2026年,中国大模型API价格跌破“厘时代”,调用量碾压美国。
你以为赢在算法?错,真正底牌是“电”。
最近科技圈最炸的消息,莫过于国产大模型在海外市场“杀疯了”。
全球最大AI模型聚合平台OpenRouter最新数据:国产模型连续三周总调用量压制美国模型,前者7.359万亿Token,后者仅3.536万亿——国产模型占了调用量前九名里的五席。
与此同时,价格战打得全球同行头皮发麻。阿里云、DeepSeek、字节、百度、腾讯轮番降价,API价格已进入“厘时代”。中国银河证券数据显示,国内模型平均API价格仅3.88元/百万tokens,而海外模型高达20.46元/百万tokens,“国产价格仅为海外五分之一”。
很多人把功劳归于DeepSeek的MoE架构、FP8低精度训练、多头潜在注意力……这些技术创新确实牛,训练成本压到了GPT-4的1/14。
但今天我要告诉你一个更深层、更少人提及的真相:中国大模型之所以敢打价格战,是因为中国打得起一场“电力战”。

先算一笔账:大模型的钱,到底花在哪?
训练阶段,GPT-4耗时约95天,总能耗38.2吉瓦时,日均耗电约40万度——相当于4万户家庭一天的用电量。按美国工业电价0.472元/度(约6.5美分)计算,单次训练电费约1800万元人民币。如果在中国训练,工业电价0.635元/度,电费约2425万元,看似更高?别急,这只是“单价”的错觉。
真正的大头是“推理”。行业数据显示,一次典型的AI推理请求耗能0.3-3瓦时。假设一个日活千万的大模型应用,每天调用10亿次,日耗电可达300万度。一年就是10.95亿度电。
以中国工业电价计算,年电费约6.95亿元;以美国电价计算,约5.17亿元。看起来美国便宜?但请注意——美国电价波动极大,2024年得克萨斯州因极端天气电价一度飙升至人民币9元/度,而中国工业电价由国家统一定价,几乎不波动。
更重要的是,电费占大模型运营成本的比重远超硬件折旧。据券商测算,在典型推理场景中,电力成本占总运营成本的35%-50%,而GPU折旧约占20%-30%。也就是说,谁控制了电费,谁就掌握了定价权。
所以,大模型价格战的本质,不是算法战,而是“电费战”。
很多人拿中美工业电价简单对比:中国0.635元/度,美国0.472元/度,得出“美国更便宜”的结论。这是典型的“指标错位”。
