如今,大语言模型(LLM)已深度渗透进我们的生产力骨架,无论是润色文案、自动生成演示文稿,还是复杂的代码重构与表格逻辑处理,AI 几乎无所不能。然而,随着应用走入深水区,考虑到数据隐私安全与长期订阅成本等因素,很多用户开始将目光转向 了本地部署,加上去年底 NVIDIA DGX Spark 的煽风点火,也让很多 一 线品牌开始推出基于该平台以 AI 算力为主的机型。
本次分享的技嘉 AI TOP ATOM 正是基于上述理念打造的个人 AI 超级电脑,它搭载了 NVIDIA 与联发科合作设计的 GB10 Grace Blackwell 超级芯片。专为个人开发者、数据科学家及 AI 研究人员打造,打破了顶级算力必须依赖云端或大型机房的局限,在保持便携性的同时,为本地 AI 推理与微调提供了极具弹性的解决方案。
 硬件赏析及配置
硬件赏析及配置▼简单看看这台设备吧,尺寸方面,技嘉 AI TOP ATOM 和大部分迷你主机差不多,准确数据为 150 x 150 x 50.5mm,枪灰色的金属机身,表面没有任何装饰,主打沉稳简洁,下图是和 Macmini M4 的对比。


▼配件方面包括主机和电源适配器,接口走的 Type-C,支持 PD3.1 快充协议,最大输出功耗 240W,理论来说用氮化镓充电器也能推。

▼主机正面没有任何冗余接口,视觉上极为干练,仅点缀以技嘉英文 Logo。通体贯穿的 MESH 散热网孔若隐若现,这种“全面透气”的构造显然是为了应对 GB10 超级芯片在高强度算力输出下的散热需求,确保气流能毫无阻碍地带走内部热量。

▼接口配置上,技嘉 AI TOP ATOM走的是极致精简且高效的路线。侧边集成了 4 枚 Type-C 接口(含电源输入口)与 HDMI 2.1 高清接口,能够满足日常所有的外设接入与显示需求。而 10G 万兆网口的加入,则确保了在局域网内传输海量训练数据集时的吞吐效率。

▼最右边的则是普通用户很少见到的 NVIDIA ConnectX-7 智能网卡。这原本是数据中心级设备才拥有的专属组件,它支持高达 400 Gb/s 的传输速率,几乎消除了数据交换的物理屏颈。更重要的是,它不仅能提供惊人的 400 Gb/s 超高带宽与极低延迟,而且支持将两台 AI TOP ATOM 串联为算力集群。利用双机共享算力和内存实现 1+1>2 的性能飞跃,让本地处理数千亿参数的超大规模模型成为可能。

