DC娱乐网
deephub的文章
Prompt Engineering 的本质:角色、任务、上下文、格式、约束
2026-06-01 22:12
deephub
Prompt Engineering 的本质:角色、任务、上下文、格式、约束
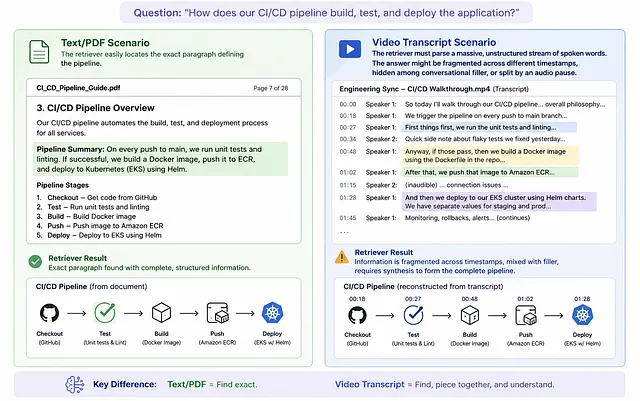
视频 RAG 中分块策略:基于停顿、滑动窗口与基于 LLM 的方法
2026-05-31 21:46
deephub
视频 RAG 中分块策略:基于停顿、滑动窗口与基于 LLM 的方法
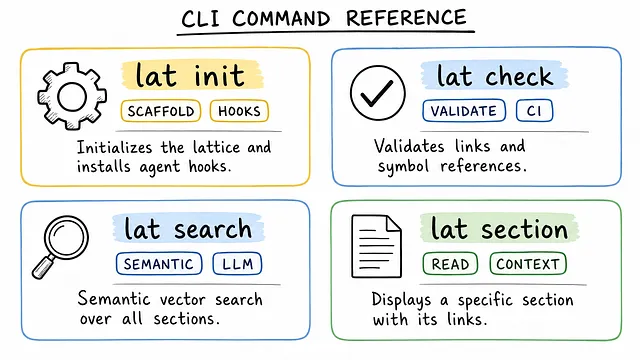
lat.md:将任意项目代码转换为可查询的知识图谱
2026-05-29 22:04
deephub
lat.md:将任意项目代码转换为可查询的知识图谱
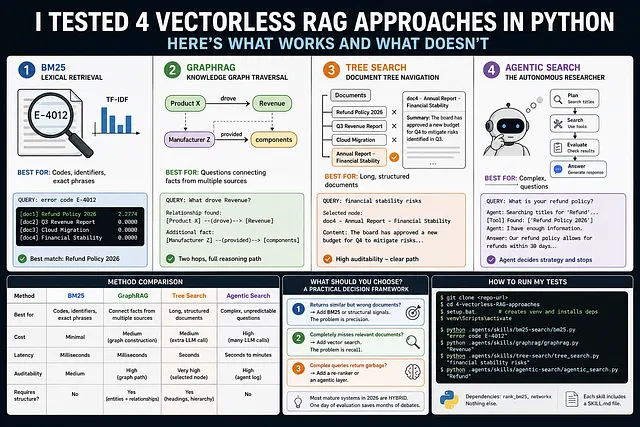
四种无向量RAG 方案实测: BM25、GraphRAG、Tree Search、Agent
2026-05-27 21:45
deephub
四种无向量RAG 方案实测: BM25、GraphRAG、Tree Search、Agent
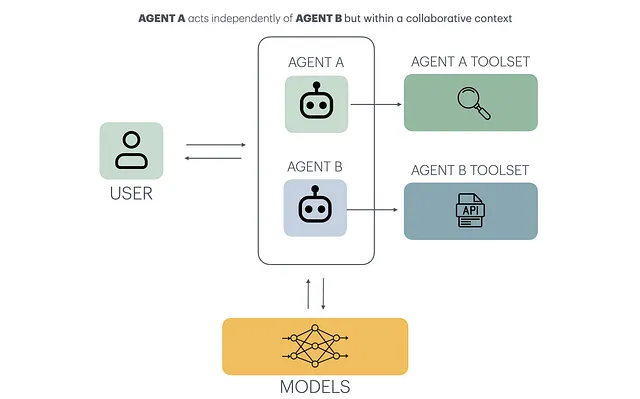
Agentic 设计模式拆解:6 种结构的优缺点与应用场景
2026-05-26 21:53
deephub
Agentic 设计模式拆解:6 种结构的优缺点与应用场景
推理 、 行动、 观察:用 LangChain和Python 实现一个智能体循环
2026-05-23 20:45
deephub
推理 、 行动、 观察:用 LangChain和Python 实现一个智能体循环
TraceML:用三行代码为训练循环加入 step 级诊断
2026-05-21 22:00
deephub
TraceML:用三行代码为训练循环加入 step 级诊断
告别脆弱的单体应用,用多智能体网络构建稳定的生产力工具
2026-05-20 21:41
deephub
告别脆弱的单体应用,用多智能体网络构建稳定的生产力工具
2026 年面向 LLM 的 RL方法总结:从 PPO 到 DPO 到 GRPO,再到多智能体 R...
2026-05-19 21:46
deephub
2026 年面向 LLM 的 RL方法总结:从 PPO 到 DPO 到 GRPO,再到多智能体 RL
构建一个可自我改进的多 Agent RAG 系统:架构、评估,以及带人工审核的 Prompt 反馈闭...
2026-05-18 21:34
deephub
构建一个可自我改进的多 Agent RAG 系统:架构、评估,以及带人工审核的 Prompt 反馈闭环
Agent = Model + Harness:模型决定上限Harness 决定下限
2026-05-17 23:01
deephub
Agent = Model + Harness:模型决定上限Harness 决定下限
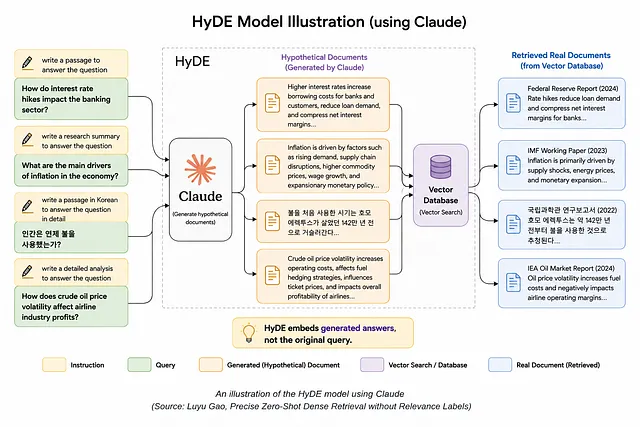
HyDE :让 RAG 检索从"匹配关键词"升级到"理解意图"
2026-05-14 22:13
deephub
HyDE :让 RAG 检索从"匹配关键词"升级到"理解意图"
让机器学习 Pipeline 更稳的 5 个 Python 装饰器代码
2026-05-13 21:00
deephub
让机器学习 Pipeline 更稳的 5 个 Python 装饰器代码
Feature Engineering 实战:Pandas + Scikit-learn的机器学习特...
2026-05-12 22:08
deephub
Feature Engineering 实战:Pandas + Scikit-learn的机器学习特征工程的完整代码示例
2026 RAG 选型指南:Vector、Graph、Vectorless 该怎么挑
2026-05-11 21:02
deephub
2026 RAG 选型指南:Vector、Graph、Vectorless 该怎么挑
第一页
作者信息
deephub
提供专业的人工智能知识,包括CV NLP 数据挖掘等
分类: 科技
热门分类
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量