1. 导读
在恶劣环境中捕获的图像通常表现出模糊的细节、降低的对比度和颜色失真,这阻碍了特征检测和匹配,从而影响了单应性估计的准确性和鲁棒性。虽然视觉增强可以提高对比度和清晰度,但它可能会引入视觉容许的伪像,模糊图像的结构完整性。考虑到语义信息对环境干扰的弹性,我们提出了一个语义驱动的特征增强网络用于鲁棒的单应性估计,称为SeFENet。具体而言,我们首先引入一种创新的分层尺度感知模块,通过聚合多尺度信息来扩展感受野,从而在各种恶劣条件下有效提取图像特征。随后,我们提出了一个语义引导的约束模块,结合一个高级感知框架来实现语义特征的降级容忍。引入了基于元学习的训练策略来缓解语义和结构特征之间的差异。通过内外交替优化,该网络实现了隐式语义特征增强,从而通过加强局部特征理解和上下文信息提取来提高单应性估计在不利环境中的鲁棒性。在正常和恶劣条件下的实验结果表明,SeFENet明显优于SOTA方法,在大规模数据集上将点匹配误差降低了至少41%。
2. 引言
单应性(Homography)是一种全局投影变换,能够将从不同视角捕获的图像中的点转换到另一图像中的对应点。它在计算机视觉领域有着广泛的应用,涵盖从单目相机系统到多相机系统。这些应用包括图像和视频拼接、多尺度千兆像素摄影、多光谱图像融合、平面物体跟踪、同步定位与地图构建(SLAM)以及无GPS环境下无人机定位。
在深度单应性估计领域,开创性方法利用VGG风格的网络来估计拼接图像对之间的单应性。在此基础上,后续研究通过修改网络架构或级联多个相似网络来提高准确性,从而实现了改进。HomoGAN生成了一个具有明确共面性约束的主导平面掩码,以引导单应性估计聚焦于主导平面,从而显著降低了误差。CAHomo在估计过程中学习了一个内容感知掩码,用于剔除异常值,并采用三重损失进行无监督训练。此外,像MCNet这样的工作旨在通过结合迭代相关搜索和多尺度策略来实现有效迭代。与上述侧重于结构特征的工作不同,MaskHomo引入了一种单应性估计框架,该框架利用语义信息有效解决了与多平面深度差异相关的问题。尽管上述方法在正常条件下通常表现良好,但在恶劣环境(如雨天、雾天和低光环境)下,其准确性会显著下降。这些恶劣条件会导致图像细节模糊、信息丢失和对比度降低,从而限制了传统基于结构特征的方法在特征有效提取和匹配方面的应用,尤其是在大基线条件下,这进一步带来了不可避免的干扰。虽然一些工作通过添加低光图像来丰富训练,但它们没有解决网络结构和训练方法中的图像退化问题,从而限制了它们在挑战性条件下的性能。
在本文中,我们提出了一种名为SeFENet的方法,该方法通过语义驱动模块中的语义特征来增强结构特征,以实现在恶劣环境下的鲁棒单应性估计。与结构信息不同,语义特征捕获高级信息,以强调物体的细节并忽略由恶劣条件引起的背景干扰。因此,我们利用为高级感知任务设计的模块来指导所提出的网络从退化图像中提取有效的语义特征,从而实现鲁棒估计。此外,由于语义特征和结构特征之间存在较大差异,我们引入了一个通过元学习策略优化的语义引导元约束模块来缩小特征差距,确保它们共同提高模型的有效性。同时,考虑到现有方法在捕获恶劣环境中图像信息方面的局限性,我们引入了一个分层尺度感知机制来增加感受野,从而关注更多的上下文信息并理解图像中物体的关系。
3. 效果展示
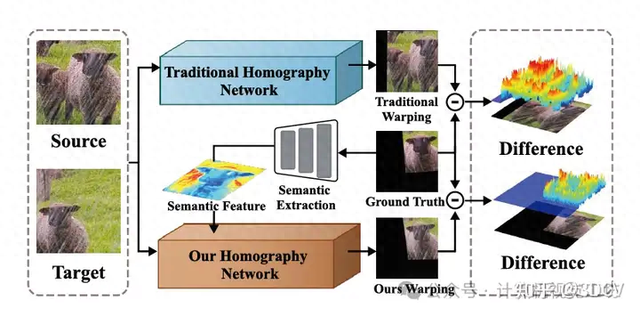
本文概念图如上图。上半部分是其他单应性估计方法,下半部分是我们的单应性估计方法。整合语义后,从三维地形图可以看出,在恶劣环境下,我们的单应性估计的失真图像比其他方法更接近源图像。
这4个图分别表示我们的单应性估计方法在4种环境中对VOC数据集的评估:正常、弱光、霾和雨。x轴代表平均转折误差(ACE),y轴代表相应ACE下的数据百分比。

