当下大模型行业习惯以通用榜单评判实力,可重复使用题库催生榜单高分注水乱象乱象,榜单分数难以代表真实场景表现。每年全新命题、评价体系完备的高考,成为检验大模型真实能力的优质试金石。2026年高考季,新京报、南方产业智库、观察者网、羊城晚报多家机构相继开展AI高考盲评,讯飞星火在多轮包含国内外多款主流模型的测评中持续领跑,展现出独有的综合优势。
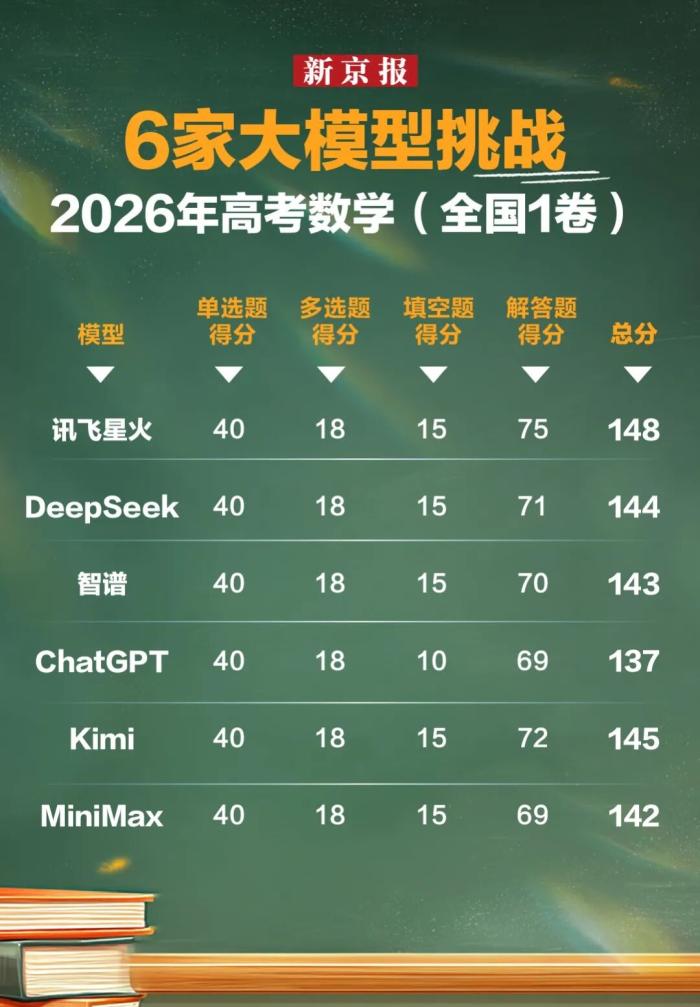
新京报组织讯飞星火、DeepSeek、智谱、ChatGPT、Kimi、MiniMax六款模型测试新高考I卷数学,客观题各家得分相近,区分度集中在解答推理环节。最终讯飞星火拿下148分位居第一,解题步骤完整规范,几何、数形结合题型拆解逻辑清晰,其余模型普遍存在推导断层、使用超纲解法等失分问题。
观察者网针对英语新课标I卷应用文开展盲评,参赛模型包含GPT、通义千问、Kimi、豆包、Claude等,不少模型频繁出现词性错误。讯飞星火与GPT-5.5、通义千问共同跻身第一梯队,写作要点完整、用词规范,严格贴合高中英语写作要求。
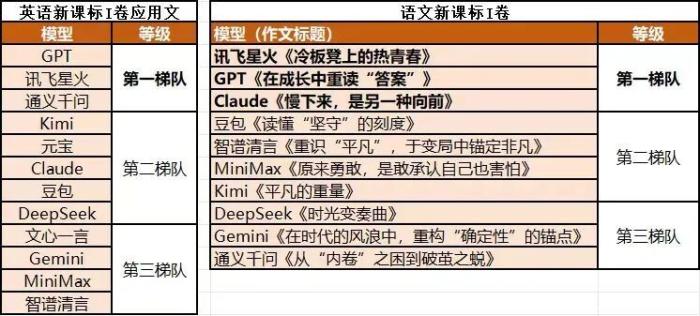
南方产业智库召集千问、豆包、DeepSeek、讯飞星火等九款模型测评全国I卷语文作文,多数模型作文存在素材雷同、立意空洞的通病。讯飞星火作文平均分55.5分排名首位,文章思辨性突出,兼具个人成长视角与时代立意,逻辑完整摆脱模板化弊端。
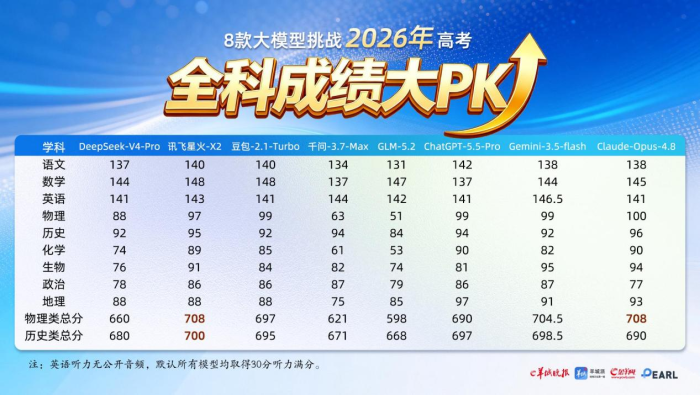
羊城晚报选取DeepSeek、豆包、GPT、Gemini、Claude等八款模型进行广东高考全科测评,覆盖语数英与各类选考科目。讯飞星火物理类总分708分,和Claude并列第一;历史类700分,是唯一达到屏蔽生标准的模型,各科发挥均衡稳定,无明显短板。
多项测评的亮眼成绩,源于科大讯飞技术与教育场景积淀的双重加持。今年2月发布的星火X2依托全国产算力,升级数学推理、多语言处理等核心能力。二十余年深耕教育领域,科大讯飞积累海量中小学课堂、阅卷真实数据,让模型吃透考试评分细则,作答不只追求答案正确,更贴合阅卷标准。
行业竞争早已脱离单纯算力、参数比拼,落地真实场景、读懂场景规则才是核心竞争力。高考兼具客观标准答案与开放性创作,全方位考验模型综合能力。讯飞星火凭借深厚教育场景积累,在单科专项、全科综合测评中稳定发挥,能够化身全天候AI助教,实现精准答疑、因材施教,用技术赋能个性化学习。
#大模型国家队##全栈自主可控##语音及语言信息处理国家工程研究中心#