▼拆机还是比较简单的,固定螺丝隐藏在机身底部的胶条下。

▼揭开底盖后是两根布局独特的 WiFi 天线。在如此紧凑的空间内采取这种安置方式确实不多见,显然是为了规避内部复杂电子元器件的信号干扰,确保无线连接的稳定性。

▼内部的散热规格堪称“暴力”。为了压制 GB10 超级芯片的惊人算力,它配备了双涡轮(Blower)风扇阵列,搭配厚度极其扎实的散热鳍片组。结合其全铝合金外壳的物理导热特性,这套散热方案即便是在 7x24 小时的 AI 满载训练任务下,也能提供令人心安的冷酷表现。

▼尾部的散热格栅

▼这风扇拆掉后能看到主板布局,左边是 NVIDIA ConnectX-7 智能网卡,主要作用就是前面提到的集群扩容

▼主机核心就是这块 NVIDIA GB10 Grace Blackwell 超级芯片,这标志着桌面端正式进入了“超级芯片”时代,优势方面包括:
异构计算核心: GB10 完美集成了 Blackwell GPU 与基于 ARM 架构的 Grace CPU。其中 CPU 部分包含 20 个高性能核心(由 10 个 Cortex-X925 与 10 个 Cortex-A725 组成),确保了在处理复杂逻辑与数据流时的极致能效比。恐怖的 AI 性能: Blackwell GPU 配备 6144 个 CUDA 核心,并采用第五代 Tensor Core。在 FP4 精度计算下,单台设备可提供高达 **1 PFLOPS(每秒 1000 万亿次)**的 AI 运算性能。这使得单机即可支持最高 2,000 亿参数的 AI 模型。NVLink-C2C 互连技术: 不同于传统的 PCIe 总线,该机采用 NVLink-C2C 技术实现 CPU 与 GPU 的高效协同,带宽高达 900GB/s(约为 PCIe 5.0 的 5 倍)。这种超高带宽确保了在微调大规模模型时,数据传输不再成为瓶颈。集群扩容潜力: 针对更高需求,AI TOP ATOM 支持通过集群串接。两台设备串联后,可执行高达 4,050 亿参数的超级模型。结合 NVIDIA 完整的 AI 软件栈,它为本地 AI 计算提供了前所未有的适应性。