锁屏面试题百日百刷,每个工作日坚持更新面试题。请看到最后就能获取你想要的,接下来的是今日的面试题:
1.Flink 计算资源的调度是如何实现的?
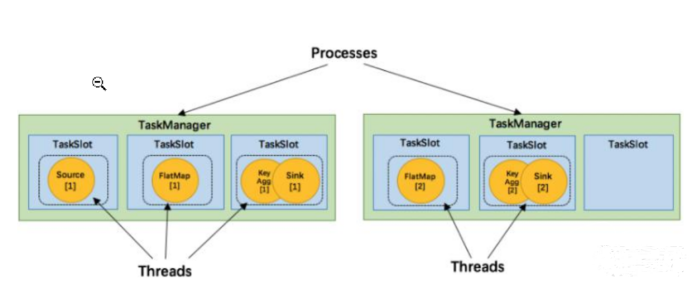
TaskManager中最细粒度的资源是Task slot,代表了一个固定大小的资源子集,每个TaskManager会将其所占有的资源平分给它的slot。
通过调整 task slot 的数量,用户可以定义task之间是如何相互隔离的。每个 TaskManager 有一个slot,也就意味着每个task运行在独立的 JVM 中。每个 TaskManager 有多个slot的话,也就是说多个task运行在同一个JVM中。
而在同一个JVM进程中的task,可以共享TCP连接(基于多路复用)和心跳消息,可以减少数据的网络传输,也能共享一些数据结构,一定程度上减少了每个task的消耗。每个slot可以接受单个task,也可以接受多个连续task组成的pipeline,如下图所示,FlatMap函数占用一个taskslot,而key Agg函数和sink函数共用一个taskslot:
2.简述Flink的数据抽象及数据交换过程?
Flink 为了避免JVM的固有缺陷例如java对象存储密度低,FGC影响吞吐和响应等,实现了自主管理内存。
MemorySegment就是Flink的内存抽象。默认情况下,一个MemorySegment可以被看做是一个32kb大的内存块的抽象。这块内存既可以是JVM里的一个byte[],也可以是堆外内存(DirectByteBuffer)。在MemorySegment这个抽象之上,Flink在数据从operator内的数据对象在向TaskManager上转移,预备被发给下个节点的过程中,使用的抽象或者说内存对象是Buffer。对接从Java对象转为Buffer的中间对象是另一个抽象StreamRecord。
3.Flink中的分布式快照机制是如何实现的?
Flink的容错机制的核心部分是制作分布式数据流和操作算子状态的一致性快照。这些快照充当一致性checkpoint,系统可以在发生故障时回滚。 Flink用于制作这些快照的机制在“分布式数据流的轻量级异步快照”中进行了描述。它受到分布式快照的标准Chandy-Lamport算法的启发,专门针对Flink的执行模型而定制。

barriers在数据流源处被注入并行数据流中。快照n的barriers被插入的位置(我们称之为Sn)是快照所包含的数据在数据源中最大位置。例如,在Apache Kafka中,此位置将是分区中最后一条记录的偏移量。将该位置Sn报告给checkpoint协调器(Flink的JobManager)。然后barriers向下游流动。当一个中间操作算子从其所有输入流中收到快照n的barriers时,它会为快照n发出barriers进入其所有输出流中。一旦sink操作算子(流式DAG的末端)从其所有输入流接收到barriers n,它就向checkpoint协调器确认快照n完成。在所有sink确认快照后,意味快照着已完成。一旦完成快照n,job将永远不再向数据源请求Sn之前的记录,因为此时这些记录(及其后续记录)将已经通过整个数据流拓扑,也即是已经被处理结束。
了解更多请点我头像或到我的主页去获得,谢谢