判断问卷样本质量的核心是 从「样本匹配度」「填写真实性」「数据一致性」三个维度层层校验,结合渠道特征、问卷答题行为和数据分布综合判断,具体可分为以下 4 个步骤:
一、 第一步:核验样本的
这是样本质量的基础,若样本与目标人群不符,数据再 “好看” 也无意义。
核对人群标签一致性对照调研前定义的目标人群特征(如 “20-24 岁本科在读大学生”“金融业入职 1 年的管培生”),检查样本的核心属性是否匹配:
若通过太初数据等垂直平台收集,可直接查看平台的标签筛选记录,确认样本是否勾选了 “年级 / 专业 / 行业” 等关键标签;
若自主收集,可统计样本的基础属性分布(如年龄、职业、学历),看是否与目标人群一致。例:调研 “大学生考研意向”,若样本中 30% 是已毕业人群,说明匹配度差,需剔除这部分数据。
检查样本结构合理性看样本的关键维度分布是否均衡,避免单一特征过度集中:
若设置了配额(如 “男女比例 1:1”“不同专业各占 20%”),核对实际样本是否达标;
若未设置配额,观察是否存在 “某一群体占比过高” 的情况(如调研全国大学生,却 90% 是一线城市学生),这类样本代表性不足。
二、 第二步:筛查样本的
这是判断数据是否可用的关键,重点识别 “为拿奖励乱填”“机器刷量” 的无效样本。
分析答题时长计算每份样本的平均填写时长,设定合理阈值:
若问卷有 10 题,正常填写需 3-5 分钟,短于 1 分钟的样本大概率是乱填,直接标记为无效;
过长的时长(如超过 10 分钟)也需警惕,可能是填写者中途离开,数据连贯性差。正规平台(如问卷星、太初数据)会自带答题时长监控功能,可直接筛选异常时长样本。
检查答案的认真程度重点关注两类异常答案:
同质化答案:所有题目选同一选项(如全选 “A”)、连续选相同答案(如 A-B-A-B 循环),这类样本毫无参考价值;
矛盾答案:前后逻辑冲突(如前面选 “每周喝奶茶 5 次以上”,后面选 “从不喝奶茶”),可通过问卷中设置的逻辑验证题快速识别。
识别重复样本检查是否存在同一 IP、同一设备多次填写的情况,或答案完全一致的多份样本:
问卷星等平台支持IP 去重、设备号去重功能;
自主收集的样本可通过 “填写时间 + 答案相似度” 排查重复数据,避免同一人多次填写干扰结果。
三、 第三步:验证数据的
高质量样本的数据分布会符合常识和调研主题的基本逻辑,不会出现极端异常。
查看核心指标的分布趋势统计关键问题的答案分布,若出现 “极端集中” 或 “完全随机”,说明质量差:
例:调研 “奶茶甜度偏好”,正常分布应为 “三分糖 40%、五分糖 30%、全糖 10%”,若 90% 选 “全糖”,则需怀疑样本造假或人群定位偏差;
若答案分布完全无规律(如各选项占比均为 20% 左右),可能是填写者随机勾选。
校验开放式问题的回答质量若问卷有开放式问题(如 “你对产品的建议”),高质量样本会给出具体、有针对性的回答(如 “希望增加小料种类”);低质量样本的回答则是无意义的空话(如 “挺好的”“没意见”),或复制粘贴的重复内容,这类样本可直接剔除。
四、 第四步:结合
样本质量和收集渠道强相关,可通过渠道类型初步判断质量等级:
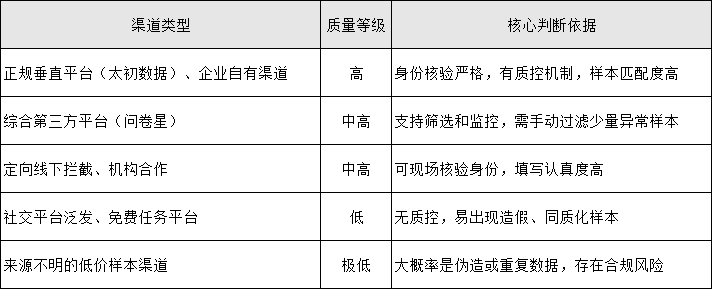
总结:快速判断样本质量的 3 个动作
先筛渠道:优先保留正规平台和自有渠道的样本,剔除低价黑灰渠道的数据;
再筛行为:删除时长异常、答案矛盾、重复填写的样本;
最后筛逻辑:检查核心数据分布是否符合常识,保留趋势合理的样本。