
Nathan Lambert与Sebastian Raschka是机器学习研究员、工程师、教育家,Nathan是艾伦AI研究所的后期训练负责人,是《The RLHF Book》作者,Sebastian Raschka是从零构建LLM与从零构建推理模型的作者。
2026年2月1日,两人在Lex Fridman播客畅谈2026年AI新纪元。
全球AI格局已进入白热化阶段,中国力量DeepSeek、月之暗面、MiniMax、千问等通过开源策略强势崛起,美国巨头在闭源商业化领跑,领先绝非单一维度的竞赛,算力、数据、战略布局成为决定性分水岭。
本期长期主义,选择Nathan Lambert与Sebastian Raschka访谈纪要上篇,瓜哥AI新知发布,六合商业研选精校,分享给大家,Enjoy!
正文:
全文20,360字
预计阅读41分钟
Lex与AI研究员对谈AI江湖 上篇:中美竞争、大厂PK、开源、模型架构演进、训练、硅谷996
时间:2026年2月1日
来源:瓜哥AI新知
字数:20,360
Nathan Lambert与Sebastian Raschka是机器学习研究员、工程师、教育家,Nathan是艾伦AI研究所的后期训练负责人,是《The RLHF Book》作者,Sebastian Raschka是从零构建LLM与从零构建推理模型的作者,两人在Lex Fridman播客畅谈2026年AI新纪元。
内容提要
全球AI格局与领跑者:国际AI军备竞赛处于白热化阶段,DeepSeek、智谱AI、MiniMax等中国企业在开源模型领域异军突起,表现抢眼;美国OpenAI、Google、Anthropic在闭源模型与商业化产品落地方面保持领先。
我们必须认识到,领先绝非单一维度的竞赛。技术壁垒随着知识自由流动而消融,预算规模与硬件储备是决定性分水岭。
中国企业发布开源模型不仅是技术展示,更是一种极具深意的战略布局,旨在深度参与美国市场,重塑国际影响力。
模型演进的未来趋势
开源力量的觉醒:中国公司积极开源具有前沿权重的强大模型,DeepSeek、Kimi、MiniMax、智谱AI的GLM系列等力量的加入,极大推动全球开源AI生态的繁荣。
架构的持续进化:Transformer架构稳居主流,为追求极致效率与性能,专家混合MoE、分组查询注意力GQA、滑动窗口注意力机制、RMS范数等创新技术已被广泛融合。
决胜后训练Post-training:监督微调SFT、人类反馈强化学习RLHF、带有可验证奖励的强化学习RLVR,被认为是提升模型能力的关键。特别是RLVR,通过让模型进行自我评估与迭代优化,成为提升数学与编程任务准确率的杀手锏。
推理侧扩展Inference-time scaling:让模型思考得更久一点,通过增加推理时计算量,如生成更多的思维链Token,模型能够进行更深度的逻辑推理与工具调用,显著提升能力上限。
无限延伸的上下文:模型上下文窗口,从8K飞跃至100K Token甚至更长。处理超长文档与复杂任务的能力,将是未来模型核心竞争力。
工具使用与代理能力:LLM不再是孤岛,它们能够熟练调用计算器、Python解释器、网络搜索等外部工具来解决问题。这不仅减少幻觉,更提高信息可靠性,工具调用能力的强弱,或许将成为开源与闭源模型分水岭。
文本扩散模型的探索:作为Transformer潜在挑战者,文本扩散模型有望在效率与成本上实现突破,在生成质量与处理复杂推理任务上,面临不小挑战。
世界模型World Models:通过在虚拟沙盒中运行世界模拟来训练模型,或许能解锁LLM尚未被发掘的潜力,实现更复杂的因果推理与建模。
训练数据的炼金术
预训练Pre-training:成本高昂,预训练是基石。数据质量优于数量,经过严选的互联网数据、书籍、学术论文、高质量的重写内容,比单纯的数据堆砌更具价值。
中期训练Mid-training:为避免灾难性遗忘,模型训练开始转向更专业化的中期阶段,专注特定任务,如长上下文处理与高纯度数据。
后训练Post-training的艺术:RLHF、RLVR、DPO、指令微调等技术,在精细打磨模型的技能树、语言风格与用户交互体验。
合成数据的崛起:从PDF提取到Reddit语料,再到ChatGPT生成的合成数据,数据来源日益多元。如何对这些数据进行筛选、重写、格式化,是决定模型成败的关键。
数据污染的隐忧:基准测试中存在作弊现象,当模型在训练数据中见过高度相似题目时,评估结果便会失真,这给RLHF与RLVR的真实效果评估,蒙上一层阴影。
算力与基础设施
能源饥渴:AI的指数级发展,面临巨大的能源瓶颈,构建包括先进核能在内的多元化能源结构迫在眉睫。
芯片战争:英伟达凭借GPU与CUDA生态,构筑宽广的护城河,Google TPU、Amazon Trainium等定制芯片的崛起,试图打破这一垄断。
天价成本:相比数百万~千万美元的预训练成本,为数亿用户提供实时服务的推理成本更是高达数十亿美元,这是商业化必须面对的现实。
系统级优化:FP8/FP4等低精度量化技术的应用,极大提升计算效率,为更大规模的训练与更快速的实验,铺平道路。