▼右侧为处理器区域,技嘉 AI TOP ATOM 采用了 128GB LPDDR5X 内存与 4TB NVMe 存储的顶配方案。其内存带宽达到了惊人的 273GB/s,这种极致的配比正是为了应对本地化 200B 大模型的严苛需求,让复杂的 AI 推理与微调任务在本地运行变得游刃有余。

▼存储部分,该机在主板背面配备了 4TB 三星 PM9E1 SSD(M.2 2242 规格)。依托三星 5nm “Presto” 主控与 V8 TLC V-NAND 的核心组合,存储性能直达 PCIe 5.0 顶峰,顶部则是天线的固定区域。
 系统体验及算力测试
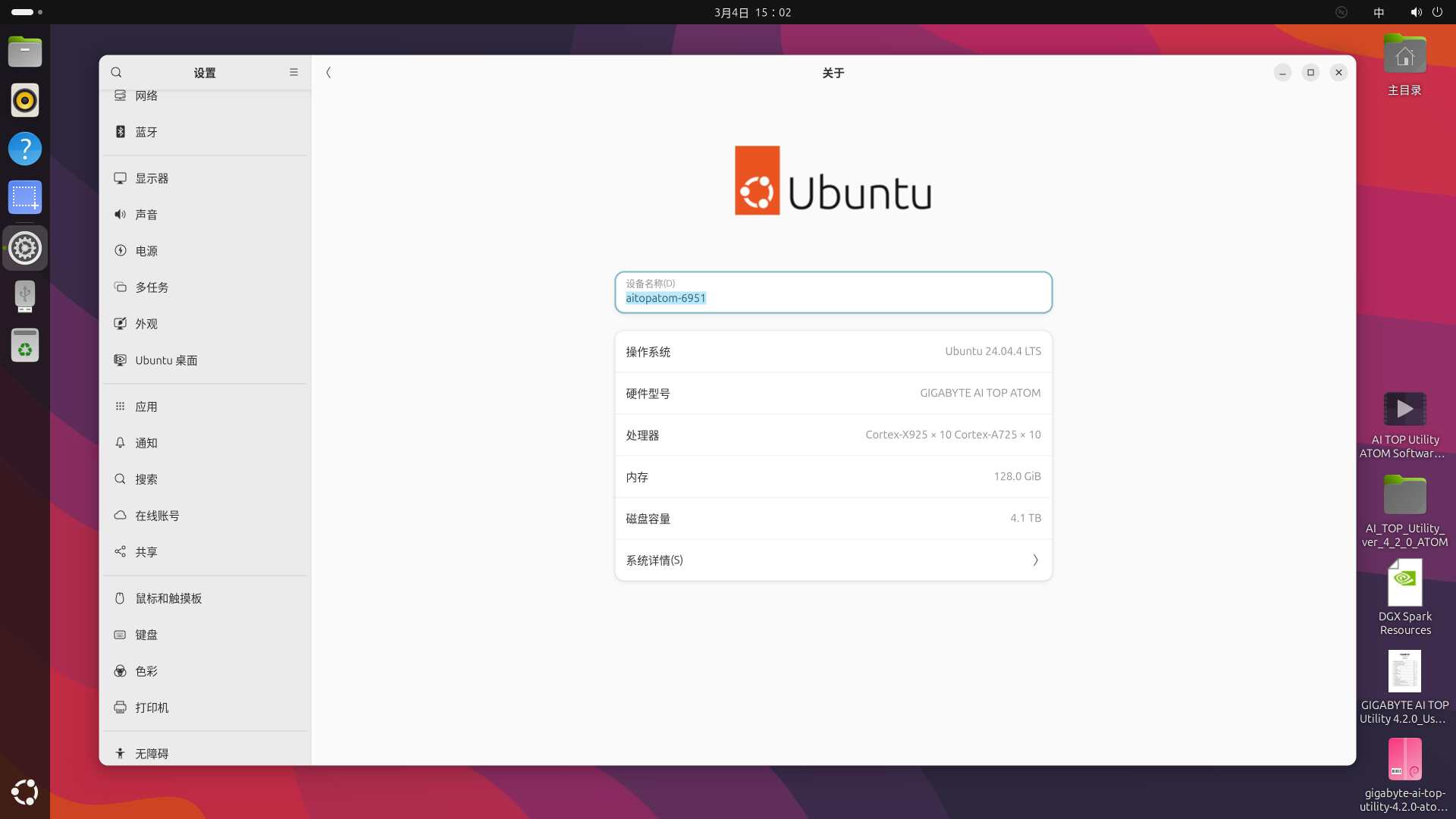
系统体验及算力测试▼系统方面,技嘉 AI TOP ATOM 自带经过优化的 Ubuntu 定制环境,在保障 AI 开发兼容性的同时,内置了全套生产力工具。
不过从系统也能看到,该机面向的用户群体还是有很强针对性的。
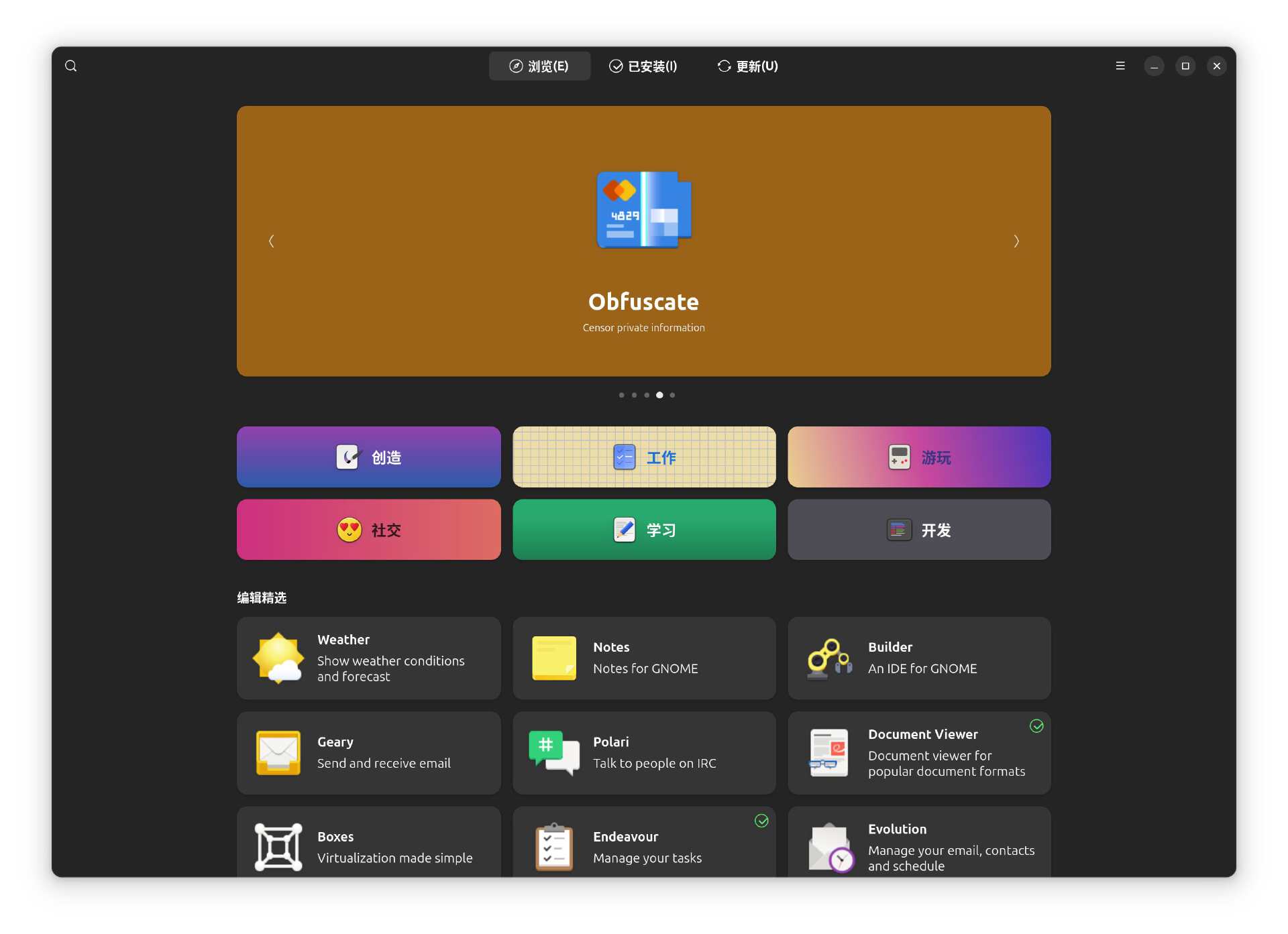
