增量和全量同步该怎么选?
除了数据量大、更新频繁,还
有没有别的判断标准?
增量同步进来了,后面该怎么处理?
你有没有上面这些问题?
今天我就把自己的理解整理一下,希望能帮大家理清思路。
一、增量还是全量?
说实话,我第一次接触这个问题时,也以为数据量是唯一标准:表大了就用增量,小了就全量。后来才发现,最关键的判断标准是业务形态,也就是这张表里的数据到底怎么变。
你可以问自己下面这几个问题:
这张表的数据是只增不减,还是会频繁修改?
业务上需要随时拿到每条记录的最新状态吗?
数据量到底有多大,全量同步会不会把源库压垮?
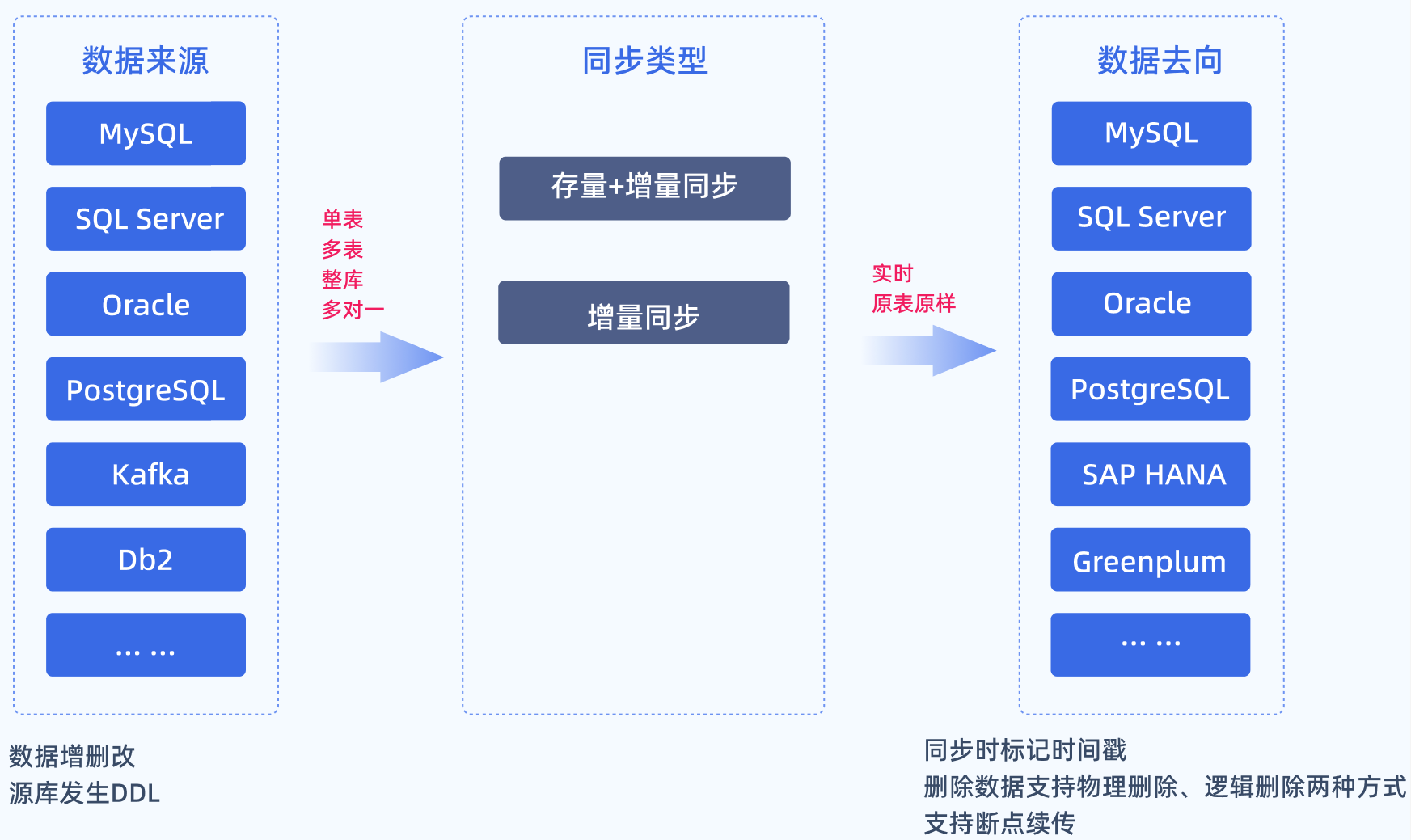
其实常见的业务表就三类。
第一类:只追加,不修改。
像用户访问日志、设备传感器数据、银行交易流水等等,这类数据生成后永远不会变,新数据在后面追加。
这种表天然就该用增量同步,每次同步只拉新增部分,历史数据完全不用动。即使数据量极大,增量也毫无压力。你懂我意思吗?
