导读 随着大数据的进一步发展,生成式推荐广告召回越来越重要。今天嵇智老师会和大家分享下百度在生成式推荐广告召回方面的技术和应用。嵇智老师在百度担任信息流广告召回方向的负责人,他曾获得过百度的最高奖项。今天嵇智老师分享的题目是百度生成式推荐广告召回。其中核心工作 COBRA 已被 NeurIPS 2025 接收。
今天的介绍会围绕下面十点展开:
1. 生成式推荐广告召回背景介绍
2. 第一阶段:Dense 表征压缩以及生成式对比学习建模
3. 第二阶段:Sparse 量化表征及 Sparse ID 生成核心突破
4. 思考:Review 建模范式
5. 第三阶段:Sparse、Dense 级联表征及生成度量一体化(COBRA)
6. 核心突破:Coarse-to-Fine 推理
7. 核心突破:生成度量一体化效果分析
8. 释放生成式潜力:长序列拓展,在线推理
9. 未来规划
10. Q&A
分享嘉宾|嵇智 百度 资深算法工程师
编辑整理|Yuxiao
内容校对|郭慧敏
出品社区|DataFun
01
生成式推荐广告召回背景介绍

1. 背景介绍
常见的检索系统都是级联的漏斗结构。召回作为整个检索系统的入口,决定了下游系统的吞吐能力,因此召回精度的大幅提升是实现漏斗提效或扁平化的关键。然而传统的双塔、图等模型 Scaling Law 已进入饱和区,粗暴地提升参数规模并不能带来效率的提升。同时,另一方面,行为序列是用户沉淀在系统中的重要资产,而 Transformer 对序列有高效的建模能力。所以生成式与行为序列的结合是大有可为的。
2. 方案
传统的用户行为序列,如上图右侧所示,由用户历史交互过的 item 构造而成。以广告 item 为例,每个 item 包含客户的行业、公司名称、标题、推广点、落地页信息以及图片或视频等多模信息,是一个综合体。而我们的任务是利用生成式的范式,高效建模序列关系,从而生成用户下一个感兴趣的 item。在早期,尝试了直接用 LLM 去做该任务,但遇到了一些问题:
第一是超长文本序列带来的性能压力。举个例子,一个用户序列可能有 30 个 item,每个 item 包含 300 个 token,则该序列就有 9000 个 token,现实情况可能远不止如此,这对于生产环境来说,性能压力是很大的。
第二是信息损失。在采用短文本表示的情况下,例如用某某游戏、某某小说的名称来描述 item 信息,信息损失严重。
因此,为满足信息完备、性能约束和高效序列关系建模,有两个核心工作:
核心一:item 表征优化,作为序列的基本组成单元,item 如何 token 是核心工作之一;
核心二:序列建模,不同的表征对应不同的序列建模设计;
围绕这两个核心,团队展开了三个阶段的工作。
02
第一阶段:Dense 表征压缩以及生成式对比学习建模

第一个阶段是 Dense 表征压缩以及生成式对比学习建模。
1. Item Dense 表征