▼内置软件从用于网页浏览与查阅文献的 Firefox,到支持工具自由扩展的应用商店,再到满足文档管理需求的内置办公软件,AI TOP ATOM 真正做到了从“开发实验”到“通用办公”的平滑切换。


▼应用市场
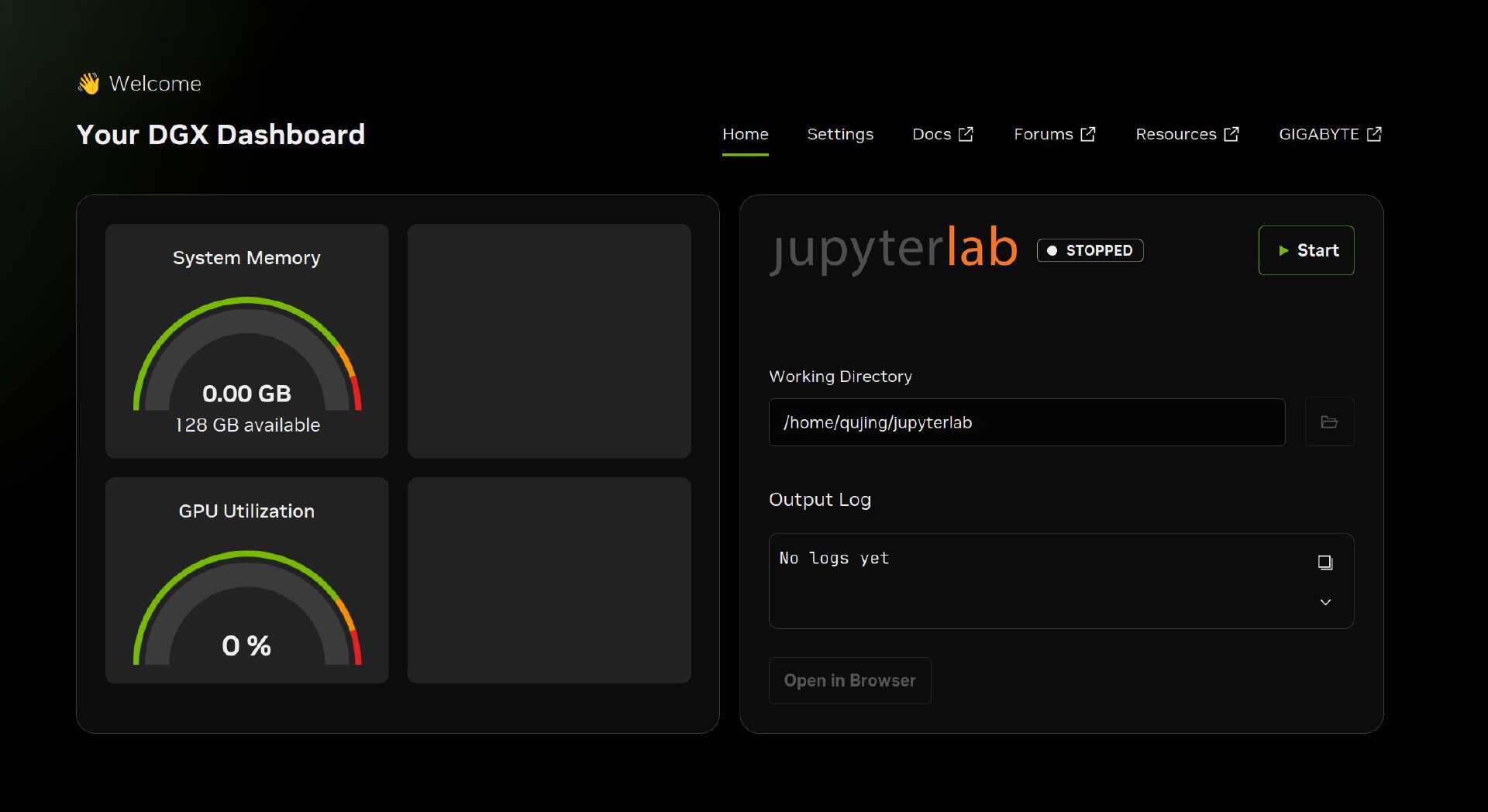
▼技嘉 AI TOP ATOM 在 AI 方面的优势还是很大的,主机内嵌了 NVIDIA AI 软件栈,提供各式工具、开发框架与函数库,以加速 AI 项目开发流程。
▼支持多种模型下载
▼其次,主机还内置了 AI TOP Utility ,这是技嘉专门为为本地 AI 训练而生的全方位解决方案,它不仅支持高达 236B 参数规模的 AI 模型,同时直观的 GUI(图形用户界面)也让用户上手更轻松,操作更直观,整个的操作流程像使用普通软件一样简单。
注意,这个并非开机内置软件需要自己下载和调试。
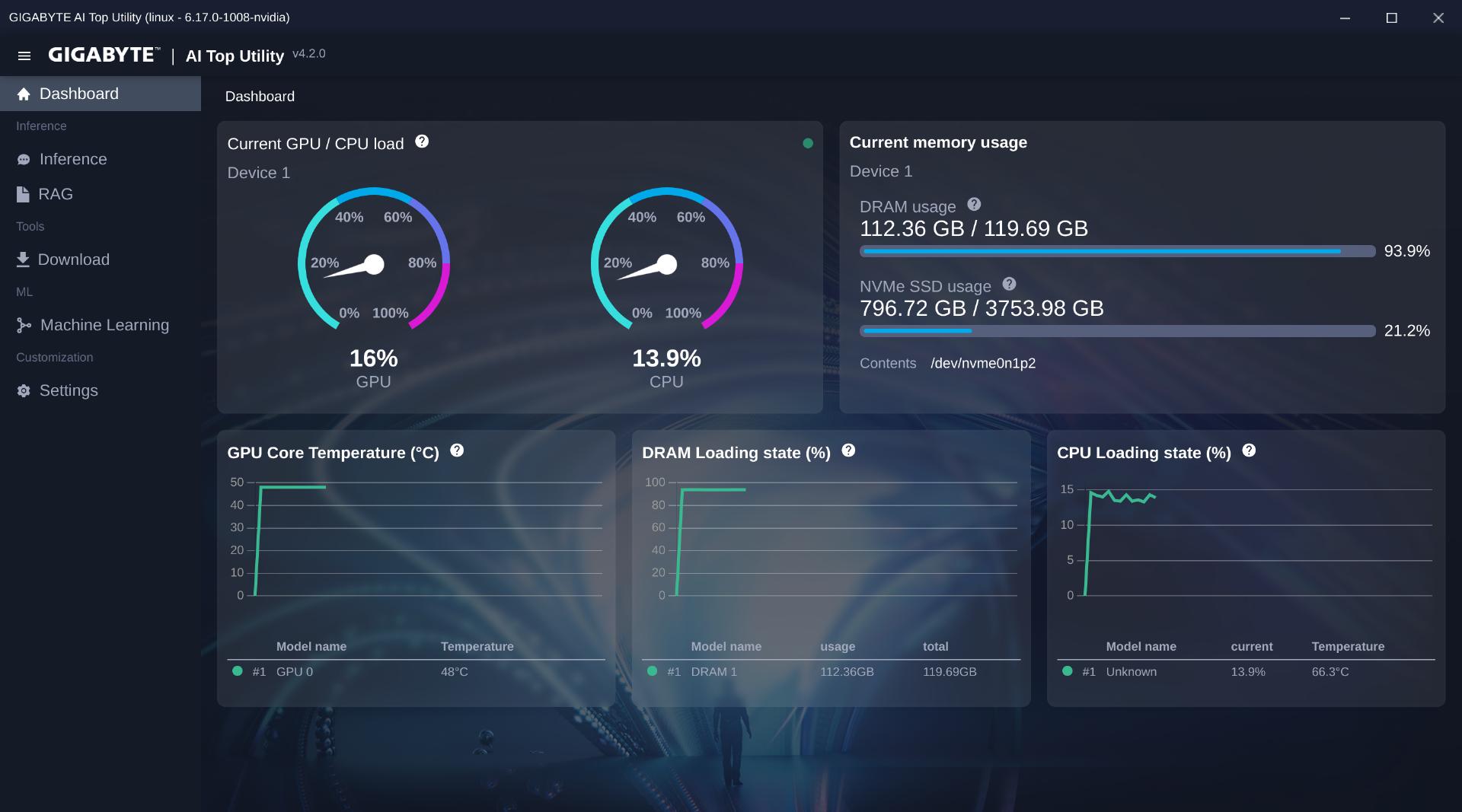
▼同样可以自由下载各种模型。
▼另外,技嘉的合作伙伴趋境科技提供了适配ATOM的自研大模型管理平台,对于非专业用户更容易上手。