在AI大模型和智能应用高速发展的今天,显卡巨头NVIDIA再度出击,带来了面向未来的革命性产品——全新Rubin架构GPU家族。近日,NVIDIA正式宣布Rubin CPX GPU的相关信息,亮点纷呈,直接将AI推理和上下文处理能力推向新高峰。

---
Rubin CPX:专为长上下文AI推理打造
NVIDIA Rubin CPX是一款专为处理超长上下文、AI智能体和大规模推理场景设计的GPU新品。它源自NVIDIA下一代Rubin架构,采用单芯片设计,虽然官方还未公布具体CUDA核心数量,却已透露出诸多旗舰级参数:
- 显存容量高达128GB,采用GDDR7新一代高速显存
- 内置4个NVENC编码器和4个NVDEC解码器,视频处理能力强悍
- 在NVFP4数据精度下,推理性能高达30 PFlops(每秒300万亿次浮点运算)
- 支持百万级Token的上下文推理,远超现有AI GPU处理极限
- 在长上下文AI场景下,注意力机制性能比GB300 NVL72提升最高3倍
需要强调的是,Rubin CPX虽然已官宣,但真正上市还要等到2026年底。这给AI行业和超级计算领域留下了极大想象空间。
---
全新一代超级AI服务器同步曝光
除了Rubin CPX,NVIDIA还披露了新一代AI超级服务器的细节:
- Vera Rubin NVL144:旗舰AI训练和推理平台,每机架配备36颗Vera CPU、144颗Rubin GPU,1.4PB/s HBM4带宽,最高75TB存储,总算力高达3.5 EFlops(每秒350亿亿次),比上一代提升3.3倍。
- Vera Rubin NVL144 CPX:整合72颗Rubin CPX,组成144颗GPU+36颗CPU的顶级阵容,内存带宽更达1.7PB/s,极速100TB存储,单机架算力可达8 EFlops(每秒800亿亿次),提升幅度达到7.5倍!
更惊人的是,NVIDIA允许双机架组合,配置、带宽和算力直接翻倍,实现超大规模AI集群的极致扩展。

---
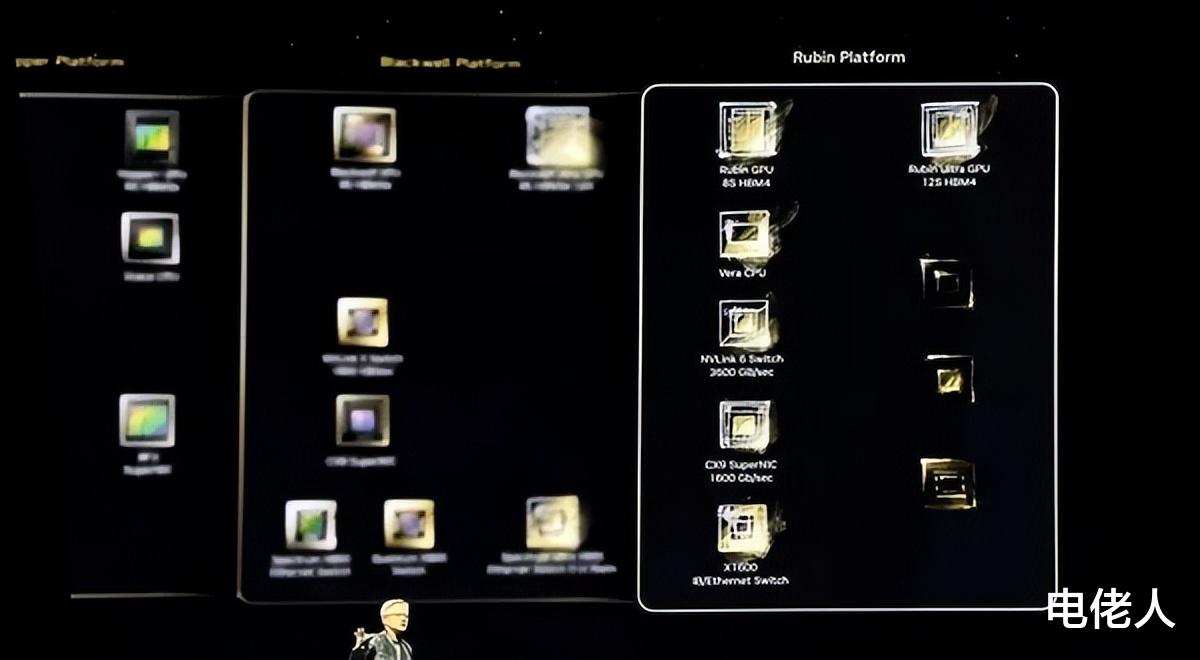
Rubin平台全线进展:GPU、CPU、网络芯片协同升级
NVIDIA还透露,Rubin GPU和Vera CPU已在台积电顺利流片,采用3nm EUV工艺,配套CX9 Super NIC网卡、NVLink 144交换机芯片、硅光等新技术,整体生态全面升级:
- Rubin GPU:将取代现有Blackwell架构,首发R100型号,支持8堆栈HBM4高带宽内存,2027年还将推出Rubin Ultra(12堆栈HBM4,更大容量、更高性能)。
- Vera CPU:与Rubin GPU协同,升级第六代NVLink互连,带宽高达3.6TB/s,CX9 NIC网卡带宽达1600Gbps(约160万兆)。
- 路线图展望:2028年还将推出Feyman GPU,持续技术领先。
Rubin架构的名字,致敬美国著名女天文学家Vera Rubin,象征着NVIDIA不断突破“黑暗物质”,探索AI算力极限。

---
AMD正面迎战,MI450要“全方位领先”?
面对NVIDIA强势推进,AMD同样不甘示弱,其高管公开喊话:“下一代AI GPU MI450将全面超越NVIDIA Blackwell和Rubin!”AMD计划在MI450上实现训练与推理的“双绝”,并推动AI和游戏GPU架构统一(UDNA),寻求在AI和消费市场双线突破。

---
总结:AI算力新时代已来,Rubin CPX开启超长上下文新纪元
NVIDIA Rubin CPX的发布,标志着AI推理和大模型上下文处理能力迈入百万Token时代,为智能体开发、超大模型推理、语义分析等场景带来革命性升级。新一代AI服务器和芯片平台,将为数据中心、云计算、科学研究提供前所未有的动力。
在全球AI竞争格局下,NVIDIA、AMD等巨头持续创新,也意味着未来的AI硬件生态将更加高效、智能,值得每一位关心技术进步的朋友持续关注。
---
参考资料:NVIDIA官方、快科技、外媒报道