整个框架如上图左侧所示,首先,在底层进行对 item 表征,通过最原始的信息完整表述 item,包括行业、标题、多模信息等,并引入 Transformer Encoder 框架,对整个 item 进行编码,并在最前面插入 [cls] special token,[cls] 与所有 token 都有交互,将其作为 item 的表征。这样,整个 item 序列也变成了一个 embedding 序列。
2. 生成式对比学习序列建模
在建模过程中,将 embedding 序列输入到 causal decoder 中,通过 next item prediction 的方式,即下一个 item 作为 positive 样本,在 batch 内负采样,构建对比学习的 loss,完成整个序列的学习。同时,将 decoder 和 encoder 进行联合训练,兼顾序列中的语义和协同关系。
整个过程中还有一些细节需要注意。例如,对于 time embedding,在 NLP 中,每个 token 之间的间隔是固定的。但在行为序列中,间隔是不固定的,如 a 和 b 之间可能间隔 1 天,但 b 和 c 之间可能间隔 3 天,因此需要去引入 time embedding 刻画这种情形。
3. 推理
在推理阶段,将历史的 item 序列输入到 decoder 中,取模型输出的最后一位向量作为用户的表征。
另一方面,把所有广告 item 输入到 encoder 中,得到的向量构建 ANN 索引,最后通过 ANN 检索实现召回过程。
4. 优势与问题
该方案优势明显:首先,保证信息完备;其次,通过 encoder 压缩缓解性能问题;最后,端到端学习序列关系,保证协同学习,充分利用 transformer 对序列的刻画能力。与此同时,问题也很明显:缺少显示的兴趣生成过程,且建模空间在全量 Dense 空间中,该方案并未显著降低复杂度,本质上偏向度量式方式,未能完全发挥生成式优势。
03
第二阶段:Sparse 量化表征及 Sparse ID 生成
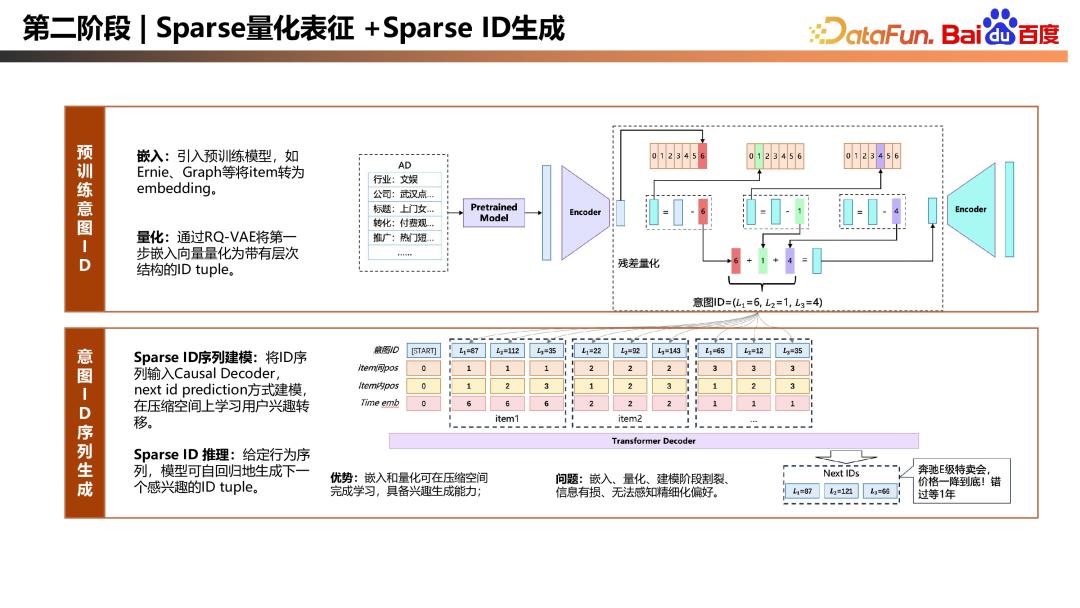
第二个阶段是 Sparse 量化表征以及 Sparse ID 生成
1. 嵌入、量化、建模及推理
第二阶段的工作参考了 Tiger 框架,分为嵌入、量化、建模。在嵌入阶段,通过 Ernie 将 item 原始信息表达为 embedding,也可通过双塔或 Graph 获取 item 的协同向量。在量化阶段,通过量化方式,如 RQ-VAE,将上述向量变为带有层次的 ID tuple。例如,将广告变为 (L1=6,l2=1,l3=4) 这样的 ID tuple,具体 codebook 的大小可根据业务规模设置,这样便将 item 序列变为了 ID 序列,学习空间被压缩到了有限的空间。在建模阶段,将 ID 序列输入 causal decoder,采用 next id prediction 的方式建模,在压缩空间上学习用户兴趣转移。在推理阶段,给定用户前序的 ID 序列,模型可自回归生成下一个感兴趣的 ID tuple。
2. 优势及问题
