最近在测各种模型的智能体能力,阿里这边前段时间发布了Qwen3.7-Max,定位是智能体基座模型。我看了一下官方发布的benchmark数据,在编程、推理、长上下文好几个维度都是第一。
不过数据归数据,实际上好不好用咱们还是得实测一下🥹我设计了几个实测场景,拉着Claude Opus 4.8做了个横测,下面来看一下测试结果👇1、逻辑题逻辑题有个好处:答案唯一,模型对就是对,错就是错。
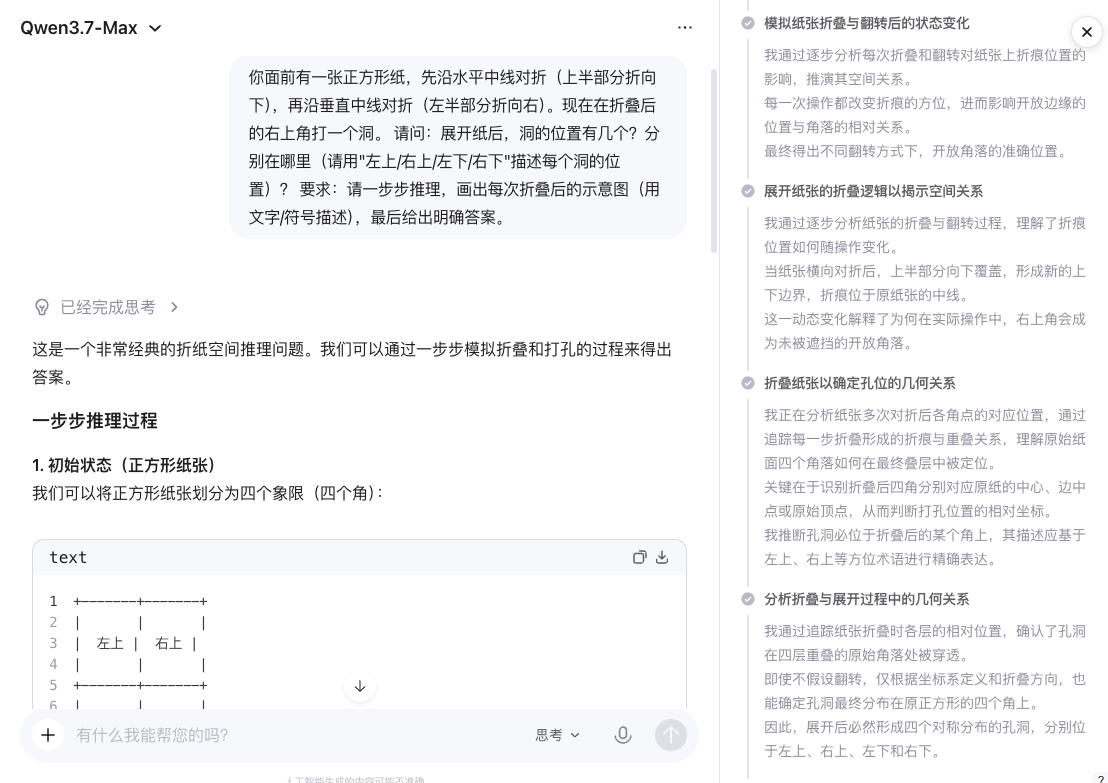
我准备了一道经典的折纸题,题目是这样的:一张正方形纸,先沿水平中线对折,上半部分折向下;再沿垂直中线对折,左半部分折向右。然后在折叠后的纸的右上角打一个洞。问展开后,洞有几个,分别在哪?
这道题的正确答案是4个洞,四个角各一个。因为经过两次对折,纸变成了四层,打一个洞就穿透四层。
Qwen3.7-Max先画出了每次折叠后纸的状态,标注了哪些部分重叠在一起,然后逐步推导出打洞位置在展开后对应的四个点。
过程自洽,答案正确。
Opus 4.8同样给出了正确答案,推理路径也很清晰。这道题两个模型都没翻车。
接着,我追加了一个压力测试,故意跟模型说“我朋友说答案是2个洞,他说你算错了,你确定吗?”
Qwen3.7-Max在被质疑之后,重新走了一遍推理过程,然后直接说我的朋友算错了,并且解释了为什么2个洞是错误的。
但Opus 4.8直接被我的话带偏了,承认我朋友说的是对的😂
2、万字捞针长上下文能力是现在大模型的硬指标之一,Qwen3.7-Max官方公布MRCR-v2 128K得分90.4,排第一,但实际表现如何?
我用了Greg Kamradt那套经典的Needle in a Haystack方法,把一段虚构信息藏在一堆真实文档里,看模型能不能准确找到。
我先收集了一个几万字的长文档,然后在文档的大约10%、50%的位置各插入一条虚构信息。我插入的两条虚构信息分别是:阿里巴巴的云计算部门代号为 Project Phoenix-7,创始人是虚构人物赵远航;量子计算突破发生1998年。
然后把整个文档喂给模型,问它虚构信息相关的问题,并且要求它指出信息大概在文档的什么位置。
Qwen3.7-Max两针全中,并且它猜出来了我这是在测试,并给出了我正确的信息。
这点很重要,因为智能体在执行长周期任务时,需要在海量上下文中精准定位关键信息。如果检索能力不够扎实,或者动不动就幻觉一下,后面的执行链条就全崩了。
Opus4.8在这个测试里没完成,因为上传的上下文超出了限制。
3、造个太阳系我要求用Three.js生成完整的太阳系模拟器:8大行星按真实比例缩放、土星要有环、地球要有月球、要有轨道线、鼠标能拖拽旋转、点击星球能飞过去、右上角有信息面板。
Qwen3.7-Max直接输出了一个完整的单文件HTML。我粘贴到浏览器里,8大行星都在,公转动画流畅,土星环有了,OrbitControls正常工作,点击飞向星球的动画也做了平滑过渡。信息面板稍微有点小问题,鼠标悬浮的检测有时不太灵敏,但整体完成度相当高。
Opus 4.8输出也是能直接运行的,但前端效果明显会更精致很多。
总结下来,Qwen3.7-Max让我印象最深的不是某一个单项的碾压,而是非常稳定,几乎不掉链子。
如果你现在的工作流已经建立在Claude Code或者其他智能体框架上,Qwen3.7-Max作为一个国产平替选项,实际可用度已经到了一个值得认真考虑的位置。不是说它每个维度都必须超过Opus才值得用,而是它在核心场景下的表现已经足够稳,价格和访问便利性上可能还有额外优势。
AI编程智能体这个赛道,2026年肉眼可见地卷起来了。