在 RAG(检索增强生成)、语义搜索和大规模数据分析的浪潮中,嵌入模型(Embedding Model)是不可或缺的底层基石。然而,当前的 Embedding 研究正面临两大挑战:
英语中心化偏见:多数模型在英文以及中文上表现强悍,但在其他中低资源语言上力不从心。透明度鸿沟:顶尖模型(如 Gemini、Qwen3-Embedding 等)多为闭源 API 或仅开放权重,其训练数据和方法论往往秘而不宣,严重阻碍了开源社区的复现与进化。针对这些痛点,蚂蚁集团联合上海交通大学正式发布并开源了 F2LLM-v2。这不仅是一个性能霸榜的工具,更是对“开源透明”和“语言普惠”的一次深度践行。

开源地址:
GitHub:https://github.com/codefuse-ai/CodeFuse-Embeddings[1]Hugging Face:https://huggingface.co/collections/codefuse-ai/f2llm[2]1. 真正的“全开源”:数据、代码、检查点全量交付与市面上许多闭源接口或黑盒模型不同,F2LLM 团队始终坚持开源精神。
这一次,团队精心构建了一个包含6000万高质量样本的训练语料库,涵盖282种自然语言和40多种编程语言。最重要的是,这些数据全部源自公开资源,且团队公开了完整的训练配方、中间检查点以及相关代码。
这种全方位透明度不仅方便研究者复现,更为全球开发者构建真正包容、多语种的 AI 应用提供了肥沃的土壤。
2. 霸榜 11 项 MTEB,定义多语言 SOTAF2LLM-v2 在 MTEB(最权威的大规模文本嵌入评测基准)上的表现堪称惊艳。其14B与8B版本在 11 个 MTEB 分支榜单上摘得桂冠。
无论是欧洲语言、斯堪的纳维亚语系,还是波斯语、越南语等中低资源语言,F2LLM-v2 均刷新了 SOTA 记录。特别是在代码搜索领域,F2LLM-v2 延续了 CodeFuse 家族的强项,与团队数月前开源的代码专用嵌入模型 C2LLM 并列第一,成为开发者构建智能化代码库检索的首选。
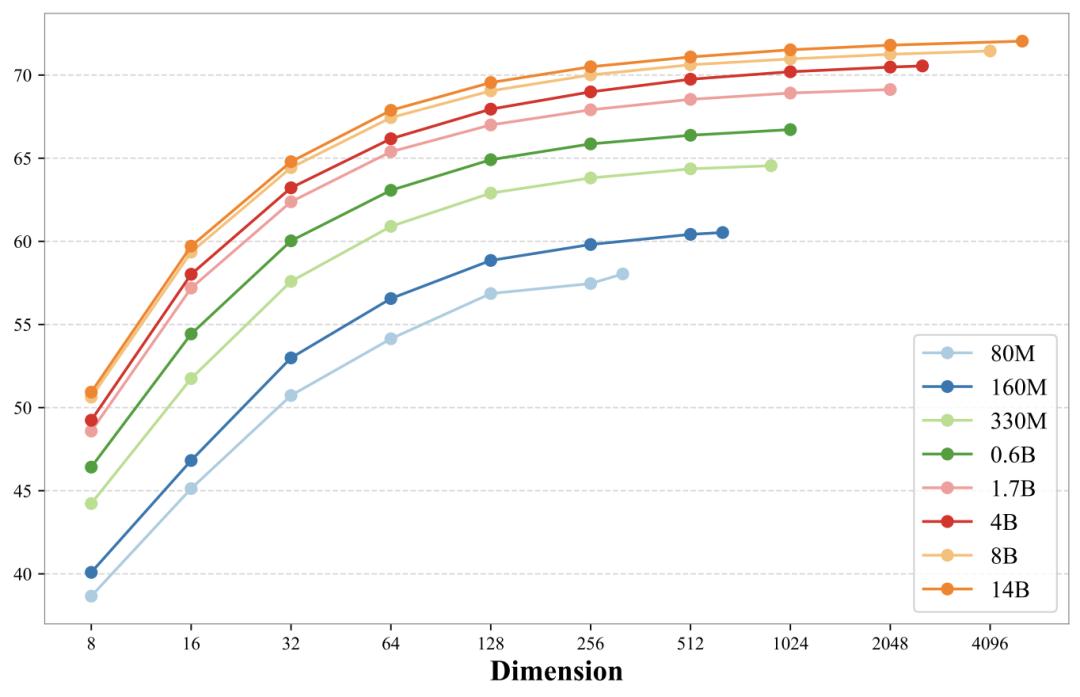
3. 全尺寸布局:从 80M 到 14B 的极致覆盖为了适应从边缘设备到大型数据中心的全场景需求,F2LLM-v2 推出了8 种不同尺寸的模型:
轻量级(80M / 160M / 330M):适用于对延迟极其敏感的终端应用。主流级(0.6B / 1.7B / 4B):兼顾性能与效率。重型(8B / 14B):为企业级检索系统提供最高精度的语义表征。值得关注的是,通过模型剪枝和知识蒸馏技术,小尺寸模型在推理效率大幅提升的同时保留了强大性能,打破了“小模型无高性能”的迷思。
同时,F2LLM-v2 家族的所有模型均支持套娃式表征,任意截取输出嵌入的开头维度即可获得接近全维度的性能。这为开发者在存储成本和检索速度之间提供了极大的灵活权衡空间。
 4. 结语:共同打造一个更包容、更透明的 AI 世界
4. 结语:共同打造一个更包容、更透明的 AI 世界F2LLM-v2 不仅仅是一个技术报告中的数字,它代表了开源社区的一种力量——不依赖封闭数据与技术,依然能做出世界顶级性能的模型。
无论你是正在构建多语言 RAG 系统的开发者,还是专注于向量表征的研究者,F2LLM-v2 都是一个值得点赞和深入挖掘的开源宝库。
立刻加入开源社区,共同探索 F2LLM-v2 的无限可能!
参考链接 https://github.com/codefuse-ai/CodeFuse-Embeddingshttps://huggingface.co/collections/codefuse-ai/f2llm