如果没学过概率论的朋友,会简单的认为,波动率的意思就是震荡的大小,就是来回扫的意思。
其实严格来讲不能这么理解,虽然说不上完全错。
波动率被记作σ,也称标准差。
要理解σ之前,首先要理解μ是什么,μ就是期望值。
期望值,就是在做一个独立同分布的实验(你可以简单的理解成一个稳定封闭的环境下做同一个实验),做n次后结果相加取平均值,而随着n越大,其平均值会越来越趋于某个值,当n趋于∞的时候,那么这个平均值会无限接近某个值,或者收敛于某个值,这个值就是单次实验的期望值。
而它亦等于每个可能出现的实验结果乘以其出现的概率,然后加起来。(证明就不展开了,未来在专栏内专门讲的时候再展开。)
而用在金融领域,假如我们问t时刻后,或者后天上午10点钟的时候,某个股的股价的期望值是多少?
其问的不是说在那个时间点股价一定得是多少,而是在问,在那个时间点,所有可能出现的结果乘以其概率后,再加起来得出的值。
当然,股价在那个时刻是多少,是个一次性事件,走出来是多少就是多少,交易所也不可能给你重复回档再走一遍。
所以,在金融数学里,这个期望值μ,只存在于数学抽象当中。
其意思就是,假如有个灭霸用时间宝石,或是奇异博士用他的游历多元宇宙的能力,把多元宇宙里同一时刻的结果值记下,并取平均值,这个值就是股价在那个时间点的期望值。

然后数学家们又提出方差这个概念,用来衡量实验结果的离散程度。
你瞧,两组数据:(50,50),(1,99),这两组数据的平均值都是50,可是离散程度却相差很大。
我们把实验结果值记为X,这个X被称之为随机变量。
而期望值μ也可以记为 E(X)
而方差 亦可以记为 Var(X)
而开方后就是σ,被称之为标准差。
没学过概率论的朋友,先不要纠结为什么要这样设定,以后我会在专栏内别的文章详细解释。
期望值、方差、标准差,这是随机变量的参数,这只有在上帝视角才能预先知道的。
但学到初等概率论的后面部分,就会学到“参数估计”——我们是可以从历史的已发生实验结果,来估算其随机变量的参数的。
例如期望值,前面提到随着实验次数的增加,其实验结果平均值(亦称为样本均值)会越来越接近真实期望值。
还有方差也是,通过多次实验的结果代入公式:
算出样本方差其中里面就是样本均值。
随着实验次数的增加,样本均值会越来越接近真实期望值μ,于是样本方差亦会越来越接近真实方差(至于为什么分母是n-1而不是n,这要涉及到有偏估计与无偏估计的区别,未来我会在专栏内出一篇文章讲解)
我们可以说随着n的增加,实验结果平均值会向真实期望值μ收敛。
而已经进行完的n次实验结果的结果值加起来的和,我们记为T,那么T是不是就等于啊?毕竟嘛!
而随着n的增加,会向μ收敛,那么,我们是不是也可以说,未来n次实验的结果的和T或,是不是随着n的增加,向nμ收敛啊??
错!!未来的和的结果并不会往nμ收敛,而是会发散,只是其期望值还是nμ。
这是初等概率论里这一部分最反直觉的地方。既然未来的样本均值随着n增加往真实期望值μ收敛,那样本和为什么不是往nμ收敛呢??!
首先,方差有个重要性质,那就是它的累加性。
同样,期望值μ也是有累加性。
一次实验的期望值是μ,方差是,那么n次实验的的和的期望值就是nμ,方差则是。也就意味着,实验结果的和的离散程度是随着n的增加而增加的。
当然,这方差的性质是需要严谨的数学证明的,其证明过程在概率论教材里面必然列出的,老师也是必教的,其证明过程很简单,基本上就是小学生算术的水平,大家可以直接问deepseek或者千问,我在这里就不展开了。
实验结果和的方差是,那么标准差自然就是它的开根:
那么,如果要用一个式子表达未来n次实验结果的和,那就是:
其中Z是满足期望值为0,方差为1的正态分布随机变量,记为 Z~N(0,1)
这个式子它不是一个确定的值,是个不定式,你可以把它看成是一个数学建模。其中等式右边只有Z是不确定的,其他的参数μ,σ,是视情况可以被确定的。
有小伙伴就要问了,为什么加的是标准差,不是方差?
