ZAP是非盈利组织OWASP(Open Web Application Security Project)维护并开源的web安全测试工具。它旨在帮助开发者或安全专业人员发现web应用中的安全漏洞,提升应用的安全性。
安全测试的第一步首先是信息收集,收集的信息越多、越全面就越有利于安全漏洞的发现,ZAP支持传统爬虫Traditional Spider、Ajax Spider(基于Ajax动态请求实现的web应用)等多种方式进行web应用的服务路径的发现,以支持后续的安全扫描、模拟攻击等,也就是说ZAP也可以作为一款优秀的web目录爬虫工具来使用。本文首先介绍如何准备好ZAP的API调用环境,接着展示如何使用python来调用ZAP的传统爬虫API、Ajax Spider来爬取web目录。
ZAP基本配置官方网站下载并安装ZAP后正常启动,此时访问http://localhost:8080/UI应能够正常本地API界面,这表明可以正常调用ZAP API。ZAP的核心原理是“中间人代理”,它会启用代理拦截用户和web应用之间的消息。

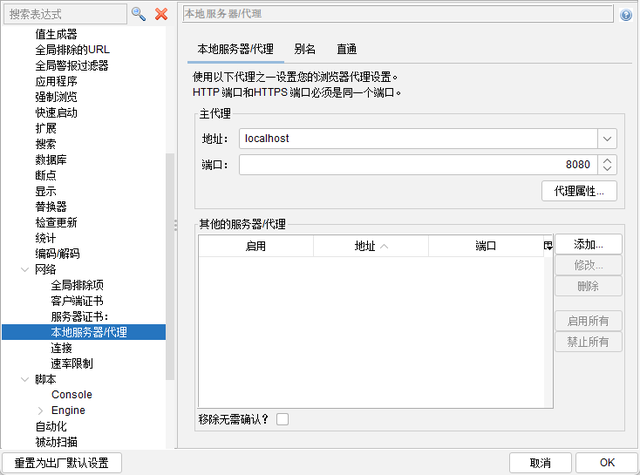
如果无法正常访问可能是因为8080被占用,ZAP会自动更换端口。可以在打开选项>网络>本地服务器代理查看实际使用的代理端口,也可以在主界面的左下角看到主代理信息。
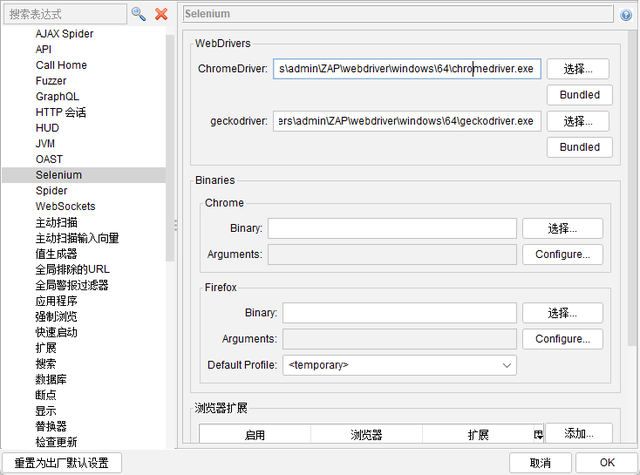
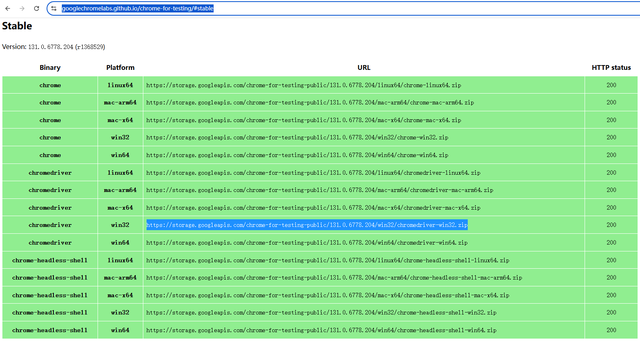
另外,ZAP的Ajax Spider需要使用Selenium操控浏览器,这里以chrome为例,ZAP默认安装的版本很大可能不匹配系统已安装的chrome。因此需要下载匹配的chromedriver版本并覆盖到ZAP对应的目录下,查看选项>Selenium可以看到具体存放目录,chromedriver的下载链接见参考文献。
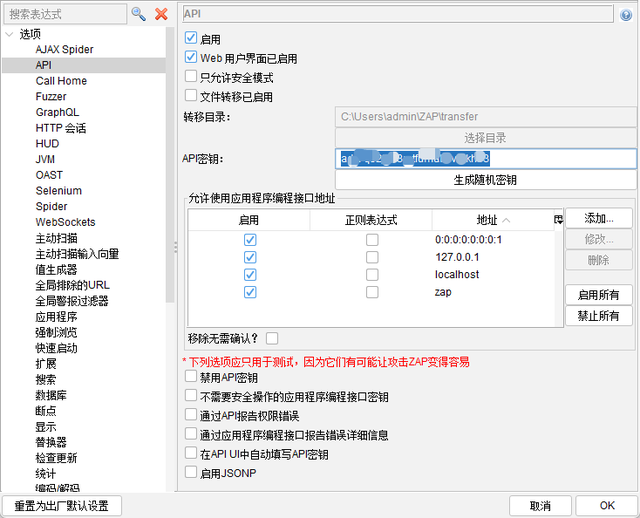
最后,调用ZAP的API需要使用密钥,选项>API可以查看API密钥串,后续的API调用都要替换为自己的API密钥,否则调用会失败,后面不再说明。
 传统爬虫API
传统爬虫API调用API前先pip install zaproxy安装依赖库zaproxy。传统爬虫代码示例如下,zap.spider.scan启动爬虫、zap.spider.status用来查询进度、zap.spider.results返回所有爬取的URL列表。
#!/usr/bin/env pythonimport timefrom zapv2 import ZAPv2# 待测试网站URLtarget = 'https://scrape.center/'# 这里更换为自己的API密钥apiKey = '更换为自己的API密钥'# 默认连接8080端口zap = ZAPv2(apikey=apiKey)# 如果发现使用的不是8080端口,则需要按照如下形式执行具体的端口# zap = ZAPv2(apikey=apiKey, proxies={'http': 'http://127.0.0.1:8090', 'https': 'http://127.0.0.1:8090'})print('Spidering target {}'.format(target))# 启动爬虫scanID = zap.spider.scan(target)# 循环检查爬虫进度,100表示爬虫完成while int(zap.spider.status(scanID)) < 100: # Poll the status until it completes print('Spider progress %: {}'.format(zap.spider.status(scanID))) time.sleep(1)print('Spider has completed!')# results为爬取的URL列表results = zap.spider.results(scanID)for url in results: print(url)运行结果,逐项打印了爬取的所有URL