AI社会冲击与反思
编程范式的重构:Codex、Claude、Cursor等AI编程助手,极大提升开发效率,我们必须警惕,它是否剥夺人类通过挣扎来学习的机会,这可能会重塑程序员的职业成长路径。
知识传播的加速器:LLM让信息获取变得前所未有便捷,个性化教育与定制化方案的普及,有望在全球范围内加速科学发现与知识普惠。
生产力与失业的双重奏:AI自动化在带来巨大生产力红利的同时,可能引发大规模的技术性失业。全民基本收入UBI等社会保障机制的讨论,不再是遥远的设想。
商业模式的博弈:在开源与闭源并存的激烈竞争中,所有公司都面临盈利压力,API订阅、广告植入等多元变现模式,在被积极探索。
人机关系新定义:AI既是工具,也可能是未来的伙伴。人类独有的批判性思维、创造力、对困难的切身体验、人与人间的情感连接,依然不可替代。
伦理、安全、人类未来
版权与隐私的雷区:AI训练数据的来源,如授权数据vs Common Crawl抓取,持续引发版权与隐私的法律争议。
风险与末日论:从996工作制的加剧、信息茧房的固化,到生成有害内容,乃至AGI带来的未知风险,技术进步,始终伴随阴影。
英雄史观vs历史必然:技术进步是大势所趋,我们不能忽视黄仁勋、乔布斯、马斯克等关键人物,在加速历史进程中的独特作用。
AI的平庸化:RLHF与RLVR的平均化机制,可能导致AI失去深刻的洞见与原始研究者的个性化声音,生成的内容往往显得平淡无奇。
警惕信息糟粕Slop:当AI生成的劣质内容泛滥成灾,真实的人际交流、实体体验、原创艺术的价值会更加凸显,我们要避免沉溺算法编织的廉价多巴胺中。
保持人类的自主权:AI应是增强人类的工具,而非取代人类的主宰,用户必须时刻保持对技术的控制权与自主判断。
关于学习与成长的建议
纸上得来终觉浅:学习AI最好的方式是亲手从零构建一个模型,触摸每一个神经元的脉动,理解底层逻辑。
拥抱挣扎:不要试图跳过学习过程中的痛苦,真正的深度理解往往诞生于解决难题的挣扎之中,过度依赖AI速成答案,只会阻碍专家能力的养成。
AI辅助而非替代:LLM是极佳的学习脚手架,可以生成习题、解释概念,学习的主航道需人类自己掌舵。
研究方向与开源价值
深耕细作:在AI研究领域,与其泛泛而谈,不如在一个狭窄的垂直领域深耕,往往能创造更大的价值。
算力受限者的机会:即便计算资源有限,研究者仍可通过构建评估工具、挖掘模型弱点、优化数据质量等方式,做出重要贡献。
开源是创新的引擎:开源模型不仅推动技术透明与创新,更是全球人才培养与国际合作的基石。
机器人与具身智能
跨越虚实鸿沟:机器人领域面临的最大挑战是模拟到真实Sim-to-real的迁移,尤其是在安全性与泛化能力方面。
人机协作的未来:机器人将接管重复性劳动,人类将升级为系统的设计者与目标的定义者,专注创造性工作。
AGI与人类文明的走向
模糊的终点线:AGI与超级AI/ASI的定义依然模糊,目前更多是以能否在特定领域超越人类或能否替代大多数数字经济工作来衡量。
能力的不均衡:未来的AI可能是偏科的,在某些领域登峰造极,在另一些领域,如分布式协作仍显稚嫩。
连接是智能的基础:人类的紧密连接与信息的自由流动/互联网,是孕育AI智慧的土壤。
重估人类体验:AI的普及,或许会迫使我们重新审视人类存在的意义,面对面的交流、手工的温度与原创的艺术,将变得前所未有的珍贵。
访谈完整记录
Lex Fridman:接下来对话将围绕AI的最新进展展开,复盘过去1年中激动人心的技术突破,展望即将到来的1年中可能发生的有趣变局。
有些内容可能会比较硬核,我们会力求在不牺牲深度情况下,让非专业人士也能理解。
我非常荣幸能与AI领域,我最敬佩的两位专家,Sebastian Raschka与Nathan Lambert一起制作这期节目。他们不仅是备受尊敬的机器学习研究员与工程师,更是出色的传播者、教育家、作家。
Sebastian撰写了两本我强烈推荐给初学者与专业人士的书,《从零构建LLM》与《从零构建推理模型》。我坚信,在机器学习与计算机科学领域,通往真知的最佳路径,是亲手从零开始构建。
Nathan是艾伦AI研究所后期训练负责人,是关于基于人类反馈的强化学习RLHF的权威著作作者。
两位在X/Twitter与Substack上都非常活跃。
Sebastian在YouTube上开设课程,Nathan有一个播客,非常值得关注。
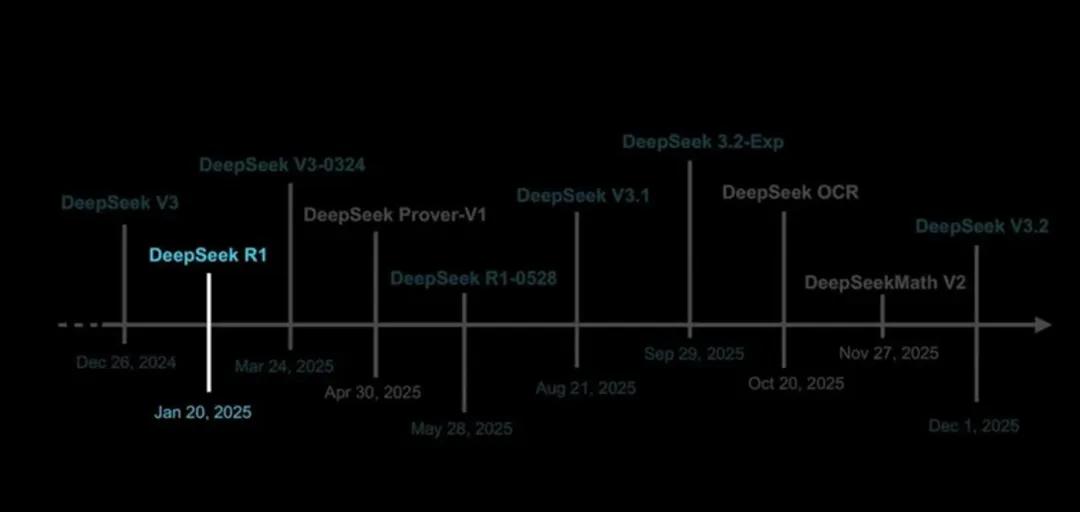
我认为审视这一切的有效切入点是DeepSeek时刻,发生在大约1年前,2025年1月,DeepSeek发布DeepSeek R1,它以接近、甚至达到顶尖水平的性能,更低的计算量与成本震惊业界。
从那时起,无论是研究层面、还是产品层面,AI领域的竞争,都进入白热化加速阶段。
今天我们来探讨这些话题,或许可以从一些尖锐的问题开始。
国际层面上,谁在领跑,是中国公司、还是美国公司?
Sebastian与Nathan,很高兴见到你们。Sebastian,你认为谁处于领先地位?
