
引用
Tang Y, Liu Z, Zhou Z, et al. Chatgpt vs sbst: A comparative assessment of unit test suite generation[J]. arXiv preprint arXiv:2307.00588, 2023.
论文:https://arxiv.org/pdf/2307.00588.pdf
摘要
大语言模型(LLM)的最新进展表明,它在广泛的通用领域任务中取得了巨大成功,如问答和遵循指令。此外,LLM 在各种软件工程应用中也显示出了潜力。在本研究中,我们对 ChatGPT LLM 和最先进的SBST工具EvoSuite生成的测试套件进行了系统比较。我们的比较基于几个关键因素,包括正确性、可读性、代码覆盖率和漏洞检测能力。通过强调 LLM(特别是 ChatGPT)与 EvoSuite 相比在生成单元测试用例方面的优缺点,这项工作为了解 LLM 在解决软件工程问题方面的性能提供了宝贵的见解。总的来说,我们的研究结果强调了LLMs在软件工程中的潜力,并为这一领域的进一步研究铺平了道路。
1 引言
单元测试是一种被广泛接受的软件测试方法,旨在验证应用程序中各个单元的功能。通过使用单元测试,开发人员可以通过回归的方法在软件开发生命周期的早期阶段检测代码中的错误,并防止在代码修改的过程破坏现有功能。单元测试的主要目标是确认软件应用程序的每个单元是否按预期执行。这种测试方法有助于及早识别和解决问题来提高软件的质量和可靠性。
为了生成单元测试用例,基于搜索的软件测试(SBST)技术被广泛采用。SBST是一种利用遗传算和模拟退火等搜索算法创建测试用例的技术。SBST的目标是利用这些算法优化测试套件,产生一组提供广泛代码覆盖和有效检测程序缺陷的测试用例。与其他测试技术相比,SBST在减少测试用例数量的同时保持相同水平的缺陷检测能力方面表现出很高的效果。现今,SBST已成为提高软件测试质量和效率的有效方法,为软件开发人员简化测试流程提供了有价值的工具。
最近,大型语言模型(LLMs)在处理和执行日常任务方面表现出了明显的熟练度,如机器翻译、问答、摘要和文本生成,并且它的准确度令人印象深刻。这些模型几乎具有与人类相同的理解和生成类人文本的能力。一个实际的LLM应用示例是OpenAI的GPT-3(生成式预训练模型),它已经在大量互联网文本数据上进行了训练。它的实际实现,ChatGPT,在各种日常活动中被广泛应用,包括文本生成、语言翻译、问答和自动客户支持。ChatGPT已成为许多个人的重要工具,简化了各种任务并提高了整体效率。此外,LLMs可以借助开发人员/测试人员编写的大量真实世界测试用例来生成程序的单元测试用例。这允许验证软件应用程序中各个单元的预期功能。LLMs在SE任务中的整合展示了它们的多功能性和改进软件开发过程的潜力。
尽管SBST在生成单元测试方面表现良好,但对于经验有限的测试人员来说,仍存在较大学习成本。因此,对于新手测试人员来说,这可能是采用SBST技术的最大问题。然而,基于大型语言模型的应用可以几乎不需学习成本地完成相同的任务(即生成测试套件)。然而,目前尚不清楚SBST生成的单元测试用例是否可以与先进的人工智能模型和技术进行比较。例如,LLM生成的测试用例是否可读、可理解、可靠,并且是否可用于实践。在本文中,我们对理解由LLM生成的测试套件的优势和劣势感兴趣。具体而言,我们利用最先进的GPT-3模型的产品ChatGTP作为LLM的代表进行比较。更重要的是,本文旨在从两个方面获得结论:(1)我们渴望从大型语言模型中学习知识以改进最先进的SBST技术,(2)我们也对发现现有大型语言模型在生成测试套件方面的潜在限制感兴趣。