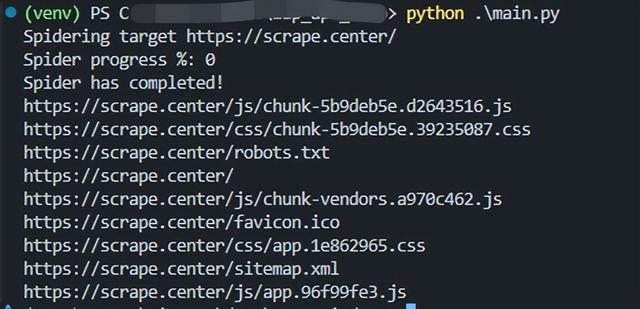
运行爬虫过程中会发现ZAP主界面中也会动态更新Spider爬取的结果。
 Ajax Spider API
Ajax Spider API动态爬虫API会操控浏览器进行URL发现,代码示例如下,set_option_browser_id用来设置浏览器类型,chrome-headless表示使用chrome无界面模式,若传入chrome则会显示打开的浏览器窗口。另外Ajax Spider只有running状态表示在扫描中,不像传统爬虫可以查看进度值。
#!/usr/bin/env pythonimport timefrom zapv2 import ZAPv2# 待测试网站URLtarget = 'https://scrape.center/'# 这里更换为自己的API密钥apiKey = '更换为自己的API密钥'# 默认连接8080端口zap = ZAPv2(apikey=apiKey)# 如果发现使用的不是8080端口,则需要按照如下形式执行具体的端口# zap = ZAPv2(apikey=apiKey, proxies={'http': 'http://127.0.0.1:8090', 'https': 'http://127.0.0.1:8090'})# 设置浏览器标识,这里使用chrome# zap.ajaxSpider.set_option_browser_id("chrome")# 无界面模式传入chrome-headlesszap.ajaxSpider.set_option_browser_id("chrome-headless")print('Ajax Spider target {}'.format(target))scanID = zap.ajaxSpider.scan(target)# 设置超时时间为2分钟timeout = time.time() + 60*2# 循环检测爬虫状态while zap.ajaxSpider.status == 'running': if time.time() > timeout: break print('Ajax Spider status' + zap.ajaxSpider.status) time.sleep(2)print('Ajax Spider completed')ajaxResults = zap.ajaxSpider.full_resultsprint(ajaxResults)zap.ajaxSpider.full_results返回结果格式如下:
{ "fullResults": { "inScope": [ { "statusReason": "OK", "method": "GET", "messageId": "932", "url": "https://scrape.center/", "statusCode": "200" }, { "statusReason": "OK", "method": "GET", "messageId": "933", "url": "https://scrape.center/js/app.96f99fe3.js", "statusCode": "200" }, ...省略 ], "errors": [] }}运行结果参考

可以在选项>AJAX Spider中设置打开的浏览器窗口数、爬取深度等参数。
 参考文献
参考文献[1]. ZAP官方API文档https://www.zaproxy.org/docs/api[2]. chromedriver下载链接https://googlechromelabs.github.io/chrome-for-testing/#stable