如今我们正从"一个AI助手"走向"一群AI智能体"协同工作。但随着智能体的普及,三类核心挑战同时撞上了传统基础设施的天花板。
第一个,上下文窗口越来越大。像DeepSeek这样的主流模型都在冲百万token级别的上下文,但这对算力代价是指数级的,上下文长度翻一番,开销可能翻好几番。这个关系不打破,扩展就是在烧钱。
第二个,Agent能跑的时间越来越长了,但跑得久不代表跑得对。单步看着还行,连续执行几十步下来错误一路累积,成功率断崖式下跌。跑着跑着自己忘了前面干过什么,这种"金鱼记忆"不解决,长时间运行就是空谈。
第三个,上下文越长,真正有用的信息越难捞出来。根据斯坦福和CMU的"Lost in the Middle"研究发现,相关信息放在上下文中部时,模型性能下降超过20%,甚至不如完全不给参考资料的闭卷表现。模型明明有能力但拿不到该拿的素材,巧妇难为无米之炊。
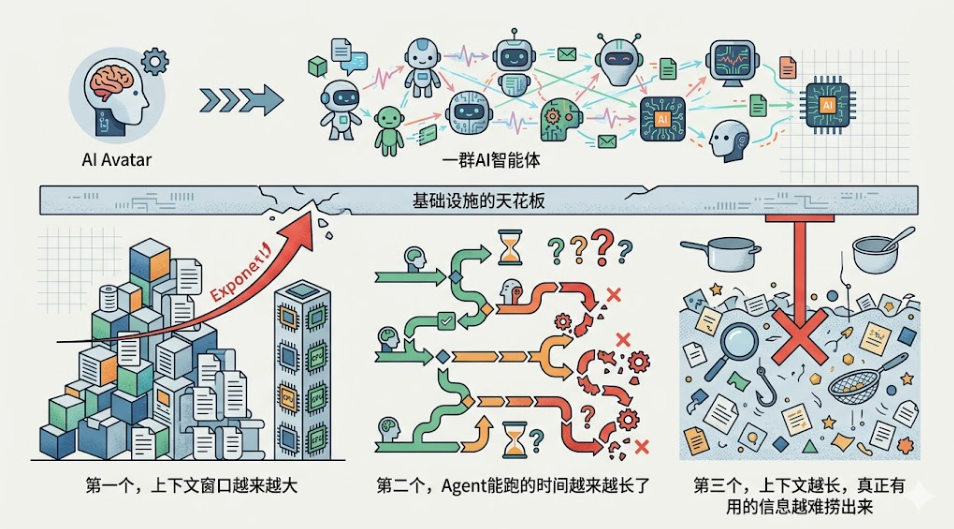
窗口上下文大小、运行时长、任务复杂度,三根曲线同时往极限顶。那个为"一问一答"设计的老架构,还能撑多久?说实话,悬。
前几天英伟达发布的最新芯片,正是通过整合CPU+GPU、共享统一存储池,完成了 PC 端的架构革新。而华为这次的打法,呼应了这种架构革新的思路,只不过这次的革新对象,是整个云与AI基础设施。
为什么要革命?
不知道你们有没有发现,当我们与模型对话时,上下文一长,模型就会答非所问,其实很多时候不是它笨,也不是算力不够,是系统跟不上——瓶颈全在内存和互联上,模型再强也得“做一步忘一步”。
这就不得不指出,传统AI基础设施架构的设计原点是面向人类业务,而 AI 智能体的自主运行、长周期状态留存的需求,倒逼我们从底层重构基础设施,让算力、存储、网络都围绕 AI 负载做优化。
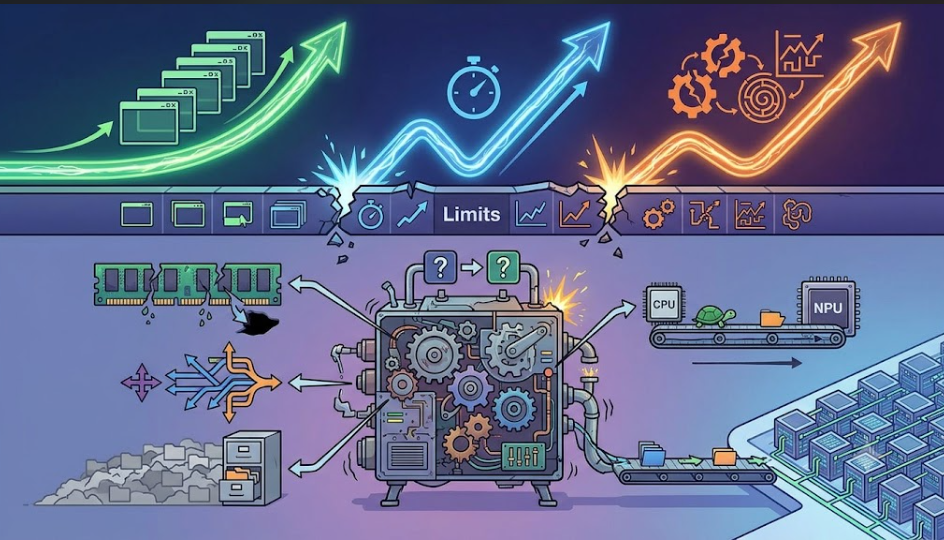
英伟达也在从"卖芯片"加速转"卖整体数据中心方案"。单点算力的军备竞赛快到头了,下一程拼的是体系能力。
根据可靠人士的透露,6月5日INSPIRE大会要提到一个叫"Agentic计算机"的新物种,要把云基础设施彻底重构。有点像冯·诺依曼当年给人类设计计算机那意思,这台是给AI智能体造的。
据说设计思路和旧云服务完全不一样:以Token而不是核/卡为基础,按每天万亿Token而不是单机规模来设计,面向AI的操作,不是给人看的控制台。
核心是灵衢超级互联网络,说白了就是一根"万能总线"。这条2019年立项的UB总线,走了一条跟PCIe主从架构、NVLink铜缆短距完全不同的路:对等互联、光通信长距、全芯片原生支持。几千节点能打通成一台逻辑计算机,延迟低到纳秒级。
基于这根"万能总线",Agentic计算机构建了四个关键能力方向。
上下文太长算不动?CPU和NPU紧耦合,通智融合把这块扛下来。记不住前面的内容?KV Cache分级缓存,命中率据测超90%,用存储换算力。任务跑到一半崩了?检查点、回滚、恢复机制拉满,把长程成功率救回来。任务太复杂一种芯片搞不定?资源池化加上异构协同,把多种芯片拧成一股力。

这些能力并非空中楼阁,此前华为云CloudMatrix384超节点已经落地了高存储利用率、异构资源协同的能力,全新的 “Agentic 计算机”架构,会在这些基础上带来更进一步的升级。
比如,AReaL联合清华在华为云上跑通了万亿参数MoE的RL后训练,万卡成本降约20%,稳定性超98%,训练环节已经验证可行。推理端小红书也跟上了,用CloudMatrix 384超节点做384路专家并行,单卡吞吐飙到2300 Tokens/s,时延压到50毫秒以内,几亿用户的推荐全靠它实时算。
6月5日,华为云INSPIRE创想者大会,"Agentic计算机"将会正式亮相。智能体时代,比的不再是单点算力,而是谁的架构能同时扛住长序列、长记忆、长程自主、复杂任务这四条曲线。华为想做的,不只是国产替代,而是给全球AI基础设施指出下一个十年的方向。