那是因为,只有标准差构成的这个式子(其中nμ是可确定值),其式子的结果值的概率密度函数,对应回可能取值的概率密度函数,两者是一一对应吻合的,它们的函数图像是一样的。
其中Z又必须是满足期望值为0,方差为1的正态分布随机变量,记为 Z~N(0,1),这才能让等式左右两边的取值的概率密度函数相吻合。
当然,这也是要严谨证明的,其实这证明一点都不难:
首先根据中心极限定理,不管是什么类型的随机变量的概率分布,它未来实验结果值的和的概率分布都是正态分布,并且这个以结果和作为随机变量的正态分布的期望值μ就是原来随机变量的期望值乘以实验次数n,方差就是原来随机变量的方差乘以实验次数n。
于是
而等式右边,首先 Z~N(0,1),根据随机变量期望值与方差的性质,如果随机变量乘以一个系数构成新的随机变量的话,那么这个新的随机变量分布类型不变,其期望值,就是原来随机变量的期望值乘上这个系数,而新的随机变量的方差,就是原来随机变量的方差乘上这个系数的平方,而原来Z的期望值是0,乘上系数还是0,所以
而根据随机变量期望值的平移性,随机变量加上一个固定值构成新的随机变量,那么这个新的随机变量的期望值就是原来的期望值加上这个固定值,所以
这就跟 的分布函数完全一样。
所以 这个式子里,我们可以把nμ称之为“漂移项”,称之为“随机项”。
看到这里,我相信一些爱较真的小伙伴,心里面还是有个疙瘩。如果是学过概率论的话,上面的每一步都能看得懂,方差的性质也不会陌生,但就是感觉,还是很反直觉。
——那是因为,你还没有从现实直观的角度去理解。
有些人学数学,觉得只要推导的每一步都能看懂,甚至能背下来,就以为自己掌握了这个知识点了。但其实,比起数学推导,在脑海里建立几何直觉要重要得多。
下面我就带大家建立起现实直觉,这是为了更好的理解后面要讲的几何布朗运动做准备。
首先,虽然 随着n的增大而增大(说的严谨些应该是随着n的增大,方差增大)
但如果求均值,也就是单次实验的μ,随着n的增大是越来越收敛于μ的。
因为当n趋于无穷大的时候,是趋于无穷小的,自然式子结果就是趋于μ。
想象一下,随着n的值越大,虽然样本均值会非常接近μ,但那细小的差别,累积n次后,就会显得很大了。
但是,随着n趋于无穷大,nμ跟 都是趋于无穷大,但的趋于无穷大的速度要比nμ慢很多,最终是比nμ低阶的无穷大。
什么是低阶无穷大? 意思是这个无穷大,在nμ这个更高阶的无穷大面前是显得无穷小的。
因为 , 当n趋于无穷大的时候,这个式子是无穷小。那么这意味着分母是分子的高阶无穷大。
这时候哪怕加上个系数Z,这个Z不管取什么值,在nμ面前也是显得无穷小的。
(关于低阶无穷大跟高阶无穷大,大家可以在脑海里这么想象:一个正方形的面,是不是能容纳无穷多条线?同样的,如果是个立方体,同样也能容纳无穷多条线,但同时亦能容纳无穷多个面,所以正方形在立方体面前显得无穷小了。而正方形就是相对于立方体的低阶无穷大,立方体就是相对于正方形的高阶无穷大。)
所以,随着n的增大,标准差的绝对值虽然也越来越大,但比上和的期望后,其比例是越来越小的。
举个形象点的例子,假设现在扔硬币,正反面的概率各占50%。如果扔中一次正面,数值+1,如果扔中一次反面,数值-1。
那么不管扔多少次,结果和的期望值都是0的。
但是实际上,最终的和的结果可能是偏离0很大一段距离的。
有人就会困惑,按照大数定律,两者的频率应该越来越接近50%才对啊!