2 方法设置
2.1 使用ChatGPT生成单元测试用例
在ChatGPT的帮助下,我们能够自动为程序生成单元测试用例。不幸的是,目前还没有关于如何使用ChatGPT自动生成单元测试用例的标准或指导方针。因此,我们采用以下步骤来学习使用ChatGPT生成单元测试用例的合理做法:
第一步:收集利用LLM(例如ChatGPT)从各种来源自动生成单元测试用例的现有工具,包括Google、Google Scholar、GitHub和技术博客等;第二步:分析这些工具中使用的短语和描述,以促使LLM生成测试用例。这一部分涉及分析源代码、阅读代码块和学习技术文档;第三步:通过ChatGPT验证在第二步收集的短语和描述,排除无效的短语和描述;通过第一至第三步,我们得到了以下能够为代码段生成单元测试用例的代表性表达:
表达式1:“为 ${input} 编写一个单元测试”,其中代码段为输入;表达式2:“你能使用JUnit为 ${input} 创建单元测试吗?”其中代码段为输入;表达式3:“为以下Java代码创建一个完整的测试,包括测试用例:${input}?”其中代码段为输入;基于上述发现,我们总结了我们的提示语为:“为以下代码中的方法编写一个JUnit测试用例(每个方法一个测试用例):${input}?”其中代码段为输入。请注意,为了模拟真实世界的实践,我们并不打算比较和评估ChatGPT提示以构建最佳的提示。相反,我们只是打算为ChatGPT构建一个合理的提示,以模拟开发人员在真实环境中如何使用ChatGPT。
2.2 研究的其他设置
EvoSuite的设置:EvoSuite提供许多参数(例如,交叉概率、种群大小)来运行算法。在本文中,为了评估和比较Evosuite和ChatGPT之间的性能,我们保留了Evosuite的默认设置。由于Evosuite利用遗传算法来选择和生成测试用例,为了减少随机性引入的偏差,我们对每个类运行30次。
ChatGPT的长输入设置:ChatGPT的最大输入长度为2,048个标记,大约相当于340-350个单词。如果提交的输入过长,ChatGPT会报错并且不给出响应。在这种情况下,我们尝试将整个类按方法拆分,并要求ChatGPT为方法生成单元测试用例。然而,通过将整个类按方法拆分来生成测试用例并不是一个好的做法,因为ChatGPT无法感知到有关整个类的某些信息。因此,这会影响生成的测试用例的质量。在这里,我们将最大长度设置为4,096个标记。也就是说,如果一个类的长度大于4,096个标记,我们会将其丢弃。
环境设置:EvoSuite的实验是在一台配有Intel(R) Core(TM) i9-10900 CPU @ 2.80GHz和128 GB RAM的机器上进行的。
3 实验评估
研究问题。在本文中,我们研究以下研究问题:
RQ1(正确性):ChatGPT提供的单元测试套件建议是否正确?RQ2(可读性):ChatGPT提供的测试套件有多易理解?RQ3(代码覆盖率):ChatGPT在代码覆盖率方面与SBST相比表现如何?RQ4(漏洞检测):ChatGPT和SBST生成的测试套件在检测漏洞方面有多有效?数据集设置:为了减少选择的生成测试用例对主题代码的偏见,我们重复使用了现有研究中用于评估EvoSuite性能的现有基准。在这里,我们使用了DynaMOSA(Dynamic Many-Objective Sorting Algorithm)中提出的基准。该基准包含来自117个项目的346个Java类。然而,根据其他研究报告内容,我们发现SF100数据集中的一些项目可能已经过时并不再维护。由于一些Dynamosa数据集中所需的类缺失或不公开可用,一些项目无法构建和编译。因此,我们移除了38个项目,保留了79个项目,其中包含248个Java类。此外,我们使用了与Java相关的最先进的缺陷数据库,即Defects4J。它包含来自17个开源项目的835个缺陷。
