
引用
Salza P, Schwizer C, Gu J, et al. On the Effectiveness of Transfer Learning for Code Search[J]. IEEE Transactions on Software Engineering, 2023, 49(4): 1804-1822.
论文:https://pasqualesalza.com/publications/SalzaEffectivenessTransferLearning2022.pdf
仓库:https://github.com/pasqualesalza/tlcs
摘要
Transformer架构和迁移学习在自然语言处理领域取得了重大突破,显著改善了各种基于文本的任务的最新技术水平。本文探讨了如何将这些进步应用于并改进代码搜索。为此,我们在自然语言和源代码数据的组合上预先训练了一个基于BERT的模型,并在StackOverflow问题标题和代码答案对上进行了微调。我们的结果表明,预训练模型始终优于未经预训练的模型。在模型预先训练于自然语言“和”源代码数据的情况下,其性能也优于基于Lucene的信息检索基线。此外,我们还证明了先采用基于信息检索的方法,然后再采用Transformer,可以取得最佳的整体结果,尤其是在搜索大型搜索池时。当存在大量预训练数据而微调数据有限时,迁移学习特别有效。我们展示了基于Transformer架构的自然语言处理模型可以直接应用于源代码分析任务,如代码搜索。随着专门设计用于处理源代码数据的Transformer模型的发展,我们相信源代码分析任务的结果可以进一步改善。
1 引言
代码搜索是一种帮助开发者从大量代码库中根据自然语言查询检索源代码的工具,它能够帮助开发者快速找到实现特定功能的代码示例,发现提供特定功能的软件库,浏览代码库,甚至找到需要根据用户需求进行修改的代码片段。例如,开发者可能会搜索如何在Java中将字符串转换为整数,系统会返回相应的代码片段。
代码搜索的目的是返回与自然语言查询最相关的源代码片段。传统的检索系统通过比较查询中的token与代码库文档中的token,并返回重叠最多的文档。然而,这种方法在匹配自然语言查询和源代码文档时效果较差,因为查询中的token可能与源代码中的token不匹配。为了缩小这一差距,当前的研究工作采用了神经网络,特别是深度学习技术。这些技术大多源自自然语言处理领域,并已被成功应用于源代码分析。
在代码搜索的背景下,研究者们提出了一种新的方法:在大型未标记的源代码语料库上训练语言模型,并在小型但标记的代码搜索数据集上进行微调。这一方法旨在利用BERT模型的预测能力,通过迁移学习来提升代码搜索的性能。具体来说,研究者们提出了预训练两个BERT编码器的方法,一个用于处理查询,另一个用于处理代码,使它们能够独立地表示这两种数据形式。接着,将这些编码器整合成一个多模态嵌入模型(MEM),并在代码搜索的下游任务上进行微调。
本文提出了一种新的代码搜索方法,该方法结合了Transformer架构和迁移学习技术,创建了一个多模态嵌入模型(MEM)。接着,我们开展了一项广泛的实证研究,将我们提出的模型与现有的代码搜索解决方案进行了对比,包括DEEPCS和基于信息检索的LUCENE方法。此外,我们还探讨了一种两阶段的方法,先用LUCENE对搜索候选项进行初步筛选,再用MEM进行细致处理,并对这种组合方法的性能进行了评估。为了支持我们的研究,我们从STACKOVERFLOW获取的数据集展示了迁移学习的典型应用场景,包括预训练的源代码模型和用于数据挖掘、预训练及微调的源代码,这些资源都已在Github上开源。
2 技术介绍
