深入解析Anthropic、OpenAI、Perplexity、LangChain 四大厂商的底层构建方向。拆解编排循环、工具能力、记忆系统、上下文管理等核心模块,完整说明:如何将无状态大模型改造为具备自主能力的智能Agent。

你或许搭建过聊天机器人,甚至基于ReAct循环对接了若干工具,演示场景下一切正常。可一旦落地生产级业务,各类问题便集中爆发:模型遗忘数步之前的操作、工具调用静默失败、上下文窗口被无效信息快速挤占。
问题根源不在于大模型本身,而在于模型周边的整套配套系统。
LangChain 早已印证这一点:仅升级大模型外层的调度基础设施(模型权重、参数完全不变),其在 TerminalBench 2.0 评测中就从全球30名开外跃升至第5名。另有独立研究项目,通过让大模型自主优化底层调度架构,最终通过率达到76.4%,全面超越人工设计的传统Agent系统。
如今,这套配套架构有了统一名称:Agent Harness(智能体调度基座)。
一、什么是 Agent Harness该术语于2026年初正式定型,但其理念早已长期存在。
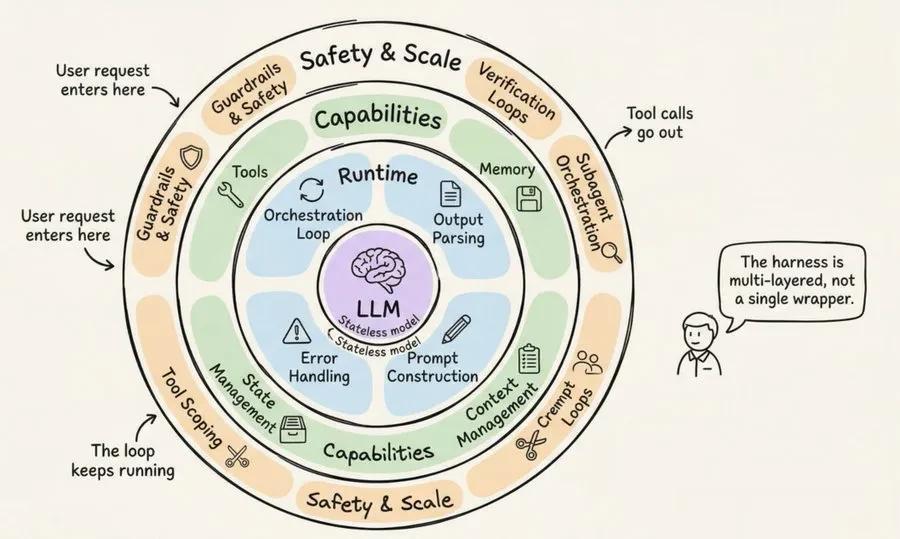
调度基座是包裹大模型的一整套完整软件基础设施,包含:编排循环、工具网关、长短记忆、上下文治理、状态持久化、异常容错、安全防护规则。
Anthropic 在 Claude Code 官方文档中给出极简定义:SDK 就是驱动 Claude Code 运行的Agent 调度基座。
OpenAI 的 Codex 团队也采用同一套理念,直接将「智能体」与「调度基座」划等号——指代模型之外、让大模型具备实用价值的全套工程系统。
LangChain 核心成员 Vivek Trivedy 提出的经典概括十分精辟:
不属于模型本身的一切,都是调度基座。核心概念区分(关键误区)
• 智能体(Agent):涌现式行为载体,面向目标、会调用工具、可自我纠错,是用户直接交互的最终形态;
• 调度基座(Harness):承载、驱动上述智能行为的底层工程架构。
所谓「开发一个Agent」,本质是搭建一套调度基座,并对接大模型。
学者 Beren Millidge 在2023年的文章《脚手架式大语言模型:自然语言计算机》中,用精准类比阐释了这套架构:
原生大模型,等同于一台无内存、无硬盘、无IO外设的裸CPU:

• 上下文窗口 = 内存(读写快、容量有限)
• 外部数据库 = 磁盘存储(容量大、访问慢)
• 工具调用能力 = 设备驱动
• 调度基座 = 操作系统
正如文中所言:我们本质上复刻了冯·诺依曼架构,这是所有计算系统的天然底层抽象。
二、三层智能体工程体系围绕大模型,工程能力分为三层同心圆结构:
1. 提示词工程:设计模型接收的指令与约束;
2. 上下文工程:管控模型可见的信息内容、展示时序;
3. 调度基座工程:涵盖前两者,并整合全链路能力——工具编排、状态持久化、故障恢复、校验闭环、安全管控、全生命周期管理。
调度基座绝非简单的提示词封装层,而是支撑自主智能行为落地的完整系统。
三、生产级调度基座的12大核心组件结合 Anthropic、OpenAI、LangChain 及行业最佳实践,标准化生产级基座包含12个核心模块:
1. 编排循环

整个智能体的核心心脏,落地思考-行动-观测(TAO) 闭环,也是常说的 ReAct 循环。
执行逻辑:组装上下文 → 调用大模型 → 解析结构化输出 → 执行工具调用 → 回填结果迭代,直至任务终止。
代码层面往往只是简单的 while 循环,复杂度不在循环本身,而在其管控的全链路逻辑。
Anthropic 将自身运行时定义为「极简循环」:所有智能决策由模型完成,基座仅负责轮次调度。
2. 工具系统
智能体的「手脚」。
