
撰文| 王思易
编辑| 张 南
设计| 荆 芥
2026年开年以来,“harness”成了AI工程圈的新宠。

可这个概念与AI智能体有什么关系?
有网友在社交媒体上用一张淘宝搜索的截图回应,表示「很好理解」。
很离谱,但是我们把 AI 当牛马去指挥它干活,harness 翻译成套在 AI 身上的马具/束缚,也并不是全无道理。
Anthropic在2026年初发布了一篇工程博客《面向长程运行 Agent 的有效治理框架》,教用户如何从零用AI构建一个claude页面。

这样的复制所使用的不是更聪明的模型,而是一套精心设计的“harness”。
Anthropic的工程师构建了一个两阶段架构。
首先是一个“初始化agent”,它的任务不是写代码,而是搭建工作环境,生成一份包含200多项功能的需求清单。
然后是一系列“编码agent”,每个agent在独立的会话中只推进一小步,完成后把状态写回进度文件,确保代码处于可合并的干净状态,然后退出。下一个agent进入时,先读取进度文件和git日志,接着从上次中断的地方继续。
没有任何一个agent看到过完整的项目。它们依赖的是harness留在文件系统中的结构化痕迹——进度日志、功能清单、架构文档,来重建上下文,延续工作。
整个过程中,模型的能力没有变化,变化的只是它被置入的工作环境。这就是agent harness的核心思想。
OpenAI声称用零人工代码构建了一百多万行代码的系统,核心同样不在模型本身,而在围绕模型搭建的那套harness工程。
Salesforce把harness比作法律体系——律师(模型)提供知识,但法庭、法条、陪审团(harness)才构成使法律运作的制度环境。
我们去图书馆学习,并不只是因为图书馆有书,而是因为整个空间的设计——安静、秩序、周围人的专注——在暗示人应该如何行为。去工位工作也不只是因为工位有显示器,而是因为工位周围的流程、权限、同事的在场构成了一种结构化的行为场域。
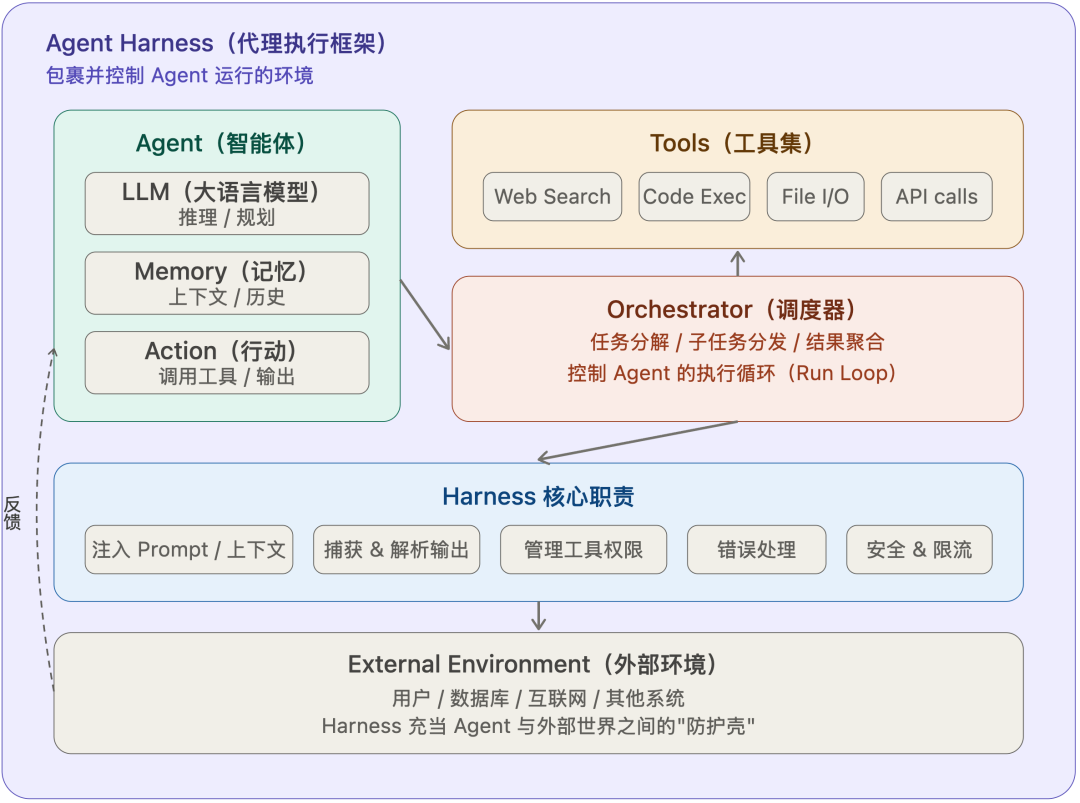
harness做的是同一件事。它为模型塑造一个“工作环境”,通过提示词预设暗示该怎么推理,通过权限边界暗示什么不该碰,通过验证循环暗示什么标准算“完成”。
01「harness怎么造? 」
值得注意的是,至今不存在一个关于harness的行业标准。
目前的实践已经自发地分化出三个层次。
第一层是工具自带的harness——Claude Code、OpenAI Codex、Cursor各自内置了一套agent循环、工具调用和权限治理机制,开发者无法修改,只能适应。
第二层是仓库级harness——开发者在项目中放置一个CLAUDE.md或AGENTS.md文件,写入项目特定的指令、架构约定和工作流程,模型在每次会话启动时读取这个文件来“理解”自己身处什么环境。
第三层是“组织级harness”——企业通过AI网关、审计日志、合规策略来治理所有agent的行为边界。