它内置智谱GLM-4.5-air-106B大语言模型、GLM-4.6V-106B 多模态大模型及其他主流大模型与趋境自研的推理引擎、模型运维平台,开机即用,无需耗时配置。此外还能作为 AutoGLM 的本地后端使用。
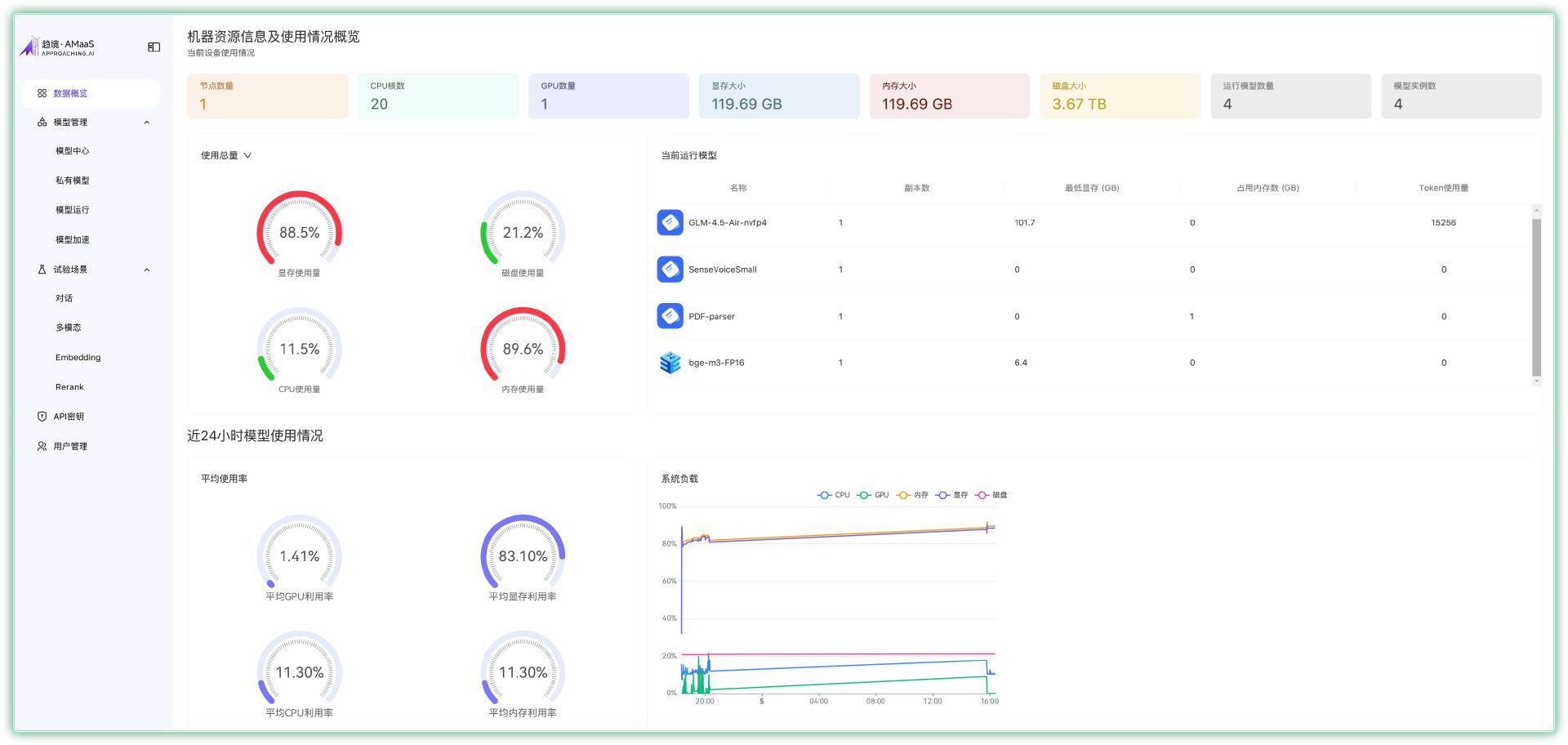
▼然后是模型管理中,可以看到预装的一系列AI大模型,并对其进行了整合分类。
而且 AMaaS 支持智能调整 / 检测模型,以及查看 Token 数。
比如图中的 GLM-4.6V-106B 千亿参数多模态大模型,这是首次在模型架构中将Function Call(工具调用)能力原生融入视觉模型,打通从“视觉感知”到“可执行行动”(Action)的链路,为真实业务场景中的多模态 Agent 提供统一的技术底座。
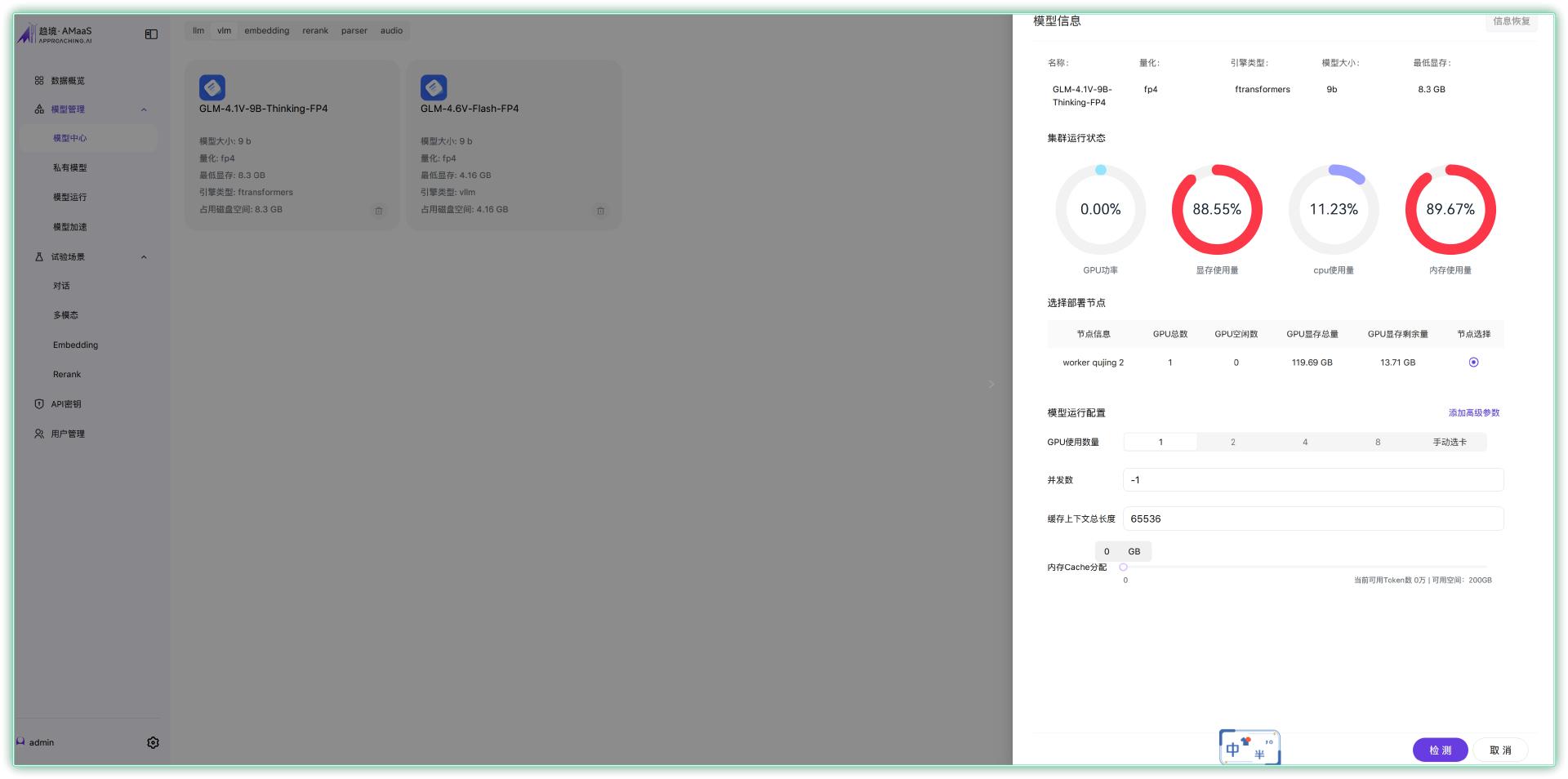
▼部署完成后,AMaaS 的实验场景可以对对话、文本、图形等资料进行测试
比如选择模型“GLM-4.5-Air-nvfp4”
对话“桌子上有 3 只朝上的茶杯,每次翻转 2 只,能否经过若干次翻转使得 3 只被子的杯口全部朝下呢?”
