凌晨两点,我盯着Claude的响应框发呆。一个"帮我做代码审查+安全扫描+性能分析"的需求,愣是让AI跑了五分钟还没出结果。更要命的是,它居然把安全漏洞和代码风格问题混在一起输出,我得自己再花半小时手动分类整理。那一刻我突然意识到:问题不在AI不够聪明,而在于我们一直在用"单线程"思维使用它。
从一次"翻车"说起:为什么你的AI用起来总是慢半拍?你有没有这种体验?
让AI帮你翻译5个文档,它老老实实一个一个处理,你眼睁睁看着进度条挪了180秒。
让AI分析一个项目,它把所有问题糊成一坨输出给你,代码质量、安全隐患、性能瓶颈混在一起,看得人头皮发麻。
让AI处理一个复杂任务,中途出个小错,整个流程得从头再来。
这不对劲。
我们明明有了强大的AI助手,为什么用起来还是像在用单核CPU跑多线程程序一样别扭?
问题的症结在于:大多数人把AI当成了一个"万能黑箱"——把复杂需求一股脑丢进去,祈祷它能吐出完美结果。但AI也是有"认知带宽"的,一次性塞太多东西进去,它不仅处理慢,输出质量还会严重下滑。
于是我开始琢磨:能不能借鉴分布式系统的思想,把一个大任务拆成多个小任务,然后"并行"处理?
这一琢磨,就琢磨出了一套分布式任务编排系统。
核心洞见:把AI当成"项目经理",而不是"打工人"先聊聊这套系统的设计哲学。
传统的AI使用方式是这样的:
用户 → 复杂任务 → AI → 复杂输出 → 用户手动整理这种模式的问题显而易见:所有的复杂性都压在了AI和用户身上。AI要一次性处理太多东西,用户要从一坨混乱的输出里提炼有用信息。
而我设计的方式是这样的:
用户 → 复杂任务 → Orchestrator(编排器) → 拆分成原子任务↓Agent-01 Agent-02 Agent-03 (并行执行)↓聚合器 → 结构化输出核心思想转变:不要让一个AI扛所有事,而是让一个"总指挥"分配任务给多个"专项小组"。
这就好比你接了一个大项目,你不会一个人从前端写到后端再到运维,而是会拉一个团队,后端的写API,前端的写UI,运维的配环境。每个人各司其职,最后再把成果合并起来。
AI也该这么用。

使用skill启动后,会先生成.orchestrator
我们可以看到,现在已经是多个agent同时运行了,效率提高N倍
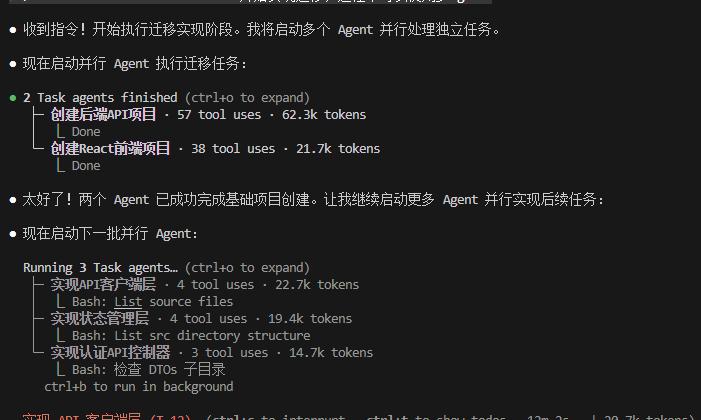
执行过程会维护任务状态表
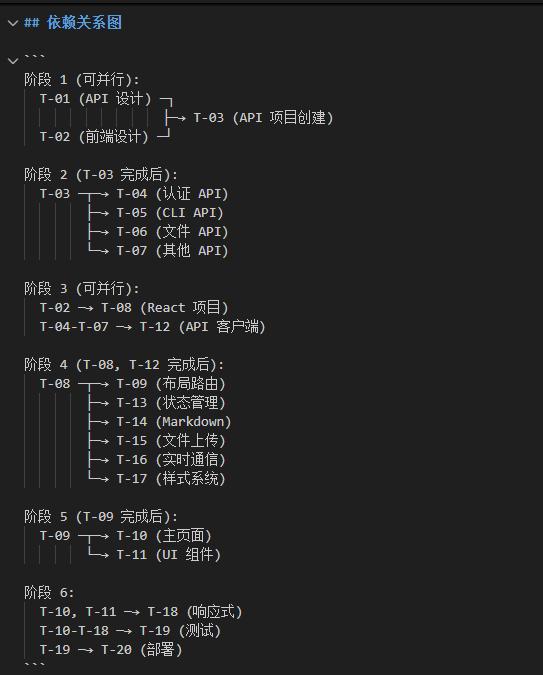
 四阶段工作流:像剥洋葱一样拆解复杂任务
四阶段工作流:像剥洋葱一样拆解复杂任务整套系统分四个阶段,我喜欢叫它"四步分身术"。
阶段一:任务分析与分解——把"大象"切成"肉片"拿到一个复杂需求,第一步不是急着让AI动手,而是先做"任务拓扑分析"。
举个例子,用户说:"帮我分析这个TypeScript项目的代码质量、安全漏洞和性能问题,生成完整报告。"
菜鸟做法:把这句话原封不动丢给AI,等着它吭哧吭哧跑完。
高手做法:先画一张任务依赖图。
┌──→ [T-02: 代码质量分析][T-01: 代码扫描] ───┼──→ [T-03: 安全漏洞扫描]└──→ [T-04: 性能问题分析]↓[T-05: 生成报告] ←─────────┘你看,这里面有门道:
T-01是基础任务,得先把代码读出来,后面的分析才有原料 T-02、T-03、T-04彼此独立,完全可以同时执行 T-05要等前面三个都跑完,才能聚合输出一个看似简单的需求,拆开来是个DAG(有向无环图)。这玩意儿在分布式计算领域早就玩烂了,但在AI任务编排这块,大多数人还在用"串行"思维。
关键原则:每个原子任务必须满足四个条件:
单一职责:只做一件事 独立可执行:不依赖运行时上下文 输出可验证:有明确的成功/失败标准 支持重试:失败后可以安全地重新执行为什么强调这些?因为这是后续"并行化"和"容错"的基础。一个设计良好的原子任务,就像乐高积木——可以自由组合,坏了一块换一块就行。
阶段二:Agent分配与状态管理——给"分身"们发任务单任务拆好了,下一步是分配"虚拟Agent"。
这里我借鉴了微服务架构的思想:每个Agent就像一个独立的服务实例,有自己的输入输出规范,彼此通过"文件系统"通信。
为什么用文件而不是内存?两个字:持久化。
想象一下,你有5个Agent在并行跑,跑到一半机器crash了。如果状态全在内存里,前功尽弃;但如果状态都写在文件里,重启后扫一眼就知道哪些任务完成了、哪些需要重跑。
这就是"状态持久化"的威力——把瞬时状态变成持久记录,让整个系统具备"断点续传"能力。
我设计了一套状态标记系统:
图标
状态
含义
Pending
等待执行
Running
正在执行
✅
Completed
执行成功
❌
Failed
执行失败
⏸️
Waiting
依赖未满足
Retrying
重试中
别小看这几个emoji,**它们是整个系统的"心跳"**。通过扫描状态文件,你可以随时知道任务执行到了哪一步、卡在了哪里、需不需要人工干预。
每个Agent的任务文件长这样:
# Agent-03 任务分配## 任务信息- **任务ID**: T-03- **任务名称**: 安全漏洞扫描- **优先级**: P1- **预估时间**: 2分钟## 输入| 参数 | 类型 | 来源 | 值 ||------|------|------|-----|| codeFiles | array | T-01输出 | .orchestrator/results/agent-01-result.md |## 任务描述扫描代码中的安全隐患,包括:1. 硬编码的密钥/Token2. SQL注入风险3. XSS攻击向量## 期望输出JSON格式的漏洞报告,包含:- 漏洞位置(文件:行号)- 严重等级(Critical/High/Medium/Low)- 修复建议注意这个格式:输入参数明确来源,输出格式预先定义。这不是为了好看,而是为了让Agent"无脑执行"——输入越清晰,AI犯错的概率越低。
阶段三:并行执行——真正的"分身术"这是整套系统最爽的部分。
还记得开头说的5个文档翻译要180秒吗?如果5个Agent并行处理,理论上45秒就能搞定——4倍加速。
但这里有个坑很多人会踩:并行不是乱来,得遵守依赖关系。
我把执行调度抽象成了一个"拓扑排序+批次执行"的算法:
第1批:[T-01: 代码扫描] (无依赖,直接开始)↓第2批:[T-02: 质量分析] || [T-03: 安全扫描] || [T-04: 性能分析] (并行执行)↓第3批:[T-05: 生成报告] (等前面都完成)核心逻辑:先找出所有"无依赖"的任务,一起开跑;跑完后,找出所有"依赖已满足"的任务,再一起开跑。循环往复,直到所有任务完成。
具体怎么并行?两种方式:
方式A:模拟并行
如果你只有一个AI实例,就用"分时复用"——逻辑上是并行的,物理上是串行的。但至少省去了人工拆分和合并的时间。
方式B:真并行(通过CLI启动子进程)
这是真正的黑科技。用PowerShell Job或者Runspace Pool,同时启动多个Claude CLI实例,每个实例跑一个Agent任务。