三层之中,最有意思也最体现harness工程本质的是第二层。一个典型的仓库级harness是这样的:
一个CLAUDE.md文件定义目标和优先级(正确性 > 安全性 > 速度);
一个progress目录存放进度日志和功能清单;
一个docs目录存放架构文档和质量标准;
一组hooks在每次代码修改后自动运行格式化和测试。
所有状态都存在文件系统里,而不是对话记忆中。
但"标准"和"事实标准"之间仍然存在巨大的鸿沟。HumanLayer的研究指出,前沿思维模型最多能可靠地遵循约150到200条指令,而Claude Code的系统提示已经占用了大约50条——这意味着CLAUDE.md中留给开发者的指令空间其实非常有限。
指令越多,遵循率不是从末尾开始下降,而是均匀地全面下降。
换句话说,harness工程目前仍处于手搓阶段,而非工程阶段。没有可验证的规范,没有可移植的标准,效果高度依赖经验和反复试错。
并且harness或许还有一个致命的短板。
制度有一种自我强化的惯性。它在使行动可靠的同时,也在使行动路径固化。
图书馆的安静氛围帮助集中注意力,但也让人不好意思大声讨论——即使讨论可能正是当下最有效的学习方式。
关键问题是,harness究竟是AI开发的长期范式,还是一个在特定技术瓶颈下不得不存在的过渡方案?
02「权宜之计? 」
目前关于harness,业内有一个类比:模型是CPU,上下文窗口是RAM,harness是操作系统。
这个类比比它的作者意识到的更有启发性——因为它恰好暴露了问题的实质。
操作系统之所以复杂,在很大程度上是因为RAM太小。
如果一台计算机有无限内存,操作系统中大量与内存管理相关的复杂逻辑——虚拟内存、页面置换、swap分区——就会变得不必要。
harness工程的绝大部分复杂性,同样源于上下文窗口的匮乏。
上下文窗口是大语言模型一次性能“看见”的全部信息的硬上限。
提示词、系统指令、对话历史、上传的文档、工具调用的返回值、模型自己的输出,所有这些共用同一个预算。超出就截断,截断就丢失,丢失就出错。
围绕这个约束,整个行业发展出了一套精密的上下文管理机制,去年流行的Rag架构就是其中之一。
而一个很少被提及的事实是:对于大量真实场景来说,上下文窗口可能已经够大了——或者至少没有harness工程的叙事所暗示的那么紧张。
拿医疗场景来说。一次住院的病历平均大约130页,换算成token大约四万多——这还是纸质时代充满冗余的计数方式,同一份诊断记录平均重复出现在病历的20个不同位置。
一个慢性病患者的纯文本终生病历,即使跨越数十年,也很难超过十几万到二十几万token。每位患者每年生成的结构化文本数据约4MB,但其中绝大部分是重复的表单字段和编码数据。
工程日志也是类似的,即使一个运行了多年的大型项目,其文本日志量也远达不到需要一亿token窗口的地步。
那么上下文到底被谁吃掉了?