Answer to RQ1
动机:我们需要检查ChatGPT返回的用于测试给定程序/代码段的测试用例是否正确。
方法:为了测试生成的测试用例的正确性。我们从三个方面对它们进行评估:
(1)ChatGPT是否成功返回每个待测试输入的测试用例;
(2)这些测试用例是否可以编译和执行;
(3)这些测试用例是否包含潜在的错误。
具体来说,对于(2),可以借助Java虚拟机(JVM)进行检查。我们编译和执行测试用例,看看JVM是否报告错误。对于(3),我们依赖于最先进的静态分析器SpotBugs,来扫描ChatGPT生成的测试用例,找出这些测试用例是否包含潜在的错误或漏洞。SpotBugs是FindBugs的后继者(一个已经放弃的项目),是一个开源的静态软件分析器,可以用于捕获Java程序中的错误。它支持超过400种错误模式和不良编程实践。
RQ1的结果分析
我们发现ChatGPT能够成功为所有207个Java类生成单元测试用例,而不报告任何错误。在这些测试用例中,有144个(69.6%)测试用例可以在不需要额外人力的情况下成功编译和执行。我们邀请了两位具有Java编程基础知识的本科生尝试使用IntelliJ IDE修复错误。对于剩下的64个测试用例,有3个测试用例没有背景知识的情况下不能直接修复,而60个测试用例可以在IDE的帮助下修复。具体来说,这3个测试用例的错误分为3类:
未能实现接口;未能初始化抽象类实例;尝试初始化内部类的实例。表1 60个测试用例中的错误类型

其他60个测试用例中的错误分为7类,如表1所示。在这里,调用未定义的方法表示调用一个在目标类中未定义的方法。表2显示了调用未定义方法错误的一些示例。调用未定义方法的根本原因是ChatGPT只给出了待测试类而不是整个项目。因此,ChatGPT在需要时必须预测被调用者的名称。当ChatGPT试图生成一些断言时,特别是这种情况。
表2 调用未定义方法的示例

总的来说,ChatGPT产生的编译错误主要是由于它未能全面了解整个项目。因此,ChatGPT试图预测被调用者的名称、参数、参数类型等。结果,导致了编译错误。
表3 Bug模式的优先级别

对于(3),我们利用最先进的静态分析器SpotBugs来扫描ChatGPT生成的测试用例。如表4所示,大多数错误(85.11%)属于关注级别。只有8个测试用例(3.9%)具有最可怕级别的错误。
表4 Bug模式

从错误模式的角度来看,发现的错误分为7类:(1)不良实践;(2)性能;(3)正确性;(4)多线程正确性;(5)可疑代码;(6)国际化;以及(7)实验性。根据我们的结果,主要涉及以下3种情况:空指针解引用、数组越界访问和未使用的变量。
总之,从错误优先级和错误模式来看,我们可以得出结论,大多数(61.2%)由ChatGPT生成的测试用例是无错误的。只有20个(9.8%)测试用例属于最可怕和可怕级别。
总结