Sebastian Raschka:领先是个非常宽泛的概念,你提到DeepSeek时刻,DeepSeek凭借开源策略,赢得研究社区的青睐。
我认为领先需要分时间维度看,当下、2027年,还是10年后。
有一点我很确定,在2026年的今天,我认为不会有哪家公司能拥有其他公司无法获取的某种独门绝技,主要是研究人员在不同实验室与公司间频繁流动。
技术获取层面,不会有绝对的赢家。
我认为真正的差异化因素,将在于预算与硬件限制。我不认为创意会成为独家秘密,实现创意所需的算力与资源壁垒将依然存在,我目前看不到赢者通吃的局面。
Nathan Lambert:各大实验室都在各自的目标赛道上投入不同的精力。
就我们录制节目的当下,大家对Anthropic的Claude Opus 4.5模型的热议程度简直疯狂。我最近几周,也在使用它,并基于它进行开发。关于它的热度,甚至已经演变成一种网络迷因Meme。
这非常有趣,是行业发展的自然规律。回顾几个月前,Google发布Gemini 3。当时的市场营销与公众的惊叹效应非常高,所有人都惊呼,这是Gemini重塑Google在AI领域结构性优势的时刻。
Gemini 3是非常棒的模型,我至今仍在用,随后Claude Opus 4.5发布,热度迅速转移,大家现在似乎不再怎么谈论Gemini,它的差异化优势被稀释。
我同意Sebastian观点,创意空间是自由流动的,往往受限人力与组织文化。
文化上看,Anthropic押注代码能力的策略Claude Code奏效了。即便想法可以流动,执行力往往被组织架构所瓶颈。
Anthropic目前展现出的形象,最为清晰、混乱最少,只要能保持这种状态,这是一种优势。
另一方面,中国涌现出许多令人瞩目的技术,远不止DeepSeek一家。DeepSeek在中国引发了一场运动,类似ChatGPT在美国引发万物皆可聊天机器人的浪潮一样。
现在中国有大量科技公司,发布非常强大的前沿开源权重模型,以至于我认为DeepSeek在失去作为中国开源模型绝对霸主的王冠。
零一万物、MiniMax、月之暗面Moonshot AI,尤其是在近几个月,都展现出更强的竞争力。
DeepSeek的新模型依然强大,这标志着一个重要的叙事节点,2025年DeepSeek崛起,随之而来的是更多中国公司发布卓越模型,开启了一种新的运营模式。
这些中国公司的模型是开源权重的,这对美国公司的商业模式构成潜在风险。目前,美国用户愿意为AI软件付费,历史上,中国与其他地区的用户付费意愿相对较低。
Lex Fridman:类似DeepSeek这类模型受欢迎,核心在于它们是开源权重的。你认为中国公司发布开源权重模型的策略,还会持续多久?
Nathan Lambert:我认为会持续几年。类似在美国一样,目前没有清晰的商业模式。
我一直关注开源模型,中国这些公司非常聪明,他们意识到同样的限制,出于安全考虑,许多美国科技公司与IT企业不会向中国公司支付API订阅费用,这是科技行业长期存在的惯例。
这些公司将开源权重模型视为一个切入点,试图借此影响参与美国庞大、不断增长的AI支出市场。他们对此非常务实,这套策略奏效。
我认为政府也会看到,这在技术普及方面,在建立巨大的国际影响力,会有维持这种模式的动力。
构建这些模型,并进行研究的成本极其高昂。我预计未来会出现市场整合,这应该不是2026年的故事。
到2026年,开源模型构建者的数量,会比2025年更多,许多著名的模型都将来自中国。
Sebastian Raschka:你提到DeepSeek失去王冠,某种程度上我也要说,它们略微领先。
并非DeepSeek变差,是其他人在借鉴DeepSeek的想法。例如Kimi,采用相同的架构进行训练,出现交替领先的现象。也许某个时间点,其他家会更好,它们发布更新的模型。我认为又回到那个事实,不会有永远的赢家。你方唱罢我登场,最新、最流行的模型往往是最好的模型。
Nathan Lambert:我们也会看到中国公司有不同的动机。DeepSeek非常神秘,MiniMax与01.ai这样初创公司,已经准备IPO文件,试图获得西方的影响力,进行大量的外展活动。
DeepSeek据说是一家对冲基金幻方量化High-Flyer Capital开发的,我们不清楚他们的喜不知道他们用这些模型做什么,或者他们是否在乎商业化。
Lex Fridman:他们在沟通上是保密的,在描述模型原理的技术报告方面很开放。
我们应该谈谈关于Claude Opus 4.5的炒作,有一层是它成为X/Twitter信息回声室的宠儿,这与实际使用人数是两码事。
ChatGPT与Gemini专注只想在日常生活中解决问题的广泛用户群,这个群体是巨大的。关于编程能力的极客式炒作,可能没有体现在大众实际使用中。
Sebastian Raschka:我认为,很多使用习惯,源于品牌认知度与某种肌肉记忆。ChatGPT已经存在很长时间,人们习惯使用它,这类似飞轮效应,用户会向其他人推荐它。
另一个有趣观点是LLM的定制化与场景隔离。例如,ChatGPT有记忆功能,你可能有订阅并用于个人事务。我不确定你是否想在工作中使用同一个账号,这涉及隐私与工作界限。
如果你在一家公司工作,他们可能不允许混用,或者你自己也不想。
未来我们可能会有多个订阅,一个用于纯粹的工作代码环境,不保留个人图片或个人爱好项目;另一个用于处理你的个人事务。这并不意味着非此即彼,我认为未来会是多模型并存的局面。
Lex Fridman:你认为哪个模型赢得2025年,哪个模型将赢得2026年?
Nathan Lambert:在消费者聊天机器人的背景下,问题在于是否愿意押注Gemini能赢过ChatGPT。直觉告诉我,这有点冒险,OpenAI一直是市场领导者,拥有显著的先发优势。
我认为到2025年,势头似乎在Gemini这边,那是建立在它们起点较低的基础上。不管是早期的Bard,还是其他尝试,我为他们能够克服组织混乱、取得进展,给予极大的赞扬。
对抗OpenAI依然很难,OpenAI内部总是显得很混乱,他们非常擅长推出产品。
我对GPT-5评价非常复杂,它为OpenAI节省大量资金,它的主要功能是充当一个路由器,这使得大多数用户不再类似以前消耗昂贵的GPU成本。
我很难将我作为极客喜欢的模型特性,与对大众真正重要的特性区分开来。
Lex Fridman:差异化因素。你认为2026年会怎样,谁会赢?
Nathan Lambert:我会冒点风险预测一下。
我认为Gemini将继续在追赶ChatGPT方面取得进展,Google规模是巨大的,当两者都在如此极端的规模下运行时,Google似乎能够更好将前沿研究与产品开发分离开来,保持稳健的迭代。
关于OpenAI,我们听到很多消息,称内部运营混乱,一味追逐高影响力的项目,这是非常典型的初创公司文化。
在软件与企业服务领域,我认为Anthropic将继续取得成功,他们一再证明自己为此做好充分准备。
谷歌云产品众多,我认为Gemini品牌对他们至关重要。谷歌云的表现依然强劲,在整个生态系统中,它的处境更为复杂,它是在与Azure、AWS这样的巨头竞争,而不仅是与其他模型提供商竞争。
Lex Fridman:在基础设施方面,你认为TPU是否具备优势?