是的,没毛病,但你可能把频率跟频数给混淆了。
假如,最终结果的和是1000,意味着正面的次数比反面次数多了1000次。
看上去很多,但如果我告诉你,这是扔了1000亿次的结果呢?那么正面的次数是500亿零1000次,它比上1000亿,频率是不是非常接近50%?
所以,在频数上,两者的差距可以越来越大,但在频率上,是越来越接近50%的。
希望以上内容,能消除你在方差累加性的困惑,如果还是想不明白也不要紧,可以继续往下看。
我们可以看到,随着n的增加,比上nμ的比例会越来越小。但如果反过来,n的次数减少的话呢?其比例是不是越来越大啊?
——记住这个结论,这对理解几何布朗运动非常重要。
接下来,如果我把上面的实验次数n,换成时间t呢?
例如量子力学里面,研究粒子的随机游走,是以时间t来观察其位移的。
我们可以把粒子的总位移记为D。
如果已知一个粒子的随机游走,在一个单位时间T内的期望值是μ,方差是。
那么,时间2T内例子位移的期望值是不是2μ,方差就是2啊。
那如果是呢?期望值就是1/2μ,方差就是
所以,这个随机游走表达式就可以写成:
其中t就是单位时间T的系数。
而我们把单独抽离出来,这个就是几何布朗运动,它是满足期望为0,方差为t的正态分布随机变量:
亦称为对称随机游走。
为什么期望为0,方差为t? 因为上面论证了,设定是 Z~N(0,1) ,而期望值跟方差都有一个性质,就是随机变量乘以一个系数的话,那么其乘上系数后的随机变量的期望值μ就会乘上同样的系数,方差则是乘上这个系数的平方。而原本期望是0的话,乘上系数还是0,方差是1的话,乘上系数的平方就成了t。所以。
接下来我们把上式进行微分,也就是把时间无限分割,求它的瞬时增量:
然后我们把 换成另一种表达方式,变为dw
这个dw,亦称为“维纳过程”,也叫瞬时几何布朗运动。
那么原式就变为:
如果光看这个式子,你是得不出任何有价值的结论。
但一旦结合伊藤引理,神奇的事情发生了。BS定价模型就是基于此。
“几何布朗运动”,其实是人类抽象创造出的数学概念,它其实在现实中并不存在,就如同现实并不存在绝对意义的圆,并不存在绝对意义的自然常数e对应的连续变化,而人类创造出这种抽象的数学概念,是为了作为一个参照物,去衡量于描述某一类状态。
而几何布朗运动就是一个基础参照物,可以通过以它为基数、加系数的方式去描述或定义其他随机游走,而通过研究几何布朗运动的性质,就可以把这些性质套用到其他不同的随机游走。如果几何布朗运动可以在入到微积分的运算体系中,那么其他随机游走就可以加入到这个运算体系。
所以几何布朗运动就相当于一个桥梁,嫁接了随机游走与一般微积分运算。
而BS定价模型的偏微分方程法,就是通过结合伊藤引理,解偏微分方程求出σ。
怎么做到呢?我会在下篇文章详细说。
解得出的σ的值,就是隐含波动率,也称之为IV。
它一般来讲就是以一年的收益率作为随机变量的标准差,其中式子里面的r也是默认为年化无风险收益率(或者是年化市场利率、年化国债收益率)。而式子的t是以年为单位算的,如果是一天的话,对应的t就是1/252,252是一年的交易日。(但这也不要紧了,反正dt是无穷小,并且两边都约去了)
那是因为默认 里面的σ是年化标准差(或年化波动率)。如果你想算未来一天的标准差,那就是当然,你可以不喜欢这样的默认设定,你可以设定默认σ是半年的波动率,甚至是1小时的波动率,只要相应的把r设定为相同时间段的无风险收益率就好。
上面是从数学推导的角度推出,接下来,我们该如何从现实直观的角度去理解上面的过程?求出了隐含波动率后又能怎样呢?