$taskFiles = Get-ChildItem ".orchestrator/agent_tasks/*.md"$jobs = foreach ($file in $taskFiles) {Start-Job -ScriptBlock {param($taskPath, $resultPath)$task = Get-Content $taskPath -Rawclaude -p $task | Out-File $resultPath -Encoding UTF8} -ArgumentList $file.FullName, ".orchestrator/results/$($file.BaseName)-result.md"}$jobs | Wait-Job这段脚本做了什么?
扫描所有Agent任务文件
为每个任务启动一个后台Job
每个Job独立调用Claude CLI
所有Job并行执行,互不干扰
等待全部完成
效果拔群。之前串行跑5分钟的任务,现在1分半搞定。而且因为每个Agent独立运行,一个失败不影响其他——这就是故障隔离。
阶段四:结果聚合——把"碎片"拼成"完整拼图"所有Agent跑完了,最后一步是聚合结果。
这步听起来简单,实际上有讲究。你不能只是把几个输出文件拼在一起——那样用户还是得自己梳理。
好的聚合应该做三件事:
去重:不同Agent可能报告了相同的问题 排序:按重要性/紧急程度排列 提炼:生成Executive Summary,让用户一眼抓住重点我的做法是:再调用一次AI,让它专门做"结果整合"。
$allResults = Get-Content ".orchestrator/results/*.md" -Raw$mergePrompt = @"请整合以下多个子任务的执行结果,生成一份完整报告:$allResults要求:1. 保留所有关键信息2. 消除重复内容3. 按逻辑顺序组织4. 生成执行摘要"@claude -p $mergePrompt | Out-File ".orchestrator/final_output.md"这一步的成本很低(输入都是结构化的),但价值极高——用户拿到的不再是一堆散落的碎片,而是一份可以直接拿去汇报的完整报告。
依赖关系处理:三种模式,三套打法前面提到了任务依赖,这块值得单独拎出来讲讲。
依赖关系处理的好坏,直接决定了系统的灵活性和效率。我总结了三种常见模式:
模式一:串行依赖T-01 → T-02 → T-03老老实实排队,一个接一个。适用于强因果关系的任务链,比如"创建文件 → 写入内容 → 校验格式"。
这种情况并行没意义,老老实实串起来就行。
模式二:完全并行T-01 ─┐T-02 ─┼─→ T-04T-03 ─┘T-01/02/03彼此独立,可以同时跑;T-04等它们全完成再执行。
这是效率最高的模式。如果你的任务拆得足够细、依赖足够少,大部分时间都在这个模式下运转。
模式三:DAG依赖T-01 ───→ T-03╲ ╱T-02 ───→ T-04复杂依赖关系,需要用拓扑排序来确定执行顺序。这是最灵活也最复杂的模式。
处理DAG的核心原则:每一轮只启动"入度为0"的节点。
什么是"入度为0"?就是所有依赖都已满足的任务。跑完后更新依赖图,继续找下一轮的"入度为0"节点。
这块我写了一个依赖感知的执行器:
$taskGraph = @{"T-01" = @{ Agent = "Agent-01"; Deps = @ }"T-02" = @{ Agent = "Agent-02"; Deps = @("T-01") }"T-03" = @{ Agent = "Agent-03"; Deps = @("T-01") }"T-04" = @{ Agent = "Agent-04"; Deps = @("T-02", "T-03") }}$completed = @{}while ($completed.Count -lt $taskGraph.Count) {# 