该方案得益于嵌入与量化的方式,可在压缩空间中学习,使模型具备在压缩空间中学习用户兴趣转移及生成的能力。但问题也很明显,嵌入、量化、建模这三个阶段是相对割裂的,预训练模型的量化会带来信息损失,使整个范式模型无法感知到细粒度偏好。同时,在实操过程中超参较多。例如,嵌入时选择语义模型还是协同模型,对结果影响较大,且各有优劣。另外,量化层级的大小也是难以调整的超参,层级太粗会加剧信息损失,层级太细则在进行 BeamSearch 时的性能开销较大。
04
思考:Review 建模范式

从阶段一到阶段二,虽然完成了度量式向生成式的转换,但效率提升有限。因此,重新 review 两个阶段的工作。
第一阶段的对比学习度量优点在于信息完备、能够端到端学习、刻画细粒度、协同关系,但缺点在于全量空间建模,缺乏兴趣探索能力。而第二阶段工作的优点在于在压缩空间中学习兴趣转移,具备高阶兴趣生成能力,但缺点在于建模割裂,信息有损,难以捕捉细粒度变化。总体来看,两个阶段工作的优缺点是高度互补的。基于这样的洞察,团队提出 Sparse、Dense 级联表征 + 生成度量一体化建模的全新范式。
05
第三阶段:Sparse、Dense 级联表征及生成度量一体化(COBRA)
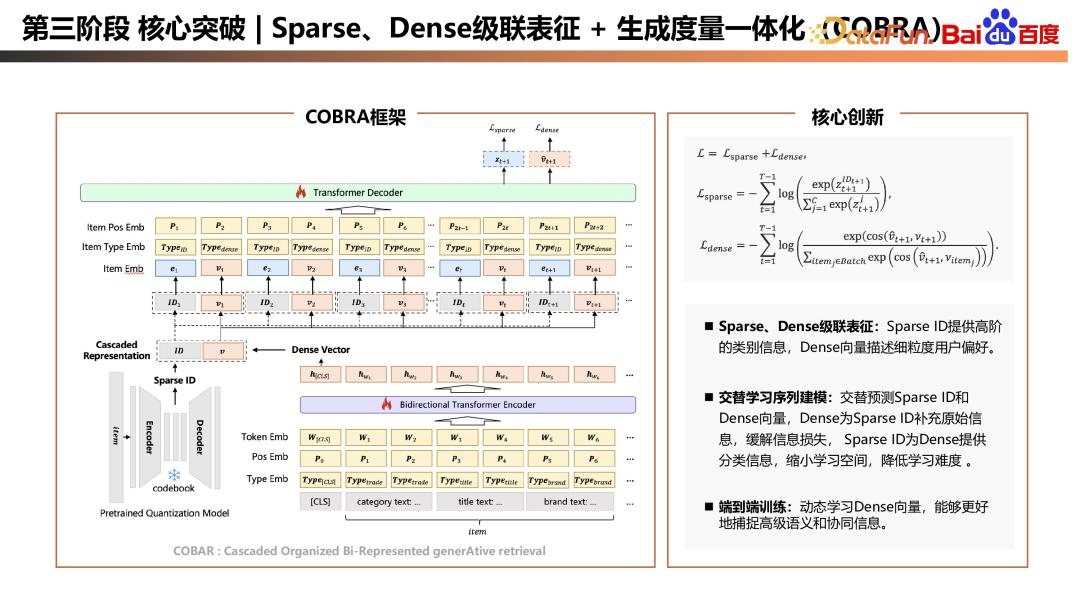
第三个阶段是 Sparse、Dense 级联表征以及生成度量一体化(COBRA)
COBRA 框架及细节如上图左侧所展示。在训练阶段,COBRA 有多个核心创新点。
首先是 Sparse、Dense 级联表征。在表征层面,COBRA 采用了 Sparse 和 Dense 的级联表征,Sparse ID 可以通过 codebook 学习得到,也可以是业务上具有明确物理含义 ID 的分割。Dense 可以通过 item 的原始信息学习得到,Sparse ID 代表高阶类别信息,Dense 向量表示用户细粒度偏好。此时,用户序列变成 Sparse 和 Dense 交替组织的形式,这引出了第二个核心创新点:交替学习序列建模。具体来说,在t时刻,需要预估 t+1 时刻的 ID 和 Dense 向量,Dense 向量为 Sparse ID 补充了原始信息,相对于纯 ID 序列,减缓了信息缺失问题;而在预估 Dense 向量时,ID 可以为 Dense 提供分类信息,缩小学习空间,降低学习难度。交替学习的范式使 Sparse 和 Dense 起到了相辅相成、互相促进的作用。最后,仍然保持 Dense 向量端到端学习,以更好地捕捉高级语义和协同信息。
06
核心突破:Coarse-to-Fine 推理
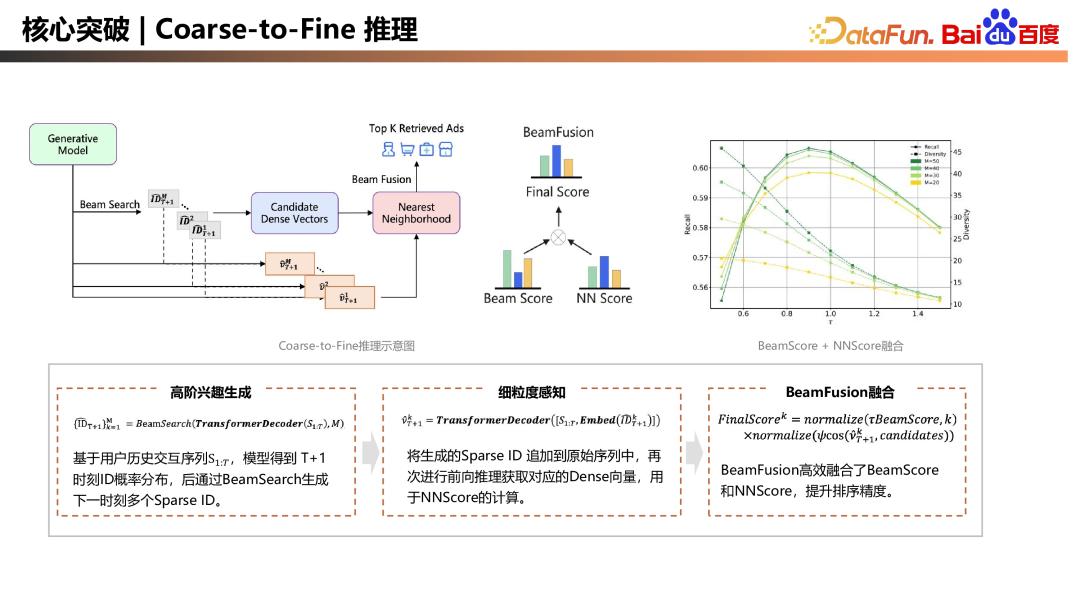
Coarse-to-Fine 推理过程,推理过程与训练一致。首先,高阶兴趣生成,将用户历史序列输入到训练好的模型中,得到下一个时刻 Sparse ID 的概率分布,通过 BeamSearch 生成下一时刻多个 Sparse ID。第二步,进行细粒度感知,将生成的 Sparse ID 依次追加到原始序列中,再次进行前向推理获得对应向量。这个过程中 ID 会与前序序列重新进行 attention 计算,从而获得该 ID 下对应的向量,代表用户的细粒度感知,用于 NNScore 计算,此时存在两个 Score,一个是高阶兴趣的 BeamScore,另一个是细粒度感知的 NNScore,团队提出了 BeamFusion 框架,高效融合 BeamScore 和 NNScore,兼顾召回的精度和多样性。如上图右上侧所示,可以看到不同的参数可以对应不同的 Recall 精度和不同的多样性,可以根据业务需求去选择合适的超参。