第二类:频繁修改,但主键不变。
典型的有员工表、订单状态表、配置表。
员工会转岗、升职,但工号不会变;
订单会更新状态,但订单号不变。
这种情况下,一条记录可能被修改多次。
如果只用全量,每天拉取整个表,数据量大时确实扛不住;
但只用增量,下游使用时又得自己拼凑每个主键的最新状态,想想就头疼。
说白了,这类表需要做增全量合并。
第三类:混合型,既有追加又有修改。
比如电商订单表:新订单不断生成,已支付、已发货的订单状态也会更新。这其实是第二种情况的变种,同样需要用合并策略。
所以,你判断用增量还是全量,第一步是看数据的变更规律。
二、增量同步需要关注的细节
如果你决定用增量,那就必须了解它的实现原理和潜在风险。我一直强调,增量同步能不能跑稳,关键看下面的这几个细节。
1、断点续传能力。
同步任务可能因为网络抖动、目标库压力大等原因中断。
现在有很多专业的同步工具会在本地记录已经同步的日志位点,比如MySQL的binlog文件名和偏移量,重启后能从中断的地方继续。
说白了,没有断点续传,一个网络波动就可能让你丢数据。
2、事务完整性。
源端的一个事务在目标端也必须作为一个事务执行,不能拆散。
如果一个事务里更新了10条数据,这10条更新要么全部成功,要么全部回滚,中间不能插入其他事务的操作。
这个细节很多人会忽略,但一旦出问题,数据一致性就崩了。
3、大事务处理。
要是源端一次性删除了100万条记录,那binlog里就是100万条DELETE语句。同步工具如果一条一条执行,目标端可能几个小时都追不上。
好的工具会对大事务做优化,比如批量提交或并行执行。
你想象一下,如果没这个优化,增量链路会堵成什么样?
4、日志保留策略。
增量同步依赖源库的日志文件。MySQL的binlog默认保留7天,如果你因为某种原因暂停同步超过7天,binlog被清掉,增量链路就断了,只能重新全量。
所以你要注意,生产环境必须做好延迟监控,确保时延在可控范围内。
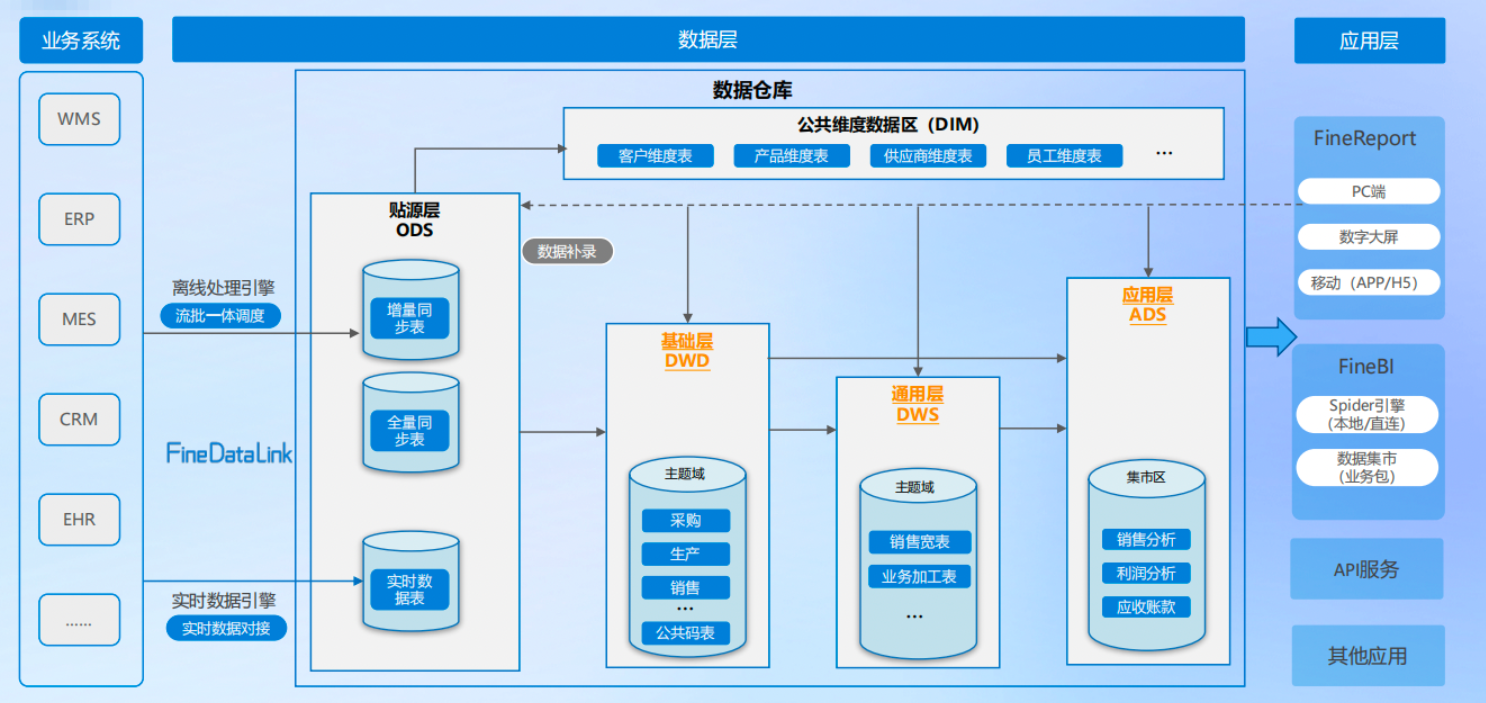
三、增量进了数仓,在哪一层转成全量?
这个问题经常有人问,我统一回答一下。
假设源系统员工表是增量同步到ODS层的,就是每天一个增量分区,记录当天新增和变更的员工数据。
下游报表需要查询员工当前的最新信息,如果直接把增量分区传给报表,报表逻辑就得自己去拼凑每个员工的最新状态,你说麻不麻烦?