本文提出的方法涉及两个基于BERT的预训练编码器,一个用于处理查询,一个用于处理代码,最终将这些编码器组装成一个多模态嵌入模型(MEM),并在STACKOVERFLOW问题与答案(Q&A)对数据上进行微调。图1展示了整个方法组合的工作流程。在本节中,我们详细描述了这种提议的方法,包括查询和代码编码器的预训练、STACKOVERFLOW Q&A对数据的挖掘,以及最终的MEM微调。

图1 方法的工作流程,从数据挖掘到最终的MEM模型构建
2.1 预训练阶段
作者在预训练阶段首先收集了六种完成了不同编程语言的函数定义并选取了CodeSearchNet做为实验数据集。之后通过tree-sitter解析器去除了文档的注释,完成对代码的标准化处理。接着选取了BERT做完元模型开始了两种预训练任务:掩蔽源代码建模和下一行预测。然后坐在设置了模型的训练步数并对模型进行了评估。具体的操作如下:
1. 数据收集:作者从GitHub的开放源代码项目获取函数定义数据,构建了预训练数据集。具体来说,作者使用了CodeSearchNet数据集,该数据集包含JavaScript、Java、Python、PHP、Go和Ruby六种不同编程语言的函数定义。最后,作者选择了CodeSearchNet数据集,因为它提供了大量机器可读格式的源代码样本。
2. 数据预处理:为了减少自然语言的出现,作者使用tree-sitter解析器去除了文档和注释,但保留了代码的原始格式,没有进行其他预处理。作者认为,代码片段通常不是有效的代码,所以不需要进行标准化处理。
3. 配置:作者采用了与BERT相同的预训练配置。具体来说,作者使用了与Devlin等人的BERTbase模型相同的配置,包括使用WordPiece分词,并保留大小写信息。预训练数据集的词汇量为30,522个词元,序列长度限制为256个词元。
4. 预训练任务:作者在源代码数据上进行了预训练,并采用了两个预训练任务:
a) 掩蔽源代码建模(MCM):该任务类似于BERT中的掩蔽语言建模任务。作者随机掩蔽输入序列中的15%的词元,并要求模型预测被掩蔽的词元。
b) 下一行预测(NLPred):该任务是一个二分类任务,要求模型判断给定的两个源代码行A和B是否连续出现。训练数据中,B有50%的概率直接跟在A后面,另外50%的概率是随机选取的代码行。
5. 训练:作者根据预训练数据集的大小调整了训练步数,以进行大约40个epochs的训练。作者使用了LAMB优化器,并限制训练为5个epochs。作者还调整了学习率、批次大小等超参数。
6. 评估:作者在预训练任务上获得了较高的准确率,表明预训练是成功的,并且模型学习到了有用的源代码抽象表示。
总体来说,作者通过在GitHub代码上预训练BERT模型,学习到了源代码的有用表示,为后续的代码搜索任务奠定了基础。预训练和下游任务使用不同的数据集,符合迁移学习的场景。
2.2 查询和代码对挖掘阶段
作者从StackOverflow使用BigQuery提取了包含JavaScript、Java和Python标签的问题和被接受答案,共获得约24万个查询-代码对。之后通过筛选完成数据清洗,只保留问题标题、被接受答案且含有代码片段、以及问题或答案得分不低于3的查询-代码对,以提升数据质量,构建得到新的数据集。
1. 数据提取:作者从StackOverflow使用BigQuery提取了包含JavaScript、Java和Python标签的问题和被接受答案。提取的数据包括问题标题、被接受答案的代码片段以及问题回答者的用户信息。
2. 数据质量提升:作者进行了以下筛选,以提升数据质量:
a) 只保留被问题提出者标记为“已接受”的答案,以确保答案与问题的相关性。
b) 去除答案中不含有代码片段的问题,只保留答案中包含代码的问题。
c) 合并同一个答案中的多个代码片段。
d) 移除代码片段中的非代码文本,例如去除代码注释。
e) 只保留问题或答案得分不低于3的问题-答案对,利用StackOverflow的用户投票信息过滤质量较差的样本。