4. 主要贡献
我们的贡献如下:
• 我们提出了SeFENet方法,该方法通过高级感知任务的指导隐式地增强语义特征,从而在恶劣环境和大基线条件下实现鲁棒的单应性估计。
• 提出了一种语义引导元约束,用于协调语义特征和结构特征,防止由两个不同级别任务之间的差距引起的负面干扰。
• 我们引入了一个分层尺度感知特征提取模块。通过增加特征提取的感受野,该模块使模型能够更好地理解图像场景中的上下文信息,同时过滤掉不相关的背景噪声。推荐课程:。
• 通过实验,SeFENet在合成数据集和真实数据集上均表现出在恶劣环境下进行单应性估计的优越性能。
5. 方法
SeFENet网络的结构如图2所示,包含三个模块:目标感知单应性估计模块(TAHEM)、语义提取模块(SEM)和语义引导元约束(SMC)。首先,我们将源图像Is和目标图像It输入到预训练的TAHEM中,以获得单应性矩阵。TAHEM中嵌入了分层尺度感知模块,以扩展特征提取的感受野,从而提高网络在恶劣环境下的鲁棒性。然后,我们将真实地面图像Igt(即Is和It的重叠区域)输入到SEM中,以获得语义特征。之后,我们将此特征和TAHEM的中间特征输入到SMC中,通过交替优化的元学习策略隐式地增强所提出的单应性估计网络提取语义特征的能力,从而实现退化环境的单应性估计。

6. 实验结果
为了验证我们的方法在实际环境中的鲁棒性,我们基于CAHomo数据集,使用了一个经过改进的基准数据集进行测试。我们采用了与VOC数据集测试相同的对比方法。使用PME来评估单应性估计结果,而PSNR、SSIM和NCC则用于评估生成图像的质量。实验结果如表1所示,该表表明传统的特征点提取方法往往不稳定,导致糟糕的结果。除了基于LoFTR的特征点提取方法外,在自然条件下,传统方法生成的图像的PME远低于恶劣环境下的PME。大多数深度学习方法在处理具有大基线的图像时表现出更好的鲁棒性。然而,我们的方法在普通和恶劣环境中均展现出明显的优势。与排名第二的MCNet的PME相比,我们的模型在四种情况下分别将PME降低了55.5%、54.8%、41.7%和49.6%。此外,我们的方法在PSNR、SSIM和NCC方面也表现良好。由于恶劣环境下特征点提取的挑战,传统图像生成方法往往产生较差的结果,导致在某些条件下,某些方法的PSNR、SSIM和NCC值相同。虽然我们的方法在雨天情况下的SSIM仅落后于ORB+MAGSAC和ORB+RANSAC,但在所有条件下的其他所有指标中均排名第一,且相比排名第二的指标至少有3%的提升。

在图7中,我们可视化了每种方法在大基线CAHomo数据集上四个不同环境下的单应性估计结果。从图7中可以看出,与基于传统特征点的方法相比,基于深度学习的方法(LoFTR+RANSAC除外)表现出更强的鲁棒性。然而,在恶劣环境中,某些情况仍会在关键区域出现严重的阴影或显著的畸变偏差。相比之下,我们的方法有效减轻了边缘的阴影和畸变,使得生成的畸变目标图像与源图像高度相似。

7. 总结
本文介绍了一种名为SeFENet的网络,该网络通过整合语义特征来增强恶劣环境下的单应性估计。与以往仅依赖结构特征的方法不同,SeFENet使用预训练的语义提取模块(SEM)来捕获在恶劣条件下拍摄的图像中的语义特征。这些语义特征在尺度匹配模块(SMC)中与相应尺度的结构特征进行融合,从而在变换感知同态估计(TAHEM)中提高了性能。实验结果表明,我们的方法在合成和真实世界的恶劣环境数据集上均实现了鲁棒且高精度的单应性估计。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~