首先,隐含波动率的意义,其实就是一年后的时间点,可能出现的结果的离散程度。
而一段时间后的对数收益率服从正态分布(这里先不要纠结什么是对数收益率,以后专栏会讲)
直接直观的讲,如果σ的值偏大,那么一年后这个时间点的对数收益率的概率密度函数大概是这样:
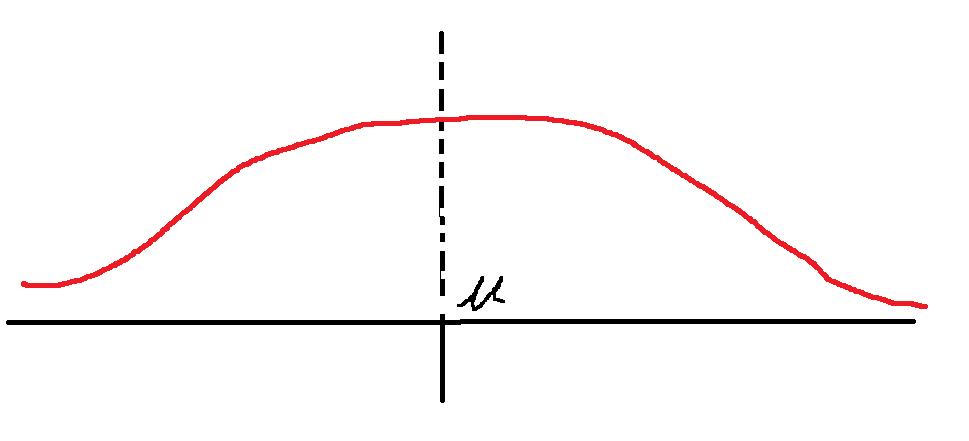
这个概率密度函数的特点是什么呢?
首先概率密度函数图像与x轴围成的面积必然是1(对应着概率100%),而这图像的线是往两边无限延申的,所以越往两边概率密度越低。
而我随便划定一个取值范围:
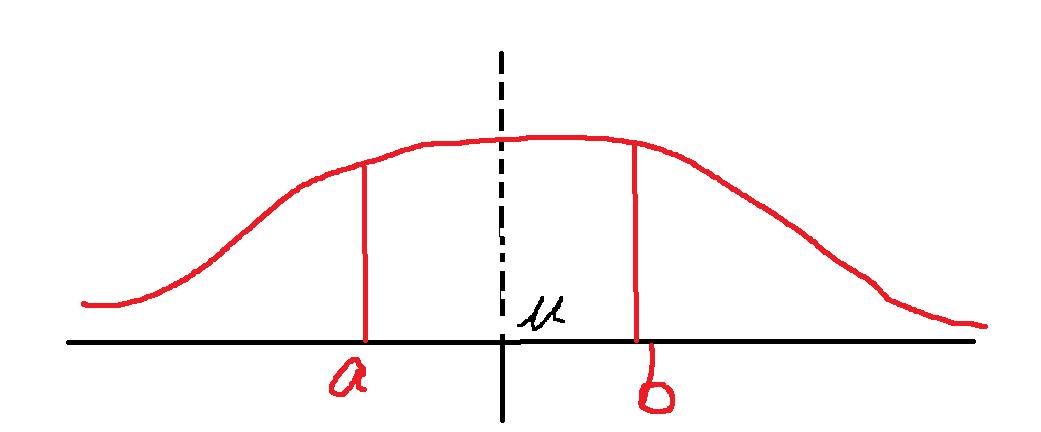
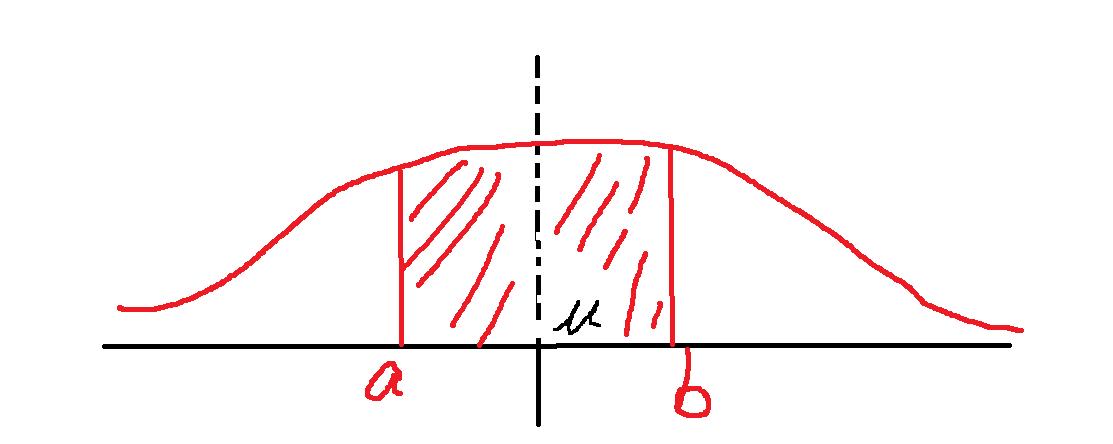
意思就是未来一年后的收益率,落在a跟b之间的概率,那么是多大呢?
就是从a点跟b点以垂直于x轴的方向出发,连接到这个函数图像,围成的面积,就是一年后的收益率落在a跟b之间的概率:
那么如果标准差σ比较小的话,图片就会变成这样:
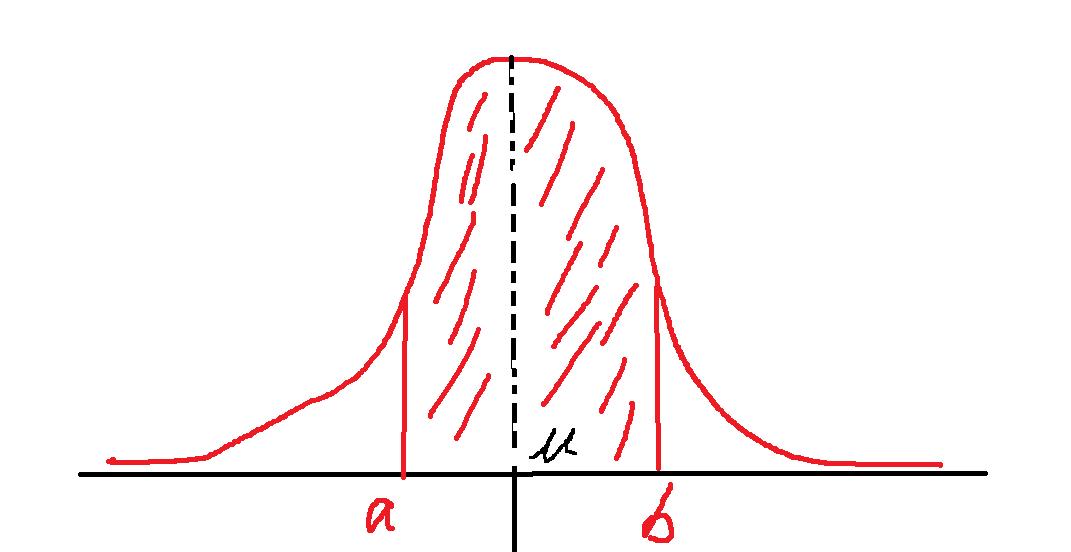
你瞧,这样围成的面积,是不是比前面的大,意味着未来一年后的收益率落在a跟b之间的概率要比前者大。
如果这个围成区域的面积,占了总体区域面积的90%,就意味着这个概率就是90%。
所以并不是说方差小,收益率就不可能偏离μ很远,它还是有一定概率的,只是这概率比较小。
而如果你关心的不是一年后的σ,而是一个月后的,那你就可以把这个σ值平方后,除于12,然后再开方,就是
从现实的角度,市场的参与者,可能大部分都不知道什么是σ,什么是期望。
但却是他们的集体主观意识,推动了行情,决定了现在的市场状态。
例如,在某个行权价,市场参与者们凭感觉觉得这里做Δ对冲策略,未来波动的收益、也就是gamma收益会比较大,于是就积极的买入V-ΔS组合,于是推高了V的价格,于是时间价值被推高。
反过来,如果市场参与者们凭感觉觉得,未来这价格不会有太大波动,同时觉得这时间价值有点高,于是就是积极的买入-V+ΔS组合,于是压低了V的价格,也就是时间价值被压低。
于是市场就会达到某种均衡状态,这是集体意识下导致的。
而Δ又如何决定?