找出所有依赖已满足的任务$readyTasks = Get-ReadyTasks -graph $taskGraph -completed $completed# 并行执行这一批任务$jobs = foreach ($taskId in $readyTasks) {Start-Job -ScriptBlock { ... }}$jobs | Wait-Job# 标记完成foreach ($job in $jobs) {$completed[$job.Name] = $true}}这段代码的精髓在于:它不关心具体有多少任务、依赖关系多复杂,只要你定义好了依赖图,它就能自动找到最优执行路径。
容错设计:失败是常态,优雅处理才是本事分布式系统有句老话:不是会不会出错,而是什么时候出错。
AI任务执行同样如此。网络抖动、超时、模型抽风……各种幺蛾子随时可能发生。
我设计了一套三层容错机制:
第一层:自动重试function Invoke-AgentWithRetry {param([string]$TaskFile,[int]$MaxRetries = 3,[int]$TimeoutSeconds = 300)$retryCount = 0while ($retryCount -lt $MaxRetries) {$job = Start-Job -ScriptBlock {param($taskPath)claude -p (Get-Content $taskPath -Raw)} -ArgumentList $TaskFileif (Wait-Job $job -Timeout $TimeoutSeconds) {$result = Receive-Job $jobRemove-Job $jobreturn @{ Success = $true }}Stop-Job $jobRemove-Job $job$retryCount++Start-Sleep -Seconds (5 * $retryCount) # 指数退避}return @{ Success = $false }}关键细节:指数退避(5秒、10秒、15秒)。不要傻乎乎地失败了立刻重试——如果是系统过载导致的失败,连续重试只会让情况更糟。
第二层:故障隔离一个Agent挂了,不影响其他Agent继续跑。这得益于我们把每个任务都设计成了"独立可执行"的原子单元。
第三层:状态持久化每次状态变化都写入文件。系统重启后,扫一眼状态文件就知道从哪里继续。
## ⚠️ 错误日志| 时间 | Agent | 任务ID | 错误类型 | 描述 | 恢复策略 ||------|-------|--------|----------|------|----------|| 14:30:22 | Agent-03 | T-03 | Timeout | CLI执行超时 | 重试3次后成功 |这套组合拳打下来,系统的鲁棒性直接拉满。
实战案例:从代码审查到多文档翻译光说不练假把式,来看看实际效果。
案例一:代码审查(典型DAG依赖)需求:"分析这个TypeScript项目的代码质量、安全漏洞和性能问题"
任务分解:
T-01:扫描代码文件(1.8秒)
T-02:质量分析(3.2秒)—— 依赖T-01
T-03:安全扫描(2.8秒)—— 依赖T-01
T-04:性能分析(2.5秒)—— 依赖T-01
T-05:生成报告(1.5秒)—— 依赖T-02/03/04
串行执行时间:1.8 + 3.2 + 2.8 + 2.5 + 1.5 =11.8秒
并行执行时间:1.8 + max(3.2, 2.8, 2.5) + 1.5 =6.5秒
加速比:1.8倍