Nathan Lambert:主要原因是英伟达芯片的利润率极高,谷歌可以从头到尾开发适配自身技术栈的产品,无需支付溢价。他们在构建数据中心方面,拥有先发优势。
在这些需要漫长交付周期与高昂成本的高利润领域,谷歌拥有历史性的优势。
如果说会出现新的范式,很可能来自OpenAI。他们研究部门一次又一次证明,他们能够推出全新的研究理念或产品。类似DeepResearch、Sora、O1思考模型,所有这些定义时代的产物,都出自OpenAI,这是他们组织的核心竞争力之一,很难与他们抗衡。
我认为,2026年主题,将在很大程度上围绕规模化,优化模型中被描述为低垂果实的部分。
Lex Fridman:智能与速度间存在权衡,这是GPT-5在幕后试图解决的问题,大众究竟想要极致的智能,还是想要更快的速度?
Sebastian Raschka:我认为最好的方案是提供多样性,或者有一个切换开关。
以我个人为例,大部分时候,我只是快速查阅信息,会用ChatGPT的快速模型。
对大多数日常任务,自动模式已经相当不错,不需要显式开启思考功能。
我也需要深度辅助,当我写完东西后,我会把它丢给ChatGPT,让它做彻底检查,引用对吗,逻辑通顺吗,格式有误吗,图表编号对吗,这种任务我不急,我可以吃完晚饭再回来,让它慢慢跑。
我认为拥有选项很重要,如果每次查询都要等10~30分钟,我会疯掉的。
Nathan Lambert:我经常觉得不可思议,你们竟然还会用非思考模式,我简直无法忍受,这是我的反应。
我是ChatGPT重度用户,我从不碰非思考模式。我觉得它们的语气与易错性很有问题,出错的几率,明显更高。
自从OpenAI发布O3,那个首款能进行深度搜索、整合多源信息的模型后,我习惯这种模式。
无论是查找论文、还是代码参考,我只用GPT-5.2的思考模式或Pro版本。我通常会同时开启5~6个Pro模式查询,分别针对特定论文、对某个公式的反馈或类似需求。
Sebastian Raschka:我有个有趣的经历。
当时我急需一个答案,我们要出门旅行,我得在播客录制前搞定。家里有个本地GPU在跑长期强化学习实验,我通常离家前,会拔掉闲置设备,结果不小心把GPU电源拔了。
当时我妻子已经在车里等我了,我心想糟了。我需要一个最快的Bash脚本,来重新串联实验与评估。我懂Bash,但在紧迫时刻,我只想花十秒钟拿到命令。
Lex Fridman:这场景太滑稽了,你最后用了什么?
Sebastian Raschka:我用了最快的非思考模式,它给了我一个串联脚本的命令,还包含重定向日志。当时真是火烧眉毛,平时我自己也能写出来。
Lex Fridman:说真的,这种妻子在车里等你,你却得跑去插GPU,并生成Bash脚本的场景,听起来完全类似电影情节。
Nathan Lambert:我一般用Gemini处理这类快速查询,或者本来能Google到的信息。它擅长解释,知识库深厚,且易于使用。Gemini的APP体验越来越好。
至于代码或哲学讨论,我用Claude Opus 4.5,总是开启扩展思考Extended Thinking。扩展思考与推理时间缩放能,让模型稍微更聪明一些。
当技术进步幅度很大时,我总是倾向使用最强功能,你不知道它们何时会解锁新用法。
有时我会用Grok获取实时信息,或者挖掘我以前在X/Twitter上看过的内容,我对此特别执着。Grok 4 Pro发布时非常惊艳,由于肌肉记忆,我还是习惯性打开ChatGPT,慢慢就忽略了它,我会混用各种工具。
Lex Fridman:我会用Grok 4进行一些硬核调试,处理其他模型搞不定的问题,它在这方面表现最好。
你说ChatGPT界面最对我,可能是惯性使然,我觉得Gemini界面更好,我喜欢它的大海捞针能力。
如果输入大量背景信息寻找特定细节,Gemini能确保追踪到所有内容,对我是最好用。
这些模型很有趣,如果它们在某个特定点上打动了你,你就会认定这个模型更并一直用下去,直到它犯了一个愚蠢的错误。
这存在一个阈值效应,先是惊艳的表现让你爱上它,一次愚蠢的错误让你决定,我还是试试Claude、ChatGPT与其他工具。
Sebastian Raschka:完全正确,你会一直用到它出问题为止,这就好比文本编辑器、操作系统或浏览器。
Safari、Firefox、Chrome都差不多,只有当你遇到边缘情况或需要特定扩展程序时,才会切换。
没人会为比较,而把同一个网站放进不同浏览器里跑,除非页面显示崩了。
这观点很棒,你会一直忠诚于某个工具,直到它的错误,迫使你探索新选项。
Nathan Lambert:关于长上下文,我之前用Gemini,GPT 5.2发布时提到的长上下文得分令人咋舌,从30%飙升到70%左右,这还只是个小更新。
要跟上这些变化太难了,我现在更看好GPT 5.2的长上下文能力。这类似一场永无止境的测试战役,我都不知道该如何实际验证。
我们都没从用户角度谈论过中国模型,这说明什么,是中国模型不够好,还是我们太有偏见,只关注美国?
Sebastian Raschka:我认为反映模型本身与平台体验间的差距。开放模型更多是以开放权重Open Weights闻名,而非平台体验。
Nathan Lambert:有很多公司愿意以低成本提供开放模型的推理服务。
比如OpenRouter,对比多模型很容易;也可以在Perplexity上运行DeepSeek。
我感觉在座各位都在持续使用OpenAI的GPT-5Pro,我们都愿意为微小的智能提升付费。
至于说美国模型输出更好的说法,我觉得问题在于这种优势能持续吗,只要它们更好,我就会付费。
我看过分析指出,或许是审查机制,中国模型在服务时,单个副本分配的GPU更少,导致速度慢、容易出现异样的错误。
在美国,如果速度与智能都占优,用户自然会选本土模型。
这或许会倒逼中国公司在成本或产品创新上竞争,对整个生态是好事。
最直接的原因很简单,目前美国模型更好,我们用它。我尝试过中国模型与其他开放模型,很有趣,但回不去了。
Lex Fridman:我们没怎么聊编程,这是很多人非常关心的用例。
我现在是Cursor与Claude Code各用一半,它们体验截然不同,都很有用。
你们两位写代码很多,现在流行用什么?
Sebastian Raschka:我用VS Code的Codex插件。它很方便,有聊天界面能访问代码库。我知道Claude Code,它更主动,会为你接管整个项目。
我有点控制欲,想知道它在干什么,还没习惯完全放手。
Codex目前是我的首选,它是辅助者,而非接管者。
Lex Fridman:我得说,我使用Claude Code的一个原因是培养用自然语言编程的技能,体验完全不同。
你不再需要微观管理代码生成的细节、查看差异在Cursor IDE里可以这么做,是在宏观层面进行设计思考与指导,我认为这是对编程过程的全新思考方式。
Claude Code似乎能更好发挥Claude Opus 4.5的能力。
Nathan Lambert:这是一个很好的对比测试,可以同时打开Claude Code、Cursor、VS Code,选择相同的模型提问。结果非常有趣,Claude Code的效果要好得多。
Lex Fridman:两位在很多领域都成就斐然,既是研究员、程序员、教育家,是活跃的X博主与书籍作者。
Nathan,听说你很快要出一本关于RLHF人类反馈强化学习的书?