业界标准做法是在DWD层做增全量合并,把每天的增量整合成一份全量快照。
简单来说,就是:
ODS层:保持原样。源系统给什么,ODS就存什么。如果源给的是增量,ODS就存增量分区。这样我们就能保留一份最原始的变更记录,方便数据回溯和对账。
DWD层:做合并操作。每天用前一天的DWD全量分区加上当天的ODS增量分区,合并生成当天的最新全量分区,写入DWD。
合并的逻辑其实不复杂:
就是取出前一天的历史快照、当天的变更记录,按主键合并,对于同一个主键优先取增量中的数据,因为它是最新状态。
用SQL实现的话,就是UNION ALL加ROW_NUMBER窗口函数。
经过DWD层的合并,下游的DWS、ADS层直接使用DWD的全量分区就行,逻辑大大简化了。听着是不是很合理?
四、如果下游还没需求,现在该做什么?
实际上,还有一种常见情况:
领导说,先把数据接进来,以后可能用。
这时候没有明确的业务需求,增量还是全量?在哪层合并?
最近我发现,很多团队遇到这种情况会凭猜测做复杂的清洗、合并,最后业务用不上,白白浪费资源。
用过来人的经验告诉你,这个阶段最正确的做法是:
先入ODS,熟悉数据。
把数据同步到ODS层落地,不做任何复杂的清洗转换。这一步是为了确保数据安全、完整地接入数仓。
花时间研究元数据:主键是什么?字段有哪些?空值率如何?数据量每天增长多少?有没有明显的变更模式?这些信息对后续建模至关重要。
要把观察到的特征记下来,形成文档。等业务方正式提需求时,你已经对数据了解得很清楚了,再根据需求设计DWD层的合并策略,就游刃有余了。
五、几条实战经验
讲完这些理论,我还想给你补充几条在项目中总结出来的经验。
1、增量与全量配合关系。
增量负责实时更新,定期全量负责核对和修复。哪怕增量链路再稳定,我也建议你每周或每月做一次全量校验,确保数据一致。
2、关注增量链路的延迟。
如果你的业务能容忍几分钟甚至几小时的延迟,增量同步会容易得多;
如果要求秒级同步,就需要对网络、工具、目标库性能做全面优化。
3、工具选型要看重断点续传和监控。
无论你用Canal、Debezium还是商业工具,断点续传和完备的监控告警是稳定运行的基础。
4、数据一致性校验不能省。
你一定要定期抽样对比源端和目标端的记录数、关键字段的汇总值,发现问题要及时修复。
数据同步这件事,看起来简单,做起来全是细节。增量与全量,是根据业务形态、数据量、下游需求做出的综合设计。