f) 移除答案长度少于3行的问题-答案对。
3. 数据清洗:作者对代码片段进行了清洗,包括合并同一答案中的多个代码片段,去除代码片段中的非代码文本,例如代码注释。此外,由于StackOverflow的代码片段通常难以静态解析,作者没有使用解析器去除注释,而是直接移除了答案中的非代码文本。
4. 数据集构建:经过上述步骤,作者为JavaScript、Java和Python分别构建了约8.5万、7.1万和8.7万个问题-代码对的数据集。这些数据集用于后续的模型微调。
通过以上步骤,作者从StackOverflow构建了大规模的代码搜索数据集,这些数据集反映了真实的代码搜索场景,为后续的模型微调提供了充分的数据支持。此外,作者还移除了多语言问题的交集,以确保数据集的纯净性。
2.3 微调阶段
作者使用MEM架构,其中一个编码器用于查询,另一个编码器用于代码。微调目标是减小查询和代码向量在语义空间的距离。作者使用与Husain等人相似的配置,并使用LAMB优化器进行训练。微调数据集包含约24万个查询-代码对。
1. 配置:作者使用MEM(Multimodal Embedding Model)架构,其中一个编码器用于查询,另一个编码器用于代码。微调目标是减小查询和代码向量在语义空间的距离。
2. 超参数设置:作者使用了与Husain等人相似的配置,并使用LAMB优化器进行训练。作者将代码编码器的最大序列长度增加到256,以适应平均代码长度约为180个词元。同时,作者将查询编码器的最大序列长度保持在30,因为平均查询长度约为9个词元。此外,作者还使用了与预训练模型相同的词汇量、隐藏层大小和中间层大小。
3. 训练:作者将训练数据划分为训练集(90%)和验证集(10%),并进行了10折交叉验证。在每一折中,作者使用训练集进行训练,使用验证集进行验证,并记录性能指标。
4. 评估:作者在测试集上评估模型的性能,使用MRR、Top-k准确率、Aroma准确率等指标来评估代码搜索的效果。作者还比较了仅使用代码数据、仅使用自然语言数据、以及同时使用代码和自然语言数据进行预训练的模型在微调任务上的表现。
通过微调阶段,作者在StackOverflow数据集上对模型进行了微调,以适应真实的代码搜索场景。作者使用了大规模的StackOverflow数据集,这为模型提供了充分的训练样本,以学习查询和代码之间的语义关系。
3 实验评估
研究问题。在本文中,我们研究以下研究问题:
RQ1:预训练的英语自然语言模型是否可以提高代码搜索性能?
RQ2:预训练的单语种源代码模型是否可以提高代码搜索性能?
RQ3:预训练的英语自然语言模型与预训练的单语种源代码模型组合是否可以提高代码搜索性能?
RQ4:预训练的多语种源代码模型是否可以提高代码搜索性能?
RQ5:信息检索方法与迁移学习模型相结合是否可以提高代码搜索性能?
数据集设置:我们对所有实验应用了10倍交叉验证,将整个数据集划分为十个等份,其中九份用于训练,一份用于测试。我们进一步将九份训练数据分为90%的训练数据和10%的验证数据,这样我们得到了表1所示的折数大小。
表1 10折划分后的近似折叠大小

评估指标:本文选取了三种评估指标:
1)平均倒数排名(Mean Reciprocal Rank, MRR):相关文档的倒数的平均排名。例如,如果相关文档排在第4位,则其倒数为1/4。MRR是多个查询的倒数排名的平均值。
2)top-k准确率:预测文档在相关文档前k个中的准确率。例如,top-1表示预测文档是否为相关文档中的第一个,而top-3表示预测文档是否在前三个相关文档中。
3)基于Aroma的相似度分数:利用Aroma工具计算预测答案与实际答案之间的结构特征重叠数量,并基于此计算预测答案与实际答案之间的相似度分数。
对比模型:本文对四种模型进行了对比:
1)预训练的查询模型(RQ1)。作者使用Devlin等人的预训练英文模型BERTbase。其中,查询编码器的权重使用预训练的英文模型的权重进行初始化,代码编码器Ec没有预训练,即其权重使用随机值进行初始化。
2)预训练的代码模型(RQ2)。作者使用我们自己预训练的源代码模型来初始化代码编码器Ec的权重。其中,查询编码器Eq的权重使用随机值进行初始化。
3)预训练的查询和代码模型(RQ3)。作者将预训练的查询和代码模型结合起来,看它们如何相互补充。查询编码器Eq和代码编码器Ec的权重都是从各自的预训练模型中恢复的。
4)预训练的多语言代码模型(RQ4)。作者研究了预训练的涵盖多种编程语言的源代码模型。我们预训练了两种这样的模型:一种是基于JAVASCRIPT、JAVA和PYTHON数据(TOP)的模型,另一种是基于JAVASCRIPT、JAVA、PYTHON、PHP、GO和RUBY数据(ALL)的模型。
基线:本文设置了五个基线,分别为:
1)随机模型(Random):使用随机初始化的权重对查询编码器和代码编码器进行训练,不进行微调,直接计算余弦距离。
2)零样本文本学习(Zero-shot):评估所有模型,但不进行微调。此配置可用于估计源代码模型本身的效果。
3)无预训练(No pre-train):对MEM模型进行训练,但不进行预训练。此基线可用于测量迁移学习的效果。
4)信息检索(LUCENE):使用LUCENE构建基线,采用默认参数。LUCENE是一个广泛使用的开源搜索引擎,基于倒排索引结构和查询文档的tf-idf权重进行文档检索。
5)DEEPCS:使用DEEPCS模型进行评估,被认为是目前代码搜索方面的最新技术。
Answer to RQ1
图2展示了针对1K策略的几种模型的结果:(1)LUCENE LU-(语言),(2)DEEPCS DC-[语言]-(语言),(3)非预训练的MEM MEM-{NO+NO}-[语言]-(语言),(4)预训练的查询编码器MEM-{EN+NO}-[语言]-(语言),但代码编码器未经过预训练的模型。
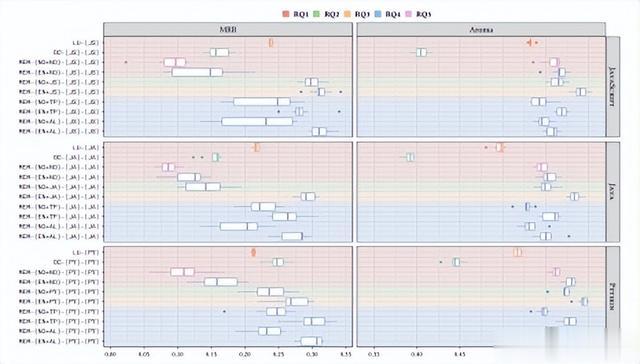
图2 使用1K策略对单语言测试集进行MRR和Aroma值的比较
可以明显看出,在所有编程语言中,LUCENE基线模型的表现优于所有MEM模型,JAVASCRIPT、JAVA和PYTHON的MRR中值分数分别为0.2374、0.2170和0.2128。然而,与非预训练的基线模型相比,预训练模型显示出一定的改进。DEEPCS在所有语言中的表现均优于所有MEM模型,只有在PYTHON(0.2474)的情况下超过了LUCENE。然而,从Aroma分数来看,MEM模型的表现优于其他模型,JAVASCRIPT、JAVA和PYTHON的Aroma中值分数分别为0.5663、0.5520和0.5805。在这方面,DEEPCS的Aroma分数明显低于其他方法,JAVASCRIPT、JAVA和PYTHON的中值Aroma分数分别为0.4044、0.3924和0.4444。
在全面策略(见表2)的情况下,LUCENE在MRR指标上超过了所有其他方法:JAVASCRIPT、JAVA和PYTHON的MRR值分别为0.1328、0.1267和0.1217。特别是,仅查询预训练模型在JAVA(0.0024)和PYTHON(0.0023)的情况下的MRR中值表现非常差。然而,MEM-{EN+NO}-[LANG]-(LANG)模型和LUCENE的Aroma分数在JAVASCRIPT的情况下相对相似,分别为0.4360和0.4299;在其他情况下,LUCENE的Aroma分数优于所有其他方法,JAVA为0.4055,PYTHON为0.4248。
表2 计算指标的所有折叠的中位数值