Nathan Lambert:目前已经可以预订,也有完整的数字预印本。这是我的初衷之一,在万物数字化的时代,亲手创造一件精美的实体作品,本身是一种乐趣。
Sebastian Raschka:从零构建语言模型,既有趣、又能学到很多东西。
类似你说的,这可能是理解事物运作机制的最佳方式。看图表可能会出错,读概念解释可能会产生误解。
代码不同,只要它能跑通,你就知道它是对的,它精确无误,否则无法运行。
这是编程的美妙之处,代码从不撒谎。本质上它是数学,书本上的公式印错了,你可能察觉不到,在代码里,你可以亲手验证真理。
Lex Fridman:同意。我很享受阅读《从零开始构建语言模型》时,切断互联网、完全专注的状态。
我平时读很多历史书,感觉不孤单,也更有趣。
说到编程,我觉得搭配LLM更有意思,用它辅助阅读是如此。
干扰应该降到最低,利用LLM是为丰富体验,增加上下文。
对我,这种方式让微小的顿悟时刻,发生得更加频繁。
Sebastian Raschka:我想修正刚才的说法,我不是建议不用LLM,是建议分阶段进行。
第一次阅读时,我采用离线专注模式;之后我会做笔记,克制立即查资料的冲动。
第二遍时,我会用LLM。这种方式对我更有条理,有时候书中就有答案,但让问题沉淀一下更好。每个人的偏好不同,我强烈推荐在读书时辅助使用LLM,只是对我,它是第二步,不是第一步。
Lex Fridman:我的习惯恰恰相反,我喜欢一开始用LLM来铺陈背景,让我了解即将进入的这个世界。
我会尽量避免从LLM,跳转到X或博客,容易掉进兔子洞。你会陷入某人观点、关于特定话题的网络骂战,突然间就偏离主题,迷失在互联网与Reddit里。
如果只是纯粹让LLM提供宏观理念与背景信息,效果会很好。有些书做得不错,并非总是如此。
Nathan Lambert:这是我喜欢ChatGPT桌面应用的原因,它让AI在电脑上有了一个专属的家,不是淹没在杂乱的浏览器标签页中。
我觉得Claude在这方面做得很好,体验令人愉悦。它的产品设计非常有吸引力,给你一种温暖感。相比之下,OpenAI的Codex强大,感觉稍微有些粗糙。
Claude让从零构建变得有趣,不需要太操心,只要相信它能做出东西来。这对做网站、更新工具非常有用,我也会用它做数据分析。
比如我的博客,我们抓取Hugging Face数据,追踪每个数据集与模型的下载趋势。Claude会说,数据处理完了,没问题。这在以前,可能要花我好几天时间。我有足够的背景知识,来判断这些趋势是合理的,并进行核查。它类似完美的中间人,让你免去维护底层网络项目与脏活累活的痛苦。
Lex Fridman:刚才聊了很多闭源模型,现在我们谈谈开源LLM的现状。
哪些模型很有趣,哪些让你印象深刻,为什么?我们已经提到DeepSeek。
Nathan Lambert:要不试试不看笔记,能说出多少个?
Lex Fridman:没问题,不看笔记。
Nathan Lambert:DeepSeek、月之暗面Kimi、MiniMax、01.AIYi、Qwen通义千问,光中国的就很多。
Sebastian Raschka:还有Mistral AI,Google Gemma,还有GPT-OSS,ChatGPT的开源模型。
英伟达的Nemotron也很棒,特别是Nemotron 3。年底发布了很多东西,Qwen是之一。
Nathan Lambert:刚才我试着列举时,想说目前的格局已经变成,我们可以列出至少10个中国模型,同样也能列出10个西方模型。
这很有趣,OpenAI发布自GPT-2以来的第一个开源模型,GPT-OSS。当我写这事时,大家还在说别忘了GPT-2,现在的时代背景完全不同。GPT-OSS是一个非常强大的模型,能完成一些其他模型做不到的事。
出于私心,我想推广一些西方公司。美国与欧洲也有完全开源的模型,我在艾伦AI研究所AI2工作,我们一直在构建OLMo,并发布数据、代码等所有内容。现在,对致力开源以便他人训练模型的人,竞争非常激烈。
还有基础模型研究所LM360的K2模型,瑞士的研究联合体Apertus,Hugging Face广受欢迎的SmolLM,英伟达的Nemotron也开始发布数据,还有斯坦福的Marin社区项目,他们在建立一个管道,让人们可以通过提交GitHub issue来实现新想法,并在稳定的模型栈中运行。
这个名单在2024年初还很短,大概只有AI2,这对LLM普及与理解是件好事。
目前一个趋势是,中国的开源模型往往参数量更大,通常是混合专家MoE模型,峰值性能更高;美国这边,无论是Gemma,还是Nemotron,往往是较小的模型,这种平衡在改变。
比如Mistral Large 3发布了,这是巨大的MoE模型,架构与12月发布的DeepSeek非常相似。
还有初创公司Reka,Nemotron与英伟达都预告了远超1,000亿参数的MoE模型,比如预计在2026年Q1发布的4,000亿参数模型。
我认为,2026年中美开源模型的格局与平衡将会发生转变,我个人对此非常期待。
Lex Fridman:你能一口气说出这么多模型,太强了,你提到Llama了吗?
Nathan Lambert:没提,我不是故意的。
Lex Fridman:加上Llama,在你提到的这些模型中,有哪些是特别出众、让你觉得很有意思的?你提到Qwen 3是一个亮点,除此之外呢?