以标准化结构化描述(名称、用途、参数约束) 注入模型上下文,让模型知晓可用能力。
工具层完整负责:注册管理、参数校验、入参解析、沙箱隔离执行、结果捕获、标准化回传格式。
典型厂商方案:
• Claude Code:六大工具矩阵(文件操作、搜索、命令执行、网页访问、代码分析、子智能体派生);
• OpenAI 智能体SDK:函数工具、托管工具(联网搜索/代码解释器/文件检索)、MCP 服务端工具。
3. 记忆体系
记忆按时间维度分层设计:
• 短期记忆:单会话内的对话历史、操作记录;
• 长期记忆:跨会话持久化存储。
落地方案:
• Anthropic:CLAUDE.md 项目配置文件 + 自动生成的 MEMORY.md 长期记忆;
• LangGraph:基于命名空间隔离的结构化JSON存储;
• OpenAI:基于 SQLite / Redis 的会话持久化。
Claude Code 采用三级记忆架构:轻量化常驻索引、按需加载的专题文档、仅检索访问的原始日志。
核心设计原则:智能体仅将历史记忆作为参考线索,执行操作前必须校验真实系统状态,杜绝幻觉误导。
4. 上下文管理
绝大多数智能体的隐性失效根源。
核心痛点:上下文衰减。研究显示,关键内容落在上下文窗口中段时,模型性能会下降30%以上(斯坦福「迷失中段」经典结论);即便百万级超长上下文,内容越多,指令遵循能力越弱。
生产级优化策略:
• 内容压缩:临近窗口上限时,精简对话冗余内容,保留架构决策、未解决Bug等高价值信息;
• 观测屏蔽:隐藏过期工具日志,仅保留调用记录;
• 按需加载:通过检索、命令按需读取文件片段,而非全量加载;
• 子智能体下沉:子模块深度执行后,仅返回1000~2000 Token的精简摘要。
Anthropic 上下文工程核心目标:用最少的高信号Token,最大化任务成功率。
5. 提示词组装
分层级拼接每一轮模型输入:系统提示词 → 工具定义 → 记忆文档 → 对话历史 → 用户当前指令。
OpenAI Codex 采用严格优先级策略:服务端管控系统提示(最高)→ 工具定义 → 开发者指令 → 用户业务规则 → 对话上下文。
6. 输出解析
现代基座依赖原生结构化工具调用:模型直接输出标准化 tool_calls 结构体,替代传统自由文本解析。
链路逻辑:识别工具调用→执行闭环;无工具调用→直接输出最终答案。
结构化输出场景下,OpenAI、LangChain 均支持基于数据模型(Pydantic)的强约束返回;传统兜底方案(错误重试解析)可覆盖边缘异常场景。
7. 状态管理
• LangGraph:以类型化字典作为流转状态,通过合并算子更新数据,支持断点续跑、时序回溯调试;
• OpenAI:四种互斥状态方案(应用内存、SDK会话、服务端会话API、轻量上下文链式关联);
• Claude Code:以Git提交作为全局快照、结构化进度文件作为临时工作区。
8. 异常容错
工程关键结论:单步操作成功率99%的10步流程,整体通过率仅约90.4%,错误会快速累积放大。
行业统一异常分类:
• 瞬时故障:退避重试;
• 模型可修复故障:错误信息封装为观测结果,交由模型自主修正;
• 人工干预故障:暂停流程,等待用户确认;
• 未知异常:上浮日志,用于问题排查。
9. 安全管控与防护
OpenAI 三层防护体系:输入前置校验、输出后置审核、工具调用全程拦截;触发熔断规则可立即终止智能体运行。
Anthropic 采用权责分离架构:模型负责决策要执行的操作,调度基座负责权限拦截。
Claude Code 对近40项独立能力做精细化权限管控,分三级校验:项目初始化信任认证、单次工具调用鉴权、高危操作人工确认。
10. 校验闭环
演示版与生产级智能体的核心分水岭。