总结:仅查询预训练的MEM-{EN+NO}-[LANG]-(LANG)模型,在JAVASCRIPT、JAVA和PYTHON的情况下,无论是1K策略还是全面策略,都没有在MRR分数上超过LUCENE和DEEPCS的基线。然而,在1K策略中,它们获得了与LUCENE相似的Aroma分数。
Answer to RQ2
我们现在参考图2中带有预训练代码编码器的模型MEM-{NO+LANG}-[LANG]-(LANG),即我们不预训练查询而只预训练代码编码器。在MRR方面,当考虑1K策略时,仅代码预训练的模型在所有数据集上都优于仅查询预训练的模型。虽然在JAVA数据上,预训练模型落后于LUCENE基线,但在JAVASCRIPT和PYTHON的情况下,预训练模型实现了更高的中值MRR。JAVA性能较低可以通过细调数据集的大小相对于JAVASCRIPT和PYTHON集合较小来解释(见表61。在PYTHON的情况下,DEEPCS仍然是最优的方法。至于Aroma分数,仅查询预训练的模型之间没有显著差异。在全面策略的情况下,仅代码预训练的模型提高了所有三种语言的MRR分数。仅代码预训练的模型在Aroma方面并不比仅查询预训练的模型更好,这种情况仅适用于JAVASCRIPT。然而,该模型在统计上略优于LU-(JA)。至于PYTHON,仅代码预训练的模型比仅查询版本更好。
总结:在考虑1K和全面策略时,仅代码预训练的MEM-{NO+LANG}-[LANG]-(LANG)在MRR和Aroma分数方面表现优于仅查询预训练的MEM-{EN+NO}- LANG]-(LANG)。然而,在1K策略和MRR分数的情况下,LUCENE仍然是JAVA和JAVASCRIPT的最佳模型,而MEM-{NO+PY}-[PY]-(PY)的表现与DEEPCS相似。在全面策略的情况下,仅代码预训练的MEMs在每种语言上仍然落后于LUCENE。
Answer to RQ3
我们介绍了同时具有预训练查询和代码编码器的模型MEM-{EN+LANG}-[LANG]-(LANG)。如图2所示,当将预训练的查询编码器与代码编码器MEM-{EN+ LANG}-[LANG]-(LANG)结合使用时,MEM模型的表现优于LUCENE和其他基线模型,包括迄今为止在PYTHON情况下表现最佳的DEEPCS模型。这证实了我们的研究问题3(RQ3)的假设,即结合每个模态的预训练模型将导致在代码搜索方面有更显著的改进。在Aroma方面,所有语言都有显著的提升:JAVASCRIPT为0.5902,JAVA为0.5834,PYTHON为0.5941。
在使用全面策略时,查询和代码预训练编码器的联合贡献相对于仅在一个模态上预训练的版本,在MRR和Aroma分数上都有所改进,但尚未超越LUCENE的性能。
总结:在1K策略中,预训练的查询和代码MEM-{EN+LANG}-[LANG]-(LANG)模型在MRR和Aroma分数方面是最佳模型。然而,在使用全面策略时,MEM模型并没有超过LUCENE的性能。
Answer to RQ4
我们介绍了在多种编程语言上预训练的MEM模型的结果。首先,我们关注在JAVASCRIPT、JAVA和PYTHON数据(TOP数据集)组合上预训练的模型。然后,我们展示了在JAVASCRIPT、JAVA、PYTHON、PHP、GO和RUBY数据(即ALL数据集)组合上预训练的模型的结果。虽然单一语言模型仅在单一语言语料库上进行了评估,但对多语言模型的实验额外测试了由JAVASCRIPT、JAVA和PYTHON组成的多语言语料库TOP的情况。
在TOP数据集上进行预训练。我们指的是图3中在TOP数据集上预训练并使用1K策略在单一语言语料库上评估的模型。现在我们还包括了使用预训练编码器的模型,即MEM-{NO+TP}-[LANG]-(LANG)和MEM-{EN+TP}-[LANG]-(LANG)。我们观察到,所有仅对代码编码器进行了预训练的模型,例如MEM-{NO+TP}-[JS]-(JS),其MRR分数表现相似或比它们的LUCENE基线更好。组合预训练模型,例如MEM-{EN+TP}-[JS]-(JS),在所有情况下都优于LUCENE基线。而Aroma分数则从未高于仅对代码和查询模态进行单一语言预训练的MEM版本,例如MEM-{EN+JS}-[JS]-(JS)。