Sebastian Raschka:我觉得这1年,几乎被DeepSeek V3、R1、12月的DeepSeek相关发布霸榜。它们总能在架构上,做一些有趣的微调,这是其他模型所不具备的。
如果你想要既熟悉又高性能的模型,那是Qwen 3,还有Nathan提到的GPT-OSS。我认为GPT-OSS独特之处在于,是第一个真正以工具使用Tool Use为核心进行训练的开源权重模型。这算是一个小小的范式转变,目前生态系统还没完全准备好。
工具使用,是指LLM能够进行网络搜索或调用Python解释器。这是一个巨大的突破,它解决对LLM最常见的诟病,幻觉Hallucinations。
解决幻觉最好的方法,不是让模型死记硬背或胡编乱造,是给它工具。比如遇到数学题,为什么不让它调用计算器或Python。
如果问1998年谁赢了世界杯,它不需要在参数里检索,直接搜谷歌,找到FIFA官网,确认是法国队,这样获取的信息是精准的,我认为这是巨大的飞跃。
目前开源生态没有充分利用这一点,部分原因是信任问题,你不敢在本地运行一个能访问工具、可能会格式化你硬盘的模型,通常需要容器化运行。
我坚信,未来几年,这种能力将是至关重要的一步。
Lex Fridman:有两点我想强调一下。
首先,谢谢你解释工具使用的含义。这是一个很好的习惯,即使是类似混合专家模型MoE这样相对成熟的概念,我们应该向听众解释它的含义、实际应用与不同形式,帮大家建立直觉。
为什么现在会涌现出这么多开源模型,你的直觉是什么?
Nathan Lambert:如果你发布一个开源模型,首要愿望是有人用它,其次才是透明度与信任。
我认为中国开发者这样做,主要是希望全世界都能使用这些模型。
在美国以外,很多人不会为软件付费,他们拥有算力,可以在本地运行模型。
还有些数据,你不想上传到云端的。
核心在于让人们能够访问模型、使用AI。如果没有模型权限,这一切都无从谈起。
Lex Fridman:我们需要明确一点,我们一直在讨论的这些中国模型与开放权重模型,通常是在本地运行。这意味着你不需要把数据发送到中国,也不用发给硅谷开发商。
Nathan Lambert:很多美国初创公司,通过托管中国模型,按Token收费来盈利。
另一个原因是,美国公司,比如OpenAI非常缺GPU,他们算力已经到了极限。
每次发布新产品,他们总会说,我们GPU已经不堪重负。
我记得在某个发布会上,Sam Altman说过,我们发布这个,是为能用你们GPU,而不是消耗我们自己的,这样OpenAI依然能获得分发渠道。
这非常现实,这对他们几乎是零成本。
Sebastian Raschka:普通用户可能类似用ChatGPT一样,在本地使用这些模型。对企业,这是一个巨大的突破。
你可以定制模型,通过后训练Post-training添加数据,使其成为法律、医学等特定领域的专家。
你提到Llama,中国开放权重模型的吸引力在于,它们的许可证更加友好。
我认为它们是完全开放的开源许可证,类似Llama或Gemma这样的模型会有附加条款,例如用户数量上限。
如果你拥有数百万用户,需要向Meta或其他公司汇报财务状况。模型免费,有附加条件。
人们喜欢纯粹、没有隐患的东西。除性能外,这种无条件的特性,是中国开放权重模型,如此受欢迎的原因。
Nathan Lambert:生态系统有所改善。
当你展示Perplexity,提到Kimi K2 Thinking是在美国托管时,这很有趣,大家对数据隐私很敏感。
Kimi K2 Thinking是非常受欢迎的模型,人们说它在创意写作与编程方面表现出色。是这些细微之处,决定人们会选择哪个模型。
Lex Fridman:这些模型,有没有探索出什么让你觉得特别有趣的新思路?
Sebastian Raschka:我们可以按时间顺序来。
2025年1月发布DeepSeek R1,它是基于2025年12月的DeepSeek V3。
在架构方面有很多内容。类似我在《从零开始构建大模型》项目中做的,你可以从GPT-2开始,添加组件,把它变成另一个模型,它们同宗同源。
DeepSeek独特之处在于MoE专家混合架构Mixture of Experts。这不是他们发明的,我们可以稍后细聊,还有MLA多头潜在注意力Multi-head Latent Attention,这是对注意力机制的一种调整。
2025年,开放权重模型的主要区别在于,对推理成本或KV缓存KV Cache大小的调整。目标是降低长上下文的成本,使推理更经济。
DeepSeek使用多头潜在注意力,还有GQA 分组查询注意力Group Query Attention,这依然非常流行。
滑动窗口注意力Sliding Window Attention,我想Mistral就用了它。
是这些不同的调整,让模型各具特色。如果你把它们放在一起比较,你会惊讶发现它们在本质上非常相似。
最棒的是,怎么调,都能跑通。你可以移动归一化层来获得性能提升。
OLMo在消融研究Ablation Studies方面做得很好,展示了改动某个组件对模型的影响。实现Transformer的方法有很多,它依然能工作。
目前流行的主要技术,包括MoE、多头潜在注意力、滑动窗口注意力、分组查询注意力。年底时,我们看到一些致力实现线性扩展的尝试,比如Qwen某些版本引入类似门控DeltaNet的机制,灵感来自状态空间模型SSM,试图用更低廉的操作,替代昂贵的注意力计算。
Lex Fridman:也许我们该退一步,聊Transformer架构本身?
Sebastian Raschka:我们可以从GPT-2开始,源自《Attention Is All You Need》那篇论文。
原始Transformer,包含编码器与解码器,GPT只取了解码器部分。本质上,它是一个整合注意力机制的神经网络。
你一次预测一个Token,通过嵌入层、Transformer块(包含注意力模块与全连接层)、归一化层进行处理。

从GPT-2发展到现在,我们引入专家混合MoE层。全连接层,可以想象成多层感知机MLP,连接数庞大,计算成本很高。
MoE思路,是将这个组件拆分成多个前馈网络,例如256个,这是所谓的专家。
关键在于,并非所有专家都会同时被激活。路由器Router会根据输入Token,决定使用哪个专家最有利。
比如处理数学题时,激活数学专家;翻译时,激活语言专家。MoE核心思想,是在不增加每次推理成本前提下,将更多知识打包进网络。
这使得模型变得稀疏Sparse,即任何时候,只有少数部分在工作,而非稠密Dense模型全员待命。
Lex Fridman:也许现在可以聊KV Cache,在此之前,根本上说,从GPT-2到今天,有多少新想法被真正实现了,这些架构真的有很大区别吗?
Sebastian Raschka:主要是引入MoE,或者把多头注意力MHA微调为分组查询注意力GQA。
可能用RMS Norm替换Layer Norm,或者把激活函数从Sigmoid换成ReLU。
归根结底,它没有根本性的变革,是同一套架构,只是通过微调组件,将一个模型转换成另一个。
Lex Fridman:本质上还是同一个架构。
Sebastian Raschka:比如在我书里,我使用的是简单的GPT-2模型,约1.2亿参数。
在补充材料中,我展示如何构建类似Gemma 3或其他从零开始的模型。总是从GPT-2开始,调整一些组件,就能得到另一个模型,这类似某种谱系传承。
Lex Fridman:能帮大家建立一种直观的理解吗?
宏观看,AI领域进步神速,根本上讲,架构没有改变。这种进步的动力究竟源于何处,实际收益在哪里?