在生成的207个Java测试用例中,有69.6%可以在没有人为干预的情况下编译和执行。然而,有3个测试用例在不理解目标程序的情况下无法修复,而60个可以借助IDE修复。经过分析ChatGPT生成的测试用例的错误优先级和错误模式,可以推断出其中大多数情况,具体来说是61.2%,都没有任何错误。然而,只有很少一部分测试用例,仅占9.8%,被归类为最可怕和可怕级别,表明存在严重问题。Answer to RQ2
动机:分析ChatGPT生成的代码的可读性是为了确保人类开发人员可以轻松地维护、理解和修改它。
方法:对于这个RQ,我们设置了两个子任务:
(1)代码风格检查;
(2)代码可读性。
为了检查生成的测试用例的代码风格,我们依赖于支持Java的最先进的软件质量工具:Checkstyle。在这里,我们利用两种标准(即Sun Code Conventions和Google Java Style)与Checkstyle一起,检查ChatGPT生成的测试套件是否遵循这些标准。
对于代码可读性,我们使用了认知复杂度和圈复杂度作为指标,用于衡量代码片段的可理解性。
RQ2的结果分析
代码风格检查结果
Checkstyle-Google:图1中的雷达图将违规问题按类型进行了细分以显示详细信息。如图1所示,我们可以得出以下结论:
缩进是最常见的代码风格违规,表明ChatGPT可能需要努力保持代码的一致格式以提高可读性和可维护性;文件制表符和自定义导入顺序也经常出现违规,这突显了在代码结构中适当配置和一致性的重要性;与代码可读性和易读性相关的违规,如LineLength和AvoidStarImport,不应被忽视,以保持高标准的代码质量。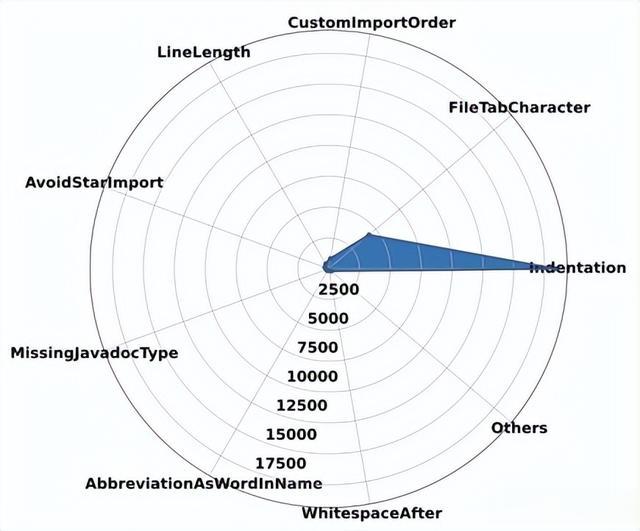
图1 Google Code Style违规的雷达图
Checkstyle-SUN:图2中的雷达图将违规问题按类型进行了细分以显示详细信息。根据图中的信息可以得出结论,作为一个人工智能语言模型,ChatGPT在生成测试用例时可能没有遵循特定的代码风格。然而,测试用例的代码风格可以受到生成过程中设置的参数和规则或提供给模型的输入的影响。这也表明程序员在使用由ChatGPT生成的测试用例时应该注意代码风格。

图2 Checkstyle-SUN违规的雷达图
总结:在考虑1K和全面策略时,仅代码预训练的MEM-{NO+LANG}-[LANG]-(LANG)在MRR和Aroma分数方面表现优于仅查询预训练的MEM-{EN+NO}- LANG]-(LANG)。然而,在1K策略和MRR分数的情况下,LUCENE仍然是JAVA和JAVASCRIPT的最佳模型,而MEM-{NO+PY}-[PY]-(PY)的表现与DEEPCS相似。在全面策略的情况下,仅代码预训练的MEMs在每种语言上仍然落后于LUCENE。
代码理解
PMD中默认的圈复杂度和认知复杂度阈值分别为10和15,这意味着如果一个类/方法的圈复杂度和认知复杂度低于这些值,系统就不会报告问题。因此,我们建立了一系列自定义规则来衡量复杂性。
认知复杂度:根据SonarSource的技术报告[42],认知复杂度可以分为四类:低(<5认知复杂度)、中等(6-10)、高(11-20)和非常高的复杂性(21+)。如表6所示的结果,所有方法的复杂度都很低。
圈复杂度:根据PMD的官方文档[41],圈复杂度可以分为四类:低(1-4认知复杂度)、中等(5-7)、高(8-10)和非常高的复杂性(11+)。如表7所示的结果,有来自204个类的3300个方法具有低复杂度,来自2个类的2个方法具有中等复杂度。