看起来加速不多?别急,任务越多、独立性越强,加速比越明显。
案例二:多文档翻译(完全并行)需求:"把docs目录下的5个英文文档翻译成中文"
任务分解:5个独立翻译任务,无任何依赖。
串行执行时间:约180秒
并行执行时间:约45秒
加速比:4倍
这才是并行的威力——当任务之间完全独立时,加速比接近线性增长。
案例三:API端点测试需求:"测试所有API端点的响应时间和正确性"
这个场景更有意思。因为每个端点测试是独立的,所以可以全并行;但最后需要一个聚合任务来生成测试报告。
最终输出长这样:
# API 测试报告## 概览| 指标 | 数值 ||------|------|| 测试端点 | 5 || 测试用例 | 15 || 通过 | 14 || 失败 | 1 || 平均响应时间 | 156ms |## 失败用例### ❌ POST /api/users - 大数据量测试- 状态: 超时- 响应时间: 5023ms(阈值: 1000ms)- 建议: 优化数据库写入性能结构化、可操作、一目了然。
踩过的坑与血泪教训说点不那么光彩的。
坑1:任务粒度失控刚开始我把任务拆得太细,一个需求拆成了20个原子任务。结果呢?光是任务调度和结果聚合的开销就快赶上任务本身了。
教训:理想的任务粒度是1-5分钟。太大了难以并行,太小了调度开销太高。
坑2:依赖定义含糊有一次我定义了一个任务依赖,说"T-03需要T-01的部分输出"。结果T-03跑的时候找不到需要的数据,直接挂了。
教训:依赖关系必须精确到具体的数据/文件。"部分输出"这种模糊描述是定时炸弹。
坑3:并发数太高我一度尝试同时跑10个Claude CLI实例。结果?API限流了,全部超时。
教训:并发数要控制在4-8个。贪多嚼不烂。
坑4:忽略了聚合成本最开始我以为聚合就是简单拼接,结果用户抱怨"输出乱七八糟看不懂"。
教训:聚合也是一个需要认真设计的任务。投入10%的精力在聚合上,用户体验提升50%。
超越技术:这套思维模式的普适价值聊到这儿,我想跳出技术细节,聊聊更高层面的东西。
这套分布式任务编排的思想,其实不仅仅适用于AI。它背后的核心理念是:
把复杂问题分解成简单问题,把串行流程转化成并行流程,把脆弱系统加固成健壮系统。
这套方法论可以迁移到很多场景:
项目管理:把大项目拆成独立可交付的模块,并行推进 个人效率:把一天的待办事项按依赖关系排序,最大化并行度 系统设计:把单体服务拆成微服务,各自迭代、独立部署好的架构师不是写代码写得多好,而是把复杂问题结构化的能力有多强。
下一步:还有哪些坑等着踩?这套系统目前运转良好,但还有不少可以改进的地方:
更智能的任务分解:现在任务分解还是半手动的,未来希望AI能自动识别最优分解方案 动态负载均衡:某些任务跑得快、某些跑得慢,能不能让快的Agent接管慢的任务? 成本优化:并行调用多个AI实例是要花钱的,如何在速度和成本之间找到平衡点? 可视化监控:现在状态全靠Markdown文件,未来想做一个实时仪表盘如果你也在探索类似的方向,欢迎评论区交流。技术这东西,越讨论越清晰。
写在最后回到开头的场景——凌晨两点对着电脑发呆的我。
现在,同样的"代码审查+安全扫描+性能分析"需求,我只需要:
运行一个初始化脚本(2秒)
看着5个Agent并行跑完(60秒)
拿到一份结构化的报告(0秒,自动生成)
从5分钟+30分钟手动整理,到1分钟全自动出报告。
这不是什么黑魔法,就是把分布式系统那套经典思想,用到了AI任务编排上。
有时候,解决问题的关键不是找到更强的工具,而是找到更好的使用方式。
项目地址: https://github.com/xuzeyu91/distributed-task-orchestrator