Sebastian Raschka:模型开发分为不同阶段。
过去只有预训练Pre-training,比如GPT-2。
现在演变为预训练、中期训练Mid-training、后训练Post-training,我认为我们目前处于深耕后训练的阶段。利用更高质量的数据,进行大规模预训练,依然能带来优势。
现在我们实现GPT-2不具备的能力,ChatGPT为例,核心是GPT-3模型,架构与GPT-2相同。
真正变革在于引入监督微调SFT与人类反馈强化学习RLHF,这更多是算法层面创新,而非架构本身的改变。
Nathan Lambert:系统层面也发生巨变。
英伟达经常提及FP8、FP4等技术,实验室致力如何利用更强算力,将其高效融入模型训练中。这让他们能处理更多数据,更快找到最优配置。
进行大规模训练时,每GPU每秒处理的Token数是一个关键指标。启用FP8训练后,这个数值,可能从10k提升到13k,意味着模型参数占用的内存更少,通信开销降低,训练速度显著提升。
这种系统级的改进,支撑数据与算法层面更大规模、更快速的实验,这是不断迭代的循环。架构看似没变,现在的代码库与当年截然不同。
比如现在训练一个20B参数的模型,如GPT-OSS,速度远超当年训练GPT-2。
Sebastian Raschka:没错,比如在混合专家模型MoE中,应用NV FP4优化,能提高吞吐量。
这主要是速度上的提升,并未赋予模型新的能力。这更多是关于如何在不牺牲性能的前提下,降低计算精度。
Transformer面临潜在替代方案,例如文本扩散模型Text Diffusion Models,这是完全不同的范式,可能借用Transformer架构,并非自回归。
还有类似Mamba这样的状态空间模型State-Space Models,这些模型各有权衡。
现实情况是,在最先进SOTA的模型领域,自回归Transformer依然不可撼动。出现了一些更便宜、更小的替代架构,如果追求极致性能,核心依然是从GPT-2演化而来的自回归Transformer。
Lex Fridman:这里有个大问题,当我们讨论预训练背后架构时,扩展定律Scaling Laws在预训练、后训练、推理、上下文长度、数据合成等方面,是否依然有效?
Nathan Lambert:我们先从扩展定律的技术定义讲起,它描述的是X轴计算量和数据量、与Y轴模型预测下一个Token的准确性间的幂律关系。
简单来说,是给模型一段从未见过的文本,它能预测得多准,这个定律至今依然极具预测性。
目前扩展定律,已经衍生出三个维度。
第一,传统的预训练扩展,即模型规模与数据集规模。
第二,强化学习扩展Scaling RL,通过延长试错学习的时间,在Y轴上实现性能的线性提升。
第三,推理时计算扩展Inference-time Compute,让模型在生成答案前,进行更多思考。
OpenAI的o1模型,以引入推理时扩展而闻名。
低垂的果实,特别是过去1年中基于可验证奖励的强化学习RLVR与推理时扩展,大部分已被摘取,我对这些定律依然持乐观态度。
这是为什么新模型给人的感觉如此不同,以前它是即时反应,现在它可能会花几秒、甚至几分钟进行隐性思考。
这种推理时扩展,带来能力上的阶跃式提升,让模型能熟练使用工具,甚至胜任复杂的软件工程任务。
当你观察推理过程时,会发现模型会尝试使用工具,查看结果,尝试另一个API,循环往复,直至解决问题,这是通过具有可验证奖励的强化学习训练出来的。
这为AI在真实环境中的应用构建基础,它可以操作命令行、管理Git、整理文件或搜索信息。
仅在1年前,我们很难想象模型能做到这些。这是神奇的演变,解锁了巨大的价值。
大家都在热议持续学习Continual Learning,下一个阶跃式进步何时到来,目前难以预测。
Lex Fridman:你,刚才提到的观点非常深刻、密集,我们不妨拆解一下。
既然你对所有维度的规模化,都持乐观态度,我们先从预训练开始。
这是否意味着预训练扩展中容易摘的果实已经没了?预训练是遇到瓶颈,还是你依然看好它的潜力?
Nathan Lambert:预训练的成本,已变得极其高昂。扩大预训练规模,通常意味着需要部署巨大的模型,这点目前已成定局。类似GPT-4级别的模型,参数量大约在1T/万亿左右。
这是为什么大家希望模型变小,训练成本相对推理服务成本Inference Cost是很低的。
DeepSeek曾提到,预训练成本约为500万美元。在论文中提到,解决训练中的工程故障与GPU闲置,大概花了200万美元。
即便训练成本在100万~1,000万美元间,为数百万用户提供服务的成本,是数十亿美元级别。
这带来经济账,如果规模化能带来更好模型,它在经济上划算吗,我认为,随着AI能解决更高价值任务,这不再是问题。
例如,类似模型Claude Opus 4.5,能让代码编写类似日常工作一样流畅。
2025年7月,我启动ATOM项目Open ModelsAmerican Truly Open Models,当时构建时,遇到很多问题,最近我用新模型重试,发现它已经能解决当时所有阻碍,证明模型仍有巨大进步空间。
Lex Fridman:你指出规模法则Y轴的一个微妙之处,基准测试中的智能得分,与用户的实际体验可能存在差异。
抛开经济因素,仅从定律本身看,你的直觉是什么?
如果继续扩大计算规模,模型真的会变得更聪明?
Nathan Lambert:绝对会。
有些AI巨头领导者可能会说,这一规律已经持续13个数量级,没理由现在突然停止。
我们面临的限制,可能不是定律本身,是物理设施。
大家都在谈论2026年,届时类似吉瓦GW级设施与超大规模数据中心将上线,搭载大量Blackwell芯片,这些设施的规划,大多始于2022~2023年。
目前是建设的空窗期,这批新集群即将问世。实验室将拥有前所未有的算力,结果并非绝对,我见证太多进展,我充满期待。
我们可能会看到模型变得更大,甚至出现2,000美元的订阅服务,既然已经有200美元的订阅,未来增长10倍,并非不可能。这一切,都源于更大模型带来的前沿能力。
Lex Fridman:据报道,xAI将在2026年初,达到1吉瓦算力规模,并在年底扩增至2吉瓦。
你认为他们将如何利用这些资源来验证规模法则,多少会用于推理,多少用于训练?
Nathan Lambert:两者皆有。归根结底,你在模型训练过程中的所有决策,最终都要追溯到预训练阶段。
若要在模型中扩展强化学习RL,必须确认架构是否支持这一点。
我们曾讨论过其他架构,随后使用不同类型的注意力机制。
我们也在探讨混合专家模型MoE,MoE的稀疏性,使其在生成方面更高效,而生成是后训练Post-training的重要环节。你必须调整好架构,才能真正扩展这些计算资源。
我依然认为,大部分算力还是应投入到预训练中。
模型仍有改进空间,你还是会追求最强的基础模型。几年后,可能会遭遇瓶颈,届时强化学习的计算周期会拉得更长。
Lex Fridman:有没有人反驳过你,认为预训练已死?认为现在重心全在于扩展推理、后训练、长上下文、持续学习、合成数据?
