在一分钟内快速理解Apache Kafka的基础知识。
让我们开始吧!
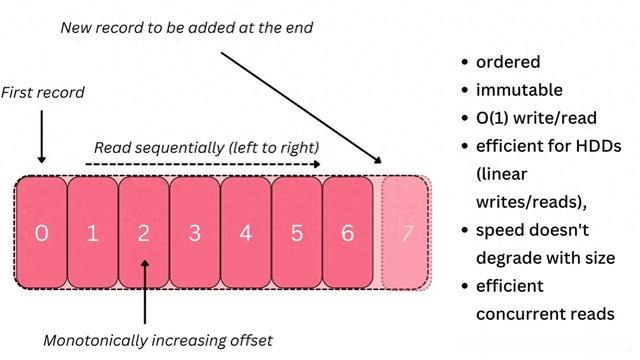
Apache Kafka 是一个分布式提交日志系统日志是最基础的数据结构,它是一个有序的记录序列,只支持添加操作。
它是不可变动的,所以你无法删除或修改已有的记录。
 Kafka将其数据储存在称为主题的地方
Kafka将其数据储存在称为主题的地方主题会被分割成分区,并在各个代理节点上进行复制。
结构大致上是:主题 → 分区 → 副本 → 一大堆文件(日志)
1. 每个主题都包含多个分区
2. 每个分区都有多个(一般是3个)副本
3. 每个副本都包含许多文件
所有的文件组成的就是日志。
Kafka是一个分布式系统,其每个服务器被称为代理。
代理主要负责存储分区的副本。

那么,还剩下些什么呢?
客户端数据是怎么进出Kafka的呢?简单来说。
1. 客户端(生产者)往Kafka节点(代理)发送消息(记录)。
它们只能向分区的主分区写入数据。
2. 其他称为消费者的客户端读取并处理这些消息。
消费者可以从任意分区读取数据,无论主分区还是从分区。
它们通过TCP协议连接至代理,并使用自定义的Kafka协议跟代理进行通讯。
生产者/消费者客户端其实就是一个实现了Kafka协议的Java库,为你提供了一个友好的交互界面。

如今,几乎所有的编程语言都有相关的实现版本。
最后?
由于Kafka是一个分布式系统。它需要进行协调。
Kafka通过设定称为“控制器”的特殊代理来实现。
在任意时刻,只有一个活动的控制器。
控制器是集群中元数据的主要来源。
它负责执行许多任务,其中最主要的就是通过临时更换主分区来应对代理故障。
• 普通代理间的主分区选举是通过控制器执行的。
• 控制器间的选举(用于选择活动的控制器)则是通过Raft(KRaft)的变形版本执行的。
所有集群的元数据都被储存在一个简单(但特殊)的Kafka主题中,其主分区就是当前活动的控制器。
所有代理都复制这个主题 - 这就是它们获取元数据的方式。

这就是一分钟版本的Apache Kafka介绍。