至于Full策略,没有任何MEM能够超越LUCENE的性能。就Aroma分数而言,LUCENE与其他MEM之间没有太大的差异。

图3 使用1K策略,对TOP测试集的MRR和Aroma值进行比较
图3显示了在TOP测试集上评估的实验的MRR值指标的箱线图,考虑到1K策略。在评估这个测试集时,显著的是预训练的MEM在预训练至少代码模态时优于基线。值得注意的是,这些模型明显优于LUCENE和DEEPCS方法,MRR的中位值为0.4277(LUCENE为0.2521,DEEPCS为0.3241),Aroma为0.6348(LUCENE为0.5278,DEEPCS为0.4855)。
相反,在Full策略中,MEM-{EN+TP}-[TP]-(TP)模型稍微能够超越LUCENE的性能,MRR的中位值为0.1151,而LUCENE为0.1124。Aroma的中位值也略高于LUCENE,为0.4122,而LUCENE为0.3956。
在ALL数据集上进行预训练。最后,我们指的是在ALL数据集上预训练并在单一语言搜索语料库上评估的模型(见图2和图3)。同样,预训练查询编码器和代码编码器的组合产生了最佳结果。这些组合预训练模型优于未预训练的基线和LUCENE基线。然而,如果搜索在单一语言语料库上进行,那么ALL数据集并不是预训练MEM的理想选择。在这种情况下,更好的选择是在相同编程语言的单一语言语料库上进行预训练,例如MEM-{EN+JS}-[JS]-(JS)。这也可以通过单一语言预训练MEM的Aroma分数的最佳结果来证实。
在评估在ALL上预训练的模型进行多语言搜索时(见图3),我们观察到与在TOP上预训练的模型相似的结果,无论是在MRR还是Aroma方面。
至于Full策略,我们确认了上述结果,总体建议使用在目标语言上预训练的MEM,而不是在ALL上预训练的MEM。
总结:使用TOP进行预训练的多语言模型可以提高多语言搜索的MRR和Aroma性能,无论是1K还是Full策略。然而,在单一语言搜索的情况下,使用相同目标语言进行预训练,例如MEM-{EN+JS}-[JS]-(JS),结果最好。然而,在Full策略的情况下,LUCENE仍然是最佳选择。
Answer to RQ5
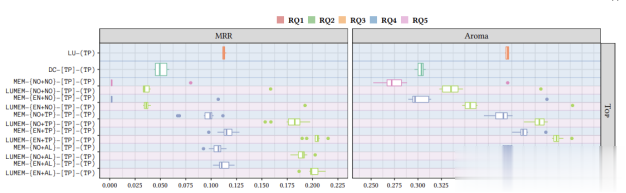
图4 组合LUCENE和MEM时,使用Full策略对TOP测试集进行MRR和Aroma值的比较
图4关注的是使用Full策略的多语言搜索情况(TOP),这是我们实验中最具挑战性的问题,考虑到搜索空间的大小,每个折叠约为24,347。完整的结果可以在表7和复制包中找到。从图中可以看出,LUCENE和MEM的组合,例如LUMEM-{EN+TP}-[TP]-(TP),持续提升了与相关MEM的性能,例如MEM-{EN+TP}-[TP]-(TP)。更有趣的是,组合模型能够在TOP语言的情况下显著超过LUCENE的MRR性能,即0.1124,当在英文和TOP上进行预训练时,即LUMEM-{EN+TP}-[TP]-(TP),中位值达到0.2050。至于Aroma分数,组合的LUMEM-{EN+TP}-[TP]-(TP)模型现在达到了最佳的中位值0.4478。 相同的现象也可以在JAVASCRIPT、JAVA和PYTHON的情况下得到验证。对于单一语言搜索,使用LUCENE和MEM的组合,无论是MRR还是Aroma值,都是迄今为止最高的。
总结:在所有编程语言中,LUCENE和MEM的组合在MRR和Aroma分数方面表现最佳。
转述:何家伟