼容性。 (3)普惠的本质是TCO的颠覆,而非硬件价格的降低。 超节点“买不起”的痛点,核心是配套成本:定制机柜、特殊供电、复杂布线、专业运维团队,而非单卡价格。scaleX40“无线缆箱式”设计、兼容标准19英寸机柜、分钟级维护,都是在整体降低超节点的使用门槛和持有成本。 超节点的“普惠化”浪潮已启动,目前已经有先头兵跨过了这三重门槛,接下来就看市场买不买账了。