07
核心突破:生成度量一体化效果分析

通过上述的工作,COBRA 也取得了显著的效果。相对于前两个阶段的方法,COBRA 的 recall@ 800 绝对值提升了 12pp,相对提升了 36%。而且在生产数据和多个公开数据集上,均超过了 Google Tiger SOTA 方法。
除此之外,团队还进行了可视化分析,前面提到 Dense 向量是通过端到端学习得到的,但如上图所示,不同 Sparse ID 下的 Dense 向量体现了极强的内聚性,Sparse ID 的加入增加了 Dense 向量的组内内聚性和组间分离性,这也从后验角度证明了在动态学习过程中,Sparse ID 作为条件,对 Dense 向量的学习起到了引导作用。
08
释放生成式潜力:长序列拓展,在线推理

1. 长序列扩展
为进一步释放 COBRA 能力,一个自然的想法是引入更多域的信息或更长的序列,但显存瓶颈是长序列扩展的阻碍。这是因为与传统 NLP 模型相比,COBRA 多一个输入维度,传统模型的输入是 BatchSize×SeqLen×Dim,而 COBRA 是 BatchSize×SeqLen×Dim×TokenNum。前面提到 TokenNum量级并不低,因此在端到端训练时,拉长序列很容易导致显存 OOM。为此,团队进行了如下优化。
输入层优化
Tokenizer 优化:对于专有名词,按常规切词方式会切成多个 token,但将其视为一个整体处理后,虽然增加了 vocab 的大小,但能减少序列长度。
减少 padding:传统训练方式中存在两个维度的 padding:一是序列长度不一致带来的 SeqLen padding;二是每个 item 内部长度不一致带来的 padding。这些 padding 占用大量显存和计算资源。我们采用 packing 和 flash-attn 方案,有效消除了 padding 显存占用和计算消耗。
计算优化
重计算:通过重计算的方式减少前向激活值的存储,以时间换空间,节省显存。
多卡协作优化
All Gather 策略:不考虑序列拆分,单卡只处理一个样本是处理长度上限,但端到端学习 Dense 向量需要负样本来保证学习效率。引入 All Gather 策略,将其他卡的样本作为负样本,从而保证对比学习效率。
通过以上优化,序列长度显著提升,几千个序列已能满足需求。未来如果需要更长序列、或者加入更多信息,可以进一步开发序列拆分、多机多卡并行的方案。
2. 在线化推理提覆盖
在线化推理可以提高长尾用户和实时信号的覆盖,对应的挑战也比较明显,即在线 Latency 和资源开销的限制。优化的手段主要分三部分:首先是模型推理的优化,通过 Int8、 TRT 实现;其次是结合已有的近线系统,通过近线上已有的 Cache ttl 进行调优,平衡 Cache 与 Latency 的时效性;第三部分是索引的优化,COBRA 是多兴趣、多向量的召回方式,因此构造一个分层索引,降低 ANN 的检索空间,通过这三种方式实现在线化推理。