最后的结果是不可能(正确答案),每秒输出 22.32 tokens
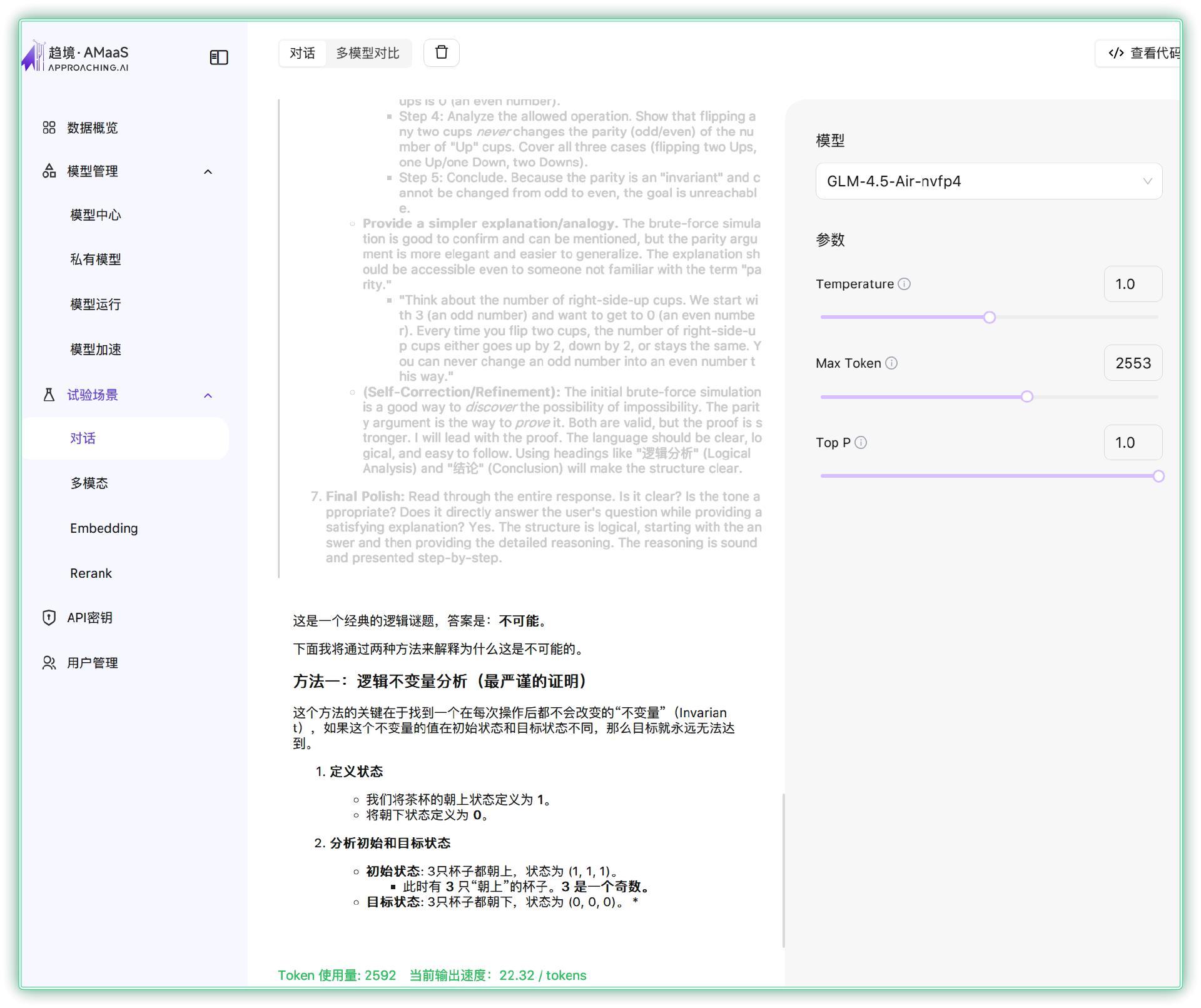
▼技嘉 AI TOP ATOM不仅提供强大的模型推理能力,还内置了 ready-to-use 的开发环境与实用工具,涵盖从模型定制到智能应用的完整链路:
比如趋境 · 智问就是最常用的 AI 工具,它提供本地知识库与AI对话功能,可直接管理私密科研资料与工作文档,打造完全私有的智能办公体验。真正是的使用界面是趋镜·智问,这里提供了对话、AI应用、长文写作、知识库等多种场景
▼比如问它“魂类游戏的定义是什么,举例几款典型游戏”
结果出来的很快,定义也很清晰
 桌面的“超算中心”
桌面的“超算中心”
“小体积、大算力”是对技嘉 AI TOP ATOM 最直观的评价,但其背后的意义远超硬件本身。
过去,涉足大模型意味着巨额的服务器投入与昂贵的算力租赁,今天,技嘉 AI TOP ATOM 将这种“大厂专利”浓缩进了一个极致紧凑的机身中。正如几十年前个人电脑将算力从机房带向桌面一样,ATOM 正在降低 AI 创新的准入门槛。 凭借极致的能效比与稳健的本地表现,AI TOP ATOM 不仅是一台性能怪兽,更是通往“个人超算”未来的必经之路。