Nathan Lambert:嘴上这么说,我不觉得他们在实践中是这么做的。
Lex Fridman:这只是业界的普遍论调。
Nathan Lambert:大家兴奋点不同。
例如,RL领域还有许多唾手可得的成果。比如我们11月发布模型时,是赶着截止日期,11月20日。
在那之前,我们RL跑了5天。
对2024年一个300亿参数的模型,这仅是后训练阶段,时间已经算很长了,它不算是个巨型模型。
到了12月,我们又发了一版,这次RL跑了三个半星期,效果显著提升。这相当于把那1年最重要的算力,分配给了这个阶段。
这是一种取舍,你不能无休止训练,必须不断吸收研究人员的改进成果,这涉及重新预训练。
你可能会花1个月做后训练,之后还得交付用户、做安全测试。我认为多种因素,促成这种不断更新模型的循环。
改进空间总是有的,新到的计算集群,可能会让任务跑得更稳、更快。
大家常谈论Blackwell部署,在AI2,我们要么是在1,000~2,000 GPU上预训练。
一旦你用1万、甚至10万GPU预训练,故障模式截然不同。
大规模运行中,几乎肯定会有GPU损坏。你的代码必须具备容错冗余,这是完全不同的难题。
无论是现在我在DGX集群上折腾后训练,还是你在学习机器学习,训练超大模型的核心挑战在于大规模分布式计算。
为实现缩放定律Scaling Laws,尤其在预训练阶段,这是一个系统工程问题,需要同时调动所有GPU。
转向强化学习时,情况又不同,它更适合异构计算,你有多个模型副本。
语言模型的RL训练,通常需要两组GPU,一组是执行者Actor,一组是学习者Learner。
学习者负责实际的更新,通常使用PPO或TRPO等策略梯度算法。
另一方面,执行者负责生成补全内容,这些内容随后会被评分。
RL的本质是优化奖励,实践中,可以让世界各地不同的执行者处理不同类型的问题,然后传回高度互联的计算集群进行实际学习。
需要获取梯度,拥有紧耦合的网络以进行并行处理,并分散模型以实现高效训练,这涉及很多方面。
每种训练与部署,都有扩展考量。
如前所述,预训练、RL,再到推理时的扩展,如何为1亿用户提供一个需要思考1小时的模型,这很难。
为赋予人类这种智能,我们面临种种系统性问题,需要更多、更稳定的算力。
Lex Fridman:听起来,你对这一切,推理、推理能力,乃至预训练的规模化扩展,都持乐观态度。
Sebastian Raschka:这是个大问题。在训练与推理的规模化这两个维度上,你都能获得收益。假设算力无限,你全都要。
训练类似一个层级结构,预训练、中期训练Mid-training、后训练。增加数据、扩大模型规模,能赋予模型更多知识,打造更好的基础模型。
假设模型无法在预训练阶段解决最复杂的问题,你仍可以通过中期训练、长上下文、或带有可验证奖励的强化学习RLVR等后训练手段,来解锁模型预训练知识中的潜力。
预训练越多,基础模型越好,后续解锁的上限越高,但这太昂贵了。
在算力有限的现实中,必须权衡,是把算力花在扩大模型上?理想情况下都想做,规模化依然重要。
如我们在GPT-4.5上看到的,有时候不划算。你也许可以通过专注推理端的扩展,利用其他技术在当下解锁更多性能。
2026年o1模型是最大的进步,它证明与其预训练更大的模型,如GPT-4.5,不如将一个小模型推向极致。
我不会说预训练规模化已死,只是目前出现更有吸引力的扩展方向。终有一天,你还是需要在预训练上取得进展。
还得算经济账,预训练是固定成本,一旦训练完成,能力固化。推理扩展是可变成本,每次查询,都要花钱。
这就变成数学题,模型要在市场上存活多久?如果半年后就淘汰,花1亿美元预训练可能不值得,不如花200万美元在推理上提升性能,这取决于用户规模的计算。
ChatGPT在这方面处于有利地位,用户基数大,需要更低的推理成本,GPT-4o稍微小一些。
针对特定任务,如奥数题,OpenAI可能有专有模型,可能只是经过少量微调,主要依靠推理扩展,在特定任务中实现峰值性能。
总之,预训练、中期训练、后训练、推理扩展,这些都很重要。关键在于找到当下最佳配比,实现最高的性价比。
Lex Fridman:这也许是定义预训练、中期训练、后训练的好时机。
Sebastian Raschka:预训练是经典的训练方式,逐个预测下一个Token。你拥有庞大的语料库。
Nathan可能对此有独到见解,他们做了OLMo-3,论文中有很大篇幅侧重正确的数据组合。
预训练,本质上是在海量互联网数据、书籍、论文等语料库上,进行基于交叉熵损失的下一个Token预测训练。
多年来,这也在演变,过去人们把能找到的所有数据都扔进去。现在,不仅有原始数据,还有合成数据,重写过的内容。
合成数据不一定指AI凭空编造的数据,也包括从维基百科等文章中提取内容,将其改写为问答、摘要或释义,以此创建更优质的数据。
这好比人类学习,读一本条理清晰的书,肯定比读一堆混乱的Reddit帖子,学得更好。
Lex Fridman:我觉得Reddit上,肯定会有帖子反驳你这点。
Nathan Lambert:有些Reddit数据非常有价值,非常适合训练,只需要做好过滤。
Sebastian Raschka:我是这个意思。
如果有人能把这些信息提取出来,用更简洁、结构化的方式重写,这对LLM是更高质量的输入。
也许最终产出的LLM能力相当,高质量数据,能让它学得更快。如果语法与标点正确,模型直接就能学会正确的方式,不必先摄入混乱的信息,再学习如何纠正。
这是预训练的演变方向,是规模化依然有效的原因,不仅在于数据量,还在于让数据更有用的技巧。
至于中期训练Mid-training,以前它被归为预训练。叫中期训练,是只有预训练与后训练,中间空着听起来很奇怪。这个阶段通常与预训练类似,更加专业化。使用相同的算法,关注点转向,比如长上下文。
举例,预训练时,没有多长文档,你会设立一个特定阶段来处理长上下文。LLM是神经网络,存在灾难性遗忘的问题。
你教它新东西,它就会忘掉旧的。这与人类一样,没有免费的午餐。
如果你问我10年前学过的数学题,我也答不上来,得复习一下。
请务必阅读免责声明与风险提示