09
未来规划

首先、围绕 COBRA 生成度量一体范式,持续拉长序列长度,增加参数,提升 Scaling Law 边界,提升生成式召回的能力。
其次,优化训练和推理的性能,通过算子底层的优化,在长序列时,结合 NSA MOBA 等稀疏激活技术,最大化算力利用率,扩大覆盖面。
最后,我们的整体追求仍然是以提升精度为核心,探索召回、创意或排序一体的下一代生成式的推荐系统。
以上,就是百度生成式召回这块工作的分享,这里是百度商业技术的公众号,里面包括了生成式召回以及之后可能分享的百度精排作用等,包括最近 I2V 榜单第一的蒸汽机技术,以及多工程的优化等,在公众号里面都有很多干货,大家感兴趣的话,可以扫码关注一下。
10
Q&A
Q1:COBRA 推理得到的多个向量如何进行检索?
A1:原则上可以通过分层索引解决,即先获取 ID,ID 有对应的向量,让这个向量在 ANN 检索的时候只需召回该 ID 下的向量,这是一种分层索引的方式。但需注意,向量间是具有很强的组间分离性的,因此在全库召回时,只要召回的 top k 不是特别高,例如召回几十万个,基本上都会召回对应 ID 的向量。因此,这两种方式虽然实现方式上不同,但最终召回结果一致。
Q2:特征里面有考虑视频等其他形式信息吗?
A2:这是一项很重要的工作。我们也在尝试,现在主要是文本方式,之后如何将多模态信息利用开源的多模态 embedding,或量化成 ID 形式,如何结合进去也都是正在尝试的工作。
Q3:对于只有几万个 item 的情况,加入 Sparse 是否还有用?
A3:我认为是有用的,Sparse 增加了区分性,这可以从多个角度解释。加入 Sparse 后,再预估 Dense 时,Sparse 会与前序做激活,而在召回时无法像单塔那样处理,所以将 Sparse 的一部分信息扔到前序去做激活,所以我认为还是有用的。
Q4:COBRA 模型能直接用于精排模型吗?
A4:精排与召回的主要区别在于建模目标,召回可能是 k 分类,而精排可能更多关注点击率等二分类问题,这可以通过调整样本序列组织来解决。另一个较大差异是,精排目前更多采用大规模离散 ID 形式,偏记忆较多,而召回更关注泛化性,不会太多的偏记忆。这可能是主要差异。
Q5:有尝试过召回和精排联合建模吗?
A5:联合建模有一定效果和提升,但会带来问题,上下游一旦耦合,就很难解耦。
Q6:Sparse 方式为什么可以学到高阶兴趣转移?
A6:我觉得高级兴趣转移是一个描述。比如分类,以行业作为分类,用户他可能喜欢游戏、喜欢小说。在学习生成时,他学习的是 ID,因为空间是离散的,可以生成这样的 ID 形式。可以先探索他下一个感兴趣的 ID,可能是在游戏行业。那下一步,在游戏行业里,我知道你喜欢游戏,再去探索你喜欢哪一款游戏。然后可以学习后面的新 ID,这个召回范式只要不加 ID,其实对用户很友好,如果不基于后验信息,所需信息都可以加入的。
以上就是本次分享的内容,谢谢大家。