答案有些讽刺。真正消耗上下文的,往往不是原始数据本身,而是agent在多步运行过程中产生的中间产物。每一次工具调用的返回值、每一轮推理的中间输出、每一个子agent的报告,这些东西在长时运行中指数式膨胀。
也就是说,harness不得不解决的上下文危机,有很大一部分是agent自己的工作方式制造出来的。这就好比一个行政体系不断膨胀的主要原因不是事务本身变复杂了,而是行政流程自身产生的文书量在增长。
当然有一个真正的例外场景,代码仓库。
大型代码库确实可以轻松达到数百万甚至数千万行。
但对于医疗、法律、金融、科研这些知识密集型领域——恰恰是AI agent最被期待大展身手的领域——harness所解决的上下文不足问题,其严重程度可能被系统性地夸大了。
即便如此,上下文窗口领域正在以惊人的速度发展。
Epoch AI在2025年中的一项研究发现,自2023年以来,前沿模型的最长上下文窗口以每年大约30倍的速度增长。
更值得注意的是,模型有效利用这些上下文的能力增长得更快——在Fiction.liveBench和MRCR两个长上下文基准测试上,顶级模型达到80%准确率的输入长度在短短九个月内增长了超过250倍。
竞争格局已经进入了百万级甚至千万级。
Google的Gemini提供两百万token。Meta的Llama 4 Scout宣称一千万token,并且能在单块H100 GPU上运行。
更极端的是Magic这家只有23个人的初创公司。他们训练了名为LTM-2-Mini的模型,上下文窗口一亿token——相当于一千万行代码或七百五十部小说。他们获得了红杉资本的投资。
上下文窗口的技术迭代不是一个“是否”的问题,而是一个“多快”的问题。有预测认为,到2027年百万token以上的上下文将成为旗舰模型标配,到2028年真正的无限上下文方案可能投入生产。
即使对这个时间表打一个悲观折扣,趋势不可逆转,未来大模型必然会有更大的上下文窗口、更好的利用率、以及更低的成本。
但这里有一个问题:上下文管理真的是harness的全部价值吗?
03「知识是整全的吗? 」
如果我们等待一个无限上下文的人工智能,那么我们似乎在期待它能够一次吸纳人类的所有知识,并依此做出决断。
而这涉及到知识是否是整全的问题。
图书馆学最伟大的理论家阮甘纳桑(S.R. Ranganathan)在1930年代看到了树状分类法的根本缺陷:书籍很少只属于一个类别,知识的宇宙在持续膨胀并以新的方式组合旧的领域。
他提出的“面分类法”(facetedification)代表了根本不同的理路:从多个独立的维度来描述对象,让使用者在检索时自由组合。
分类不是把世界切成碎片,而是承认同一个对象可以且应当从多个不可通约的维度被同时观看。
福柯在《词与物》的序言中引用了博尔赫斯虚构的“中国百科全书”——其中动物被分为“属于皇帝的”“经过防腐处理的”“乳猪”“传说中的”“用极细的骆驼毛笔画出来的”“远看像苍蝇的”。
这个令人发笑的分类法动摇了一个不假思索的前提:分类体系需要一个共享的“操作台”,一个使并置成为可能的公共空间。
博尔赫斯撤除了这个空间本身,揭示出每一种分类体系都不是在反映世界,而是在生产一种特定的认识世界的方式。
齐泽克在《视差之见》中更进一步。他的视差概念指的是:在两个不可调和的观察视角之间,不存在更高的真相——间隙本身就是真相。
带回到技术语境中:代码文件按功能模块分类是一种秩序,按修改频率排列是另一种,按依赖关系组织是第三种,按性能热点标记是第四种。
而在这几个不同维度的观察视角之间,不存在更高的真相。
将一切知识记录到同一个语境下不会产生更高的认识,而仅仅会产生混乱,而将一切分隔开,正是harness的工作。
04「桥和目的地 」
所以,关于harness为什么重要,或许应该有一个比“上下文不够大”更好的回答。
harness中确实有一大块功能是因为上下文窗口太小才存在的——RAG切片、摘要压缩、跨会话状态搬运。这些是“桥”,是权宜之计,价值与窗口大小成反比。
以每年30倍的扩展速度来看,它们可能很快就会退休。
但harness中还有另一块功能:工具编排、外部计算调用、动态视角生成、多agent协调、权限治理。
这些不是在弥补模型的记忆不足,而是在扩展模型的感知边界和行动能力。一个拥有无限记忆的大脑仍然需要手、眼睛和行动的规范。这些是“目的地”,会随着agent变得更强大而变得更加重要。
当前行业话语的问题恰恰在于把这两部分混为一谈。
一些论述把整个harness当作永恒基石,忽视了其中大量功能正在被上下文扩展侵蚀的事实。另一些论述把整个harness当作临时桥梁,忽视了工具编排和视角生成正在变得更加核心。
图书馆里帮忙记住“这本书在第三排第七格”的索引卡片确实会被搜索引擎取代。但图书馆员根据读者此刻的研究问题,从不同学科的书架上抽取材料、组合成一个全新阅读清单的能力,不会被取代,只会更有价值。
harness中有桥,也有目的地。看清哪部分是哪部分,或许是当下最值得做的判断。