首先,越是深度实值的期权,其Δ越接近1,上面已经解释过了,因为越是深度实值的期权,那么时间价值越低,时间价值越低,内在价值的变动权重就越高。
而如果到了行权日,只要是实值期权,Δ值必定是1,如果是虚值期权,Δ值必定为0.
(平值期权比较特殊,Δ值是0.5,以后我会在别的文章解释。)
而在距离行权日还有一段时间的时候,如果市场参与者,主观觉得未来这个S的价格,局限在比较小的区间,也就是σ比较小。
那么以现在标的市场价,也就是S为中心,实值期权行权价远离S的合约,会随着距离远离的过程中其Δ值会更快的接近1,虚值的话则更快的接近0。
因为市场参与者们,觉得跌破深度实值期权行权价的可能性很低,或是觉得涨破深度虚值行权价的可能性很低,于是时间价值就会被压低。
反之,如果市场参与者们觉得未来S的价格波动比较大,那么就觉得跌破深度实值期权行权价、或涨破深度虚值期权行权价的可能性比较大,于是时间价值就会被推高。
也就是说,市场参与者对未来价格波动幅度的主观预测,决定了这不同行权价间时间价值的递减幅度,于是就决定了Δ的变化速度,也就是决定了gamma值。
所以,在无风险收益率给定的前提下,这市场状态给出的θ值,跟gamma值,映射出了市场参与者集体意识下的σ。
这就是隐含波动率IV的本质。
那么怎么利用它盈利呢?
因为这是市场参与者集体主观意识决定了IV,而他们未必是理性的,他们的集体意识下导致的IV,极有可能偏离真实σ。
当然,这个真实σ只有上帝知道。但我们可以通过“参数估计”里面关于样本方差的性质,用历史数据来推测总体真实σ。
就是这个公式:
这个就是通过历史数据,估算真实方差,其中n越大,越逼近。
用对真实方差的估算值,开方后,就是对真实波动率σ的估算值,我们称之为HV。
然后拿HV跟IV对比,如果IV低于HV,就说明现在的期权价格下,IV被低估了。
一般情况下,市场最终呈现的,更有可能是跟HV接近的波动率。
那就意味着,这时候可以做多波动率,其方法是就是构建组合V-ΔS,赚取高卖低买的收入。
反过来,如果IV高于HV,那么就做空波动率,其方法就是构建组合-V+ΔS,这时候gamma亏损会较低,低于θ收益。
你也可以直接做多或做空看涨期权合约本身,因为如果上面操作的人多了,自然就推动V的价格,使之符合HV。
相信有人要问了,凭什么HV一定是对的,IV就一定是错的呢?难道就不可以机构提前收到了消息,预见到未来波动率会发生改变吗?
一般来讲,市场消息、或庄家的预先操盘,影响的是μ,而不是σ。因为一般都是机构提前知道利好或利空消息,于是提前布局,提前做多或做空标的。
而提前预知波动率?预知到未来价格会更不明朗,还是更明朗?
当然,这市场没有绝对的事情,其中还有“肥尾效应”,还有“波动率微笑曲面”所反映出来的信息,这会在未来专栏里详细讲解。
如果你想更深入的理解期权与BS定价模型,关注我,下一篇详细讲