Anthropic 推荐三类校验方案:
• 规则校验:单元测试、代码检查、类型校验;
• 视觉校验:UI自动化截图核验;
• 模型互评:独立子智能体复核输出结果。
Claude Code 负责人明确提出:完善的校验机制,可让智能体产出质量提升2~3倍。
11. 子智能体编排
多智能体协作标准化模式:
• Claude Code:分支复刻、独立协作终端、隔离Git工作区三种运行模式;
• OpenAI SDK:工具化子智能体、任务全权移交;
• LangGraph:嵌套状态图实现多级子流程。
四、完整运行闭环(七步全流程)1. 提示词组装:基座整合系统指令、工具列表、记忆文件、对话历史,高关键信息置于首尾,规避中段衰减;
2. 大模型推理:下发完整上下文,模型输出文本或工具调用请求;
3. 输出分类:无工具调用则终止流程;存在调用则进入执行;触发移交指令则切换智能体;
4. 工具执行:参数校验、权限拦截、沙箱运行;只读操作并发执行,数据变更操作串行执行;
5. 结果封装:工具执行结果/异常信息标准化封装,适配模型阅读格式,支撑自我纠错;
6. 上下文更新:结果写入对话历史,临近窗口阈值自动触发内容压缩;
7. 循环迭代:回到第一步持续运行,直至满足终止条件。
终止触发条件
模型直接回复、最大轮次超限、Token预算耗尽、安全规则熔断、用户手动中断、安全拒绝响应。
长周期复杂任务,Anthropic 提出拉尔夫双阶段循环:初始化智能体搭建环境、固化快照;后续会话智能体依托文件系统、Git日志承接上下文,实现跨窗口任务连续运行。
五、主流框架落地实现1. Anthropic Claude 智能体SDK
极简循环设计,通过统一接口拉起智能体流程,以异步流式返回结果;核心采用「收集信息-执行操作-结果校验」闭环。
2. OpenAI 智能体SDK & Codex
代码优先设计,原生支持同步/异步/流式三种模式;三层架构拆分核心运行时、通信服务、多端客户端,统一调度基座能力。
3. LangGraph / LangChain
以显式状态图为核心,通过条件路由串联模型调用与工具执行;原生支持多智能体、持久化记忆,是开源生态调度基座标杆。
4. CrewAI / AutoGen
分别主打角色化多智能体、会话式编排,通过分层架构实现任务分片、并行协作、动态调度。
六、脚手架核心隐喻与演进趋势调度基座如同建筑施工脚手架:临时、支撑性、非业务核心,但不可或缺。
随着大模型能力迭代,复杂的调度逻辑会逐步下沉至模型原生能力,基座复杂度会持续降低。
行业核心演进规律:模型与调度基座协同迭代。
定制化训练的模型会深度适配专属基座,贸然更换工具逻辑反而会导致性能断崖式下跌。
基座设计的长期评判标准:模型越强,无需改造基座即可线性提升整体能力。
七、调度基座设计的七大核心决策所有工程落地都需要权衡选择:
1. 单智能体优先 VS 多智能体拆分;
2. ReAct 即时推理 VS 先规划后执行;
3. 上下文治理策略:压缩/屏蔽/按需加载/子代理下沉;
4. 校验体系:代码强校验 VS 模型软复核;
5. 权限策略:宽松放行 VS 严格风控;
6. 工具范围:最小化暴露 VS 全能力开放;
7. 架构权重:轻量化基座(依赖模型)VS 强管控基座(人工约束)。
八、总结:调度基座才是核心产品两款完全相同的大模型,仅因调度基座设计差异,最终智能体效果会天差地别。
调度基座不是同质化基础组件,而是AI智能体最核心的工程壁垒:稀缺的上下文资源调度、前置故障校验、低幻觉记忆体系、架构长期取舍,全部集中于此。
未来模型能力会持续变强,但调度基座不会消失。
任何顶级大模型,永远需要一套系统来管理上下文、执行工具、持久化状态、校验产出。
往后遇到智能体失效,不必急于归咎模型——问题往往藏在调度基座之中。