因此,基于上述结果,我们可以得出结论:ChatGPT生成的测试用例非常容易理解,并且具有低复杂度。
总结
Checkstyle-Google规则:中位数约为70(违规)。四分位距(IQR)落在大约30到175之间,表明大多数数据位于这个范围内。此外,缩进是最常见的代码风格违规;Checkstyle-SUN规则:数据的中位数约为28(违规),有25%的数据在15以下,75%的数据在55以下。两种最常见的编码问题是MissingJavadocMethod和MagicNumber,分别出现了2742和2498次;代码理解:从认知复杂度的角度来看,所有方法都具有低复杂度。从圈复杂度的角度来看,几乎所有方法(3300中的3302)都具有低复杂度,另外2个方法具有中等复杂度。因此,ChatGPT生成的测试用例非常容易理解,并且具有低复杂度。Answer to RQ3
动机:低覆盖率意味着某些代码部分尚未经过检查,而高覆盖率则表明生成的测试已经彻底评估了代码。比较ChatGPT生成的测试套件与SBST之间的代码覆盖率可以让我们评估和评估ChatGPT生成的测试套件。
方法:JaCoCo测量指令和分支覆盖率。指令覆盖率与Java字节码指令相关,因此类似于源代码的语句覆盖率。我们使用指令覆盖率(即语句覆盖率(SC))来评估代码覆盖率,因为JaCoCo对分支覆盖率的定义仅计算条件语句的分支,而不是控制流图中的边。
RQ3的结果分析
根据实验设置,我们删除了41个类,剩下了来自75个项目的207个Java类。我们对EvoSuite运行了30次,并计算了最大值、最小值、平均值和平均标准偏差。如表4和5所示,对于Evosuite,所有项目的平均最大SC可以达到77.4%;所有项目的最小SC可以达到70.6%;所有项目的平均SC可以达到74.2%。相比之下,对于ChatGPT,所有项目的平均SC可以达到55.4%。总的来说,Evosuite在SC方面表现优于ChatGPT 19.1%。此外,ChatGPT在75个项目中有10个(13.33%)项目的表现优于Evosuite,这些项目在表4和5中突出显示出来。从类的角度来看,ChatGPT在207个类中有37个(17.87%)的类的表现优于EvoSuite。
表4 项目(I)的代码覆盖率
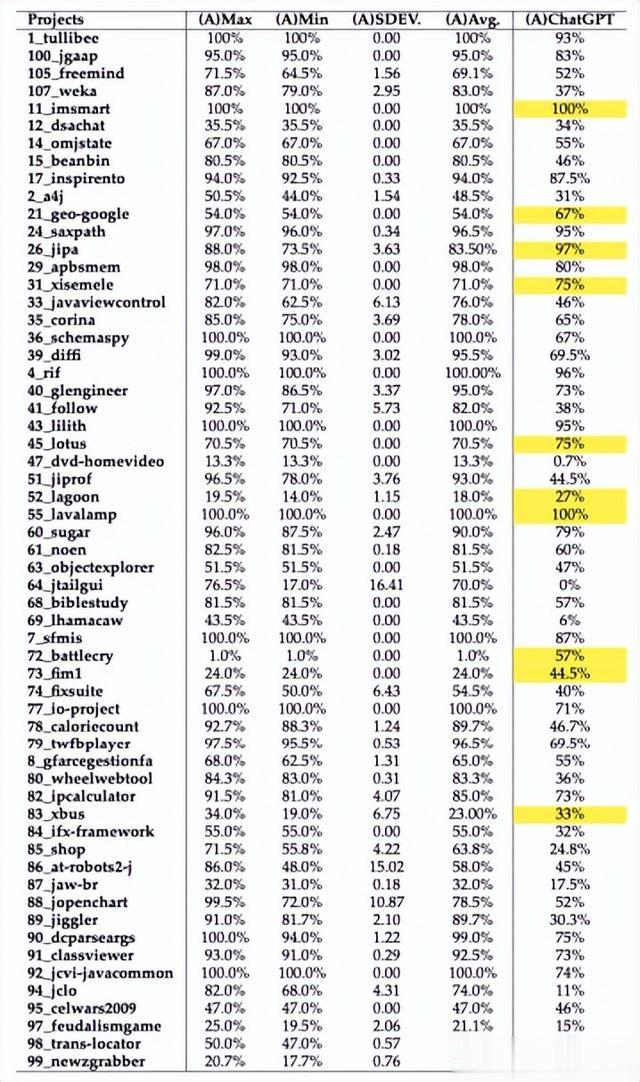
表5 项目(II)的代码覆盖率

不幸的是,我们未能看到ChatGPT在大型类上表现优于EvoSuite。这表明,无论是大型还是小型类,开发人员都建议使用EvoSuite来获得更高的代码覆盖率。潜在的原因可能是多种多样的。一些可能的原因包括:(1)规范不完整:ChatGPT只接收到待测类而不是整个项目。因此,缺少整个项目的信息,ChatGPT很难生成更有价值的测试用例;(2)缺乏反馈机制:与EvoSuite不同,后者可以从反馈(即覆盖数据)中学习,而ChatGPT仅依赖于训练数据。这使得ChatGPT难以通过迭代过程理解测试结果的反馈,从而导致测试覆盖率较低。
然而,结果也提供了两个见解:
见解1:作为一种人工智能助手,ChatGPT具有从待测代码中理解感知语义和上下文的强大能力。这意味着ChatGPT可以有效地辅助生成测试数据。通过将人工智能模型或自然语言处理(NLP)模块嵌入搜索驱动软件测试(SBST)工具中,ChatGPT可以大大提高SBST工具的性能。这是因为工具将能够理解和解释复杂的代码结构,并根据其生成更准确、更有效的测试用例。因此,开发人员可以从更快、更有效的测试和更可靠的软件产品中受益;见解2:尽管无法与EvoSuite相比,但ChatGPT仍然可以达到相对较高的代码覆盖率(55.4%)。因此,ChatGPT仍然可以作为新手测试人员的入门工具或备选方案。总结
对于Evosuite,所有项目中最高的语句覆盖率可以达到77.4%;最低的语句覆盖率可以达到70.6%;平均语句覆盖率可以达到74.2%。相比之下,对于ChatGPT,平均语句覆盖率可以达到55.4%;在检查了37个ChatGPT优于EvoSuite(在代码覆盖率方面)的案例后,我们的分析表明了六种可能情景,ChatGPT可能更适合。这些发现有助于日益增长的研究领域,探索自动化测试工具的有效性;实验结果表明,Evosuite在大型类案例和小型类案例中都远远优于ChatGPT,可以达到更高的代码覆盖率;低代码覆盖率的两个潜在原因可能是:规范不完整;和缺乏反馈机制。Answer to RQ4
动机:生成的测试套件的主要用途是在程序中查找错误代码。因此,我们评估了生成的测试套件在检测错误方面的有效性。
方法:为了评估生成的测试套件在检测错误方面的有效性,我们首先为目标类生成单元测试套件,并检查测试套件是否能够成功捕获Defects4J基准测试中的错误。值得注意的是,在这个RQ中,为了公平起见,我们只运行一次EvoSuite来生成测试用例。
RQ4的结果分析
Defects4J中的一些错误是逻辑错误,它们通过断言触发。不幸的是,我们发现有时ChatGPT生成的断言不可靠。图3说明了Time项目中Period的一个测试用例。

图3 时间项目的测试用例
断言语句assertEquals(1000, p.getMillis();是不正确的。然而,被测试的代码片段没有错误,期望的值应该是0而不是1000。ChatGPT对这种情况做出了错误的断言。这意味着我们不能完全依赖ChatGPT生成的测试用例中的断言来确定错误是否被成功触发。值得注意的是,ChatGPT能够在一些情况下检测到EvoSuite未能检测到的错误,这表明这两种工具可能互补,可以共同用于改进错误检测。 通过比较ChatGPT和EvoSuite生成的测试用例,我们找到了几个可能的原因,即LLM(例如ChatGPT)可能不如Evosuite:
由于ChatGPT的输入只能是被测试的类,而不是整个项目(例如jar文件),因此ChatGPT很难生成复杂的实例,这可能导致测试用例无法生成边缘情况以探索错误;作为一个大型语言模型,ChatGPT生成/预测的内容需要一个提示或起始文本作为输入,并使用其对语言的学习理解来预测接下来应该出现的单词或短语。这种预测是基于某个单词序列出现在数据集中的概率。一个常用情况(在我们的语境中即为测试用例/数据)的概率很可能比一个边缘情况的概率更高;Evosuite通过采用遗传算法来探索能够实现更高代码覆盖率的潜在测试套件,理论上可能具有更大的发现错误的概率。值得注意的是,目前在LLM(例如ChatGPT)中缺乏这样的反馈。总结
ChatGPT生成的测试用例可能在发现与逻辑相关的错误方面具有误导性,因为生成的断言可能是不正确和不可靠的;在212个错误中,ChatGPT生成的测试用例成功检测到了44个,平均语句代码覆盖率为50%。相比之下,EvoSuite生成的测试用例成功检测到了55个错误,平均语句代码覆盖率为67%;Evosuite集成了遗传算法来找到能够提供更好代码覆盖率并增加发现错误机会的测试用例。而像ChatGPT这样的LLM工具没有这种反馈机制。因此,结合SBST技术和LLM可以提高软件测试的准确性和错误检测能力。转述:何家伟