而现实真相是,大模型数据中心需要的是稳定、持续、高可靠性的电力,而不是现货市场的波动电价。
中国工业电价虽然名义上高于美国,但包含了交叉补贴——居民电价低、工业电价相对高,但国家通过行政手段将大工业用户的电价长期锁定在低位,且不随燃料价格暴涨。美国则相反:工业电价看似低,但那是市场平均价,一旦遇到天然气涨价、极端天气、电网故障,现货电价可以瞬间翻5-10倍。
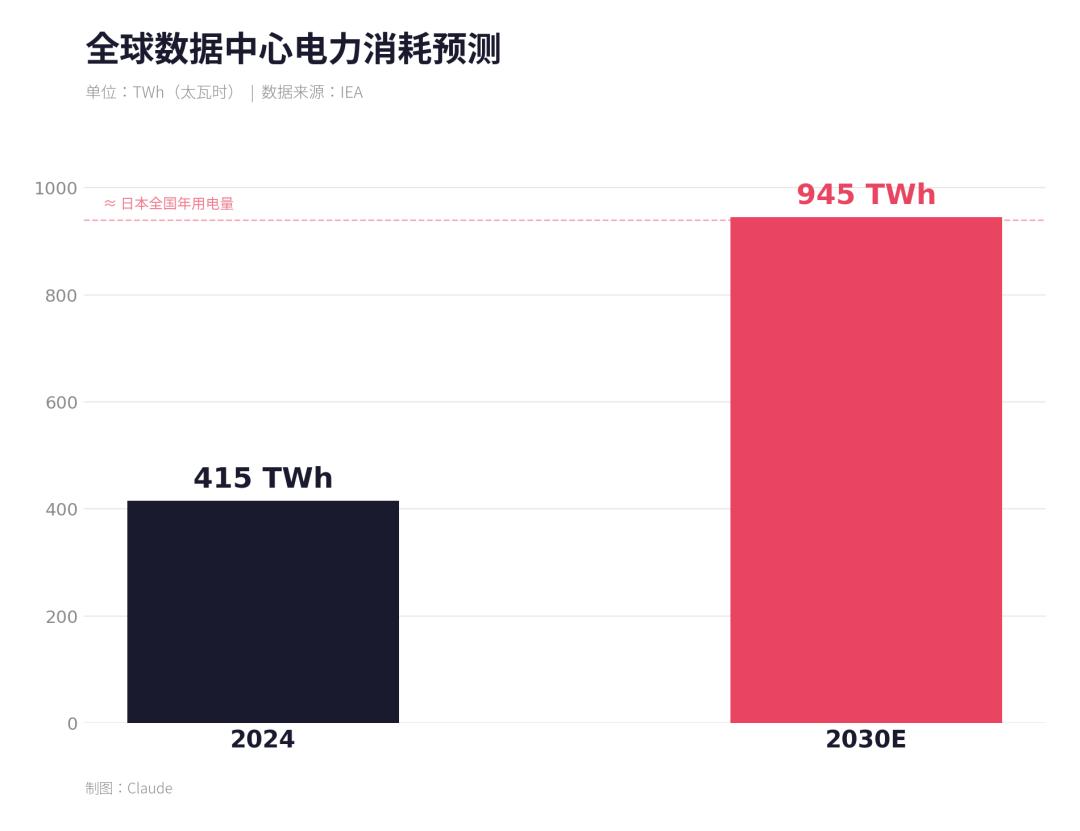
全球数据中心电力消耗预测;数据来源:IEA;制图:Claude
更关键的数据:中国的实际用电成本远低于美国。根据国家电网数据,中国工业用电和居民用电的平均电价约为OECD国家的59%,约为新兴市场国家的81%。
考虑到中国电网的供电可靠性(城市地区年停电时长低于1小时,农村低于5小时),而美国平均停电时长达662分钟(约11小时),得州、加州等地数据中心集中区域甚至高达1600分钟——停电意味着算力损失、服务中断、客户流失。把可靠性损失折算成成本,中国的综合电力成本优势至少在30%以上。
摩根士丹利在2025年的一份报告中直接指出:中国AI数据中心的度电综合成本(含可靠性、备用电源、调峰)比美国低40%-50%。这才是大模型价格战的真正“底牌”。
中国电网——为AI量身定做的“超级充电宝”如果说低电价是结果,那么全球最大、最稳、最绿的电力基础设施才是原因。
数字不会说谎:2024年中国发电量超过10万亿千瓦时,占全球三分之一。截至2025年6月,发电总装机36.5亿千瓦,其中清洁能源装机22亿千瓦(占比60%),风电、光伏装机达16.7亿千瓦。可再生能源总装机约2.2太瓦,占全球一半以上。
但光有电不够,还得送得到、送得稳。这里就不得不提中国的“特高压”王牌。
目前中国已投运45条特高压线路,“西电东送”能力达3.4亿千瓦。特高压可以将西部清洁能源以低于0.2元/度的成本输送到东部数据中心,损耗仅5%左右。而美国没有特高压,跨州输电损耗高达10%-15%,且受制于各州不同的电网标准和利益博弈。
更关键的是,中国将 “东数西算”与“西电东送”深度融合。西部可再生能源丰富、电价极低(部分地区风电、光伏度电成本已降至0.15元以下),东部数据需求旺盛。通过算力调度,将非实时性算力任务迁移到西部数据中心,充分利用低价绿电。目前,“东数西算”的规模化效应已为全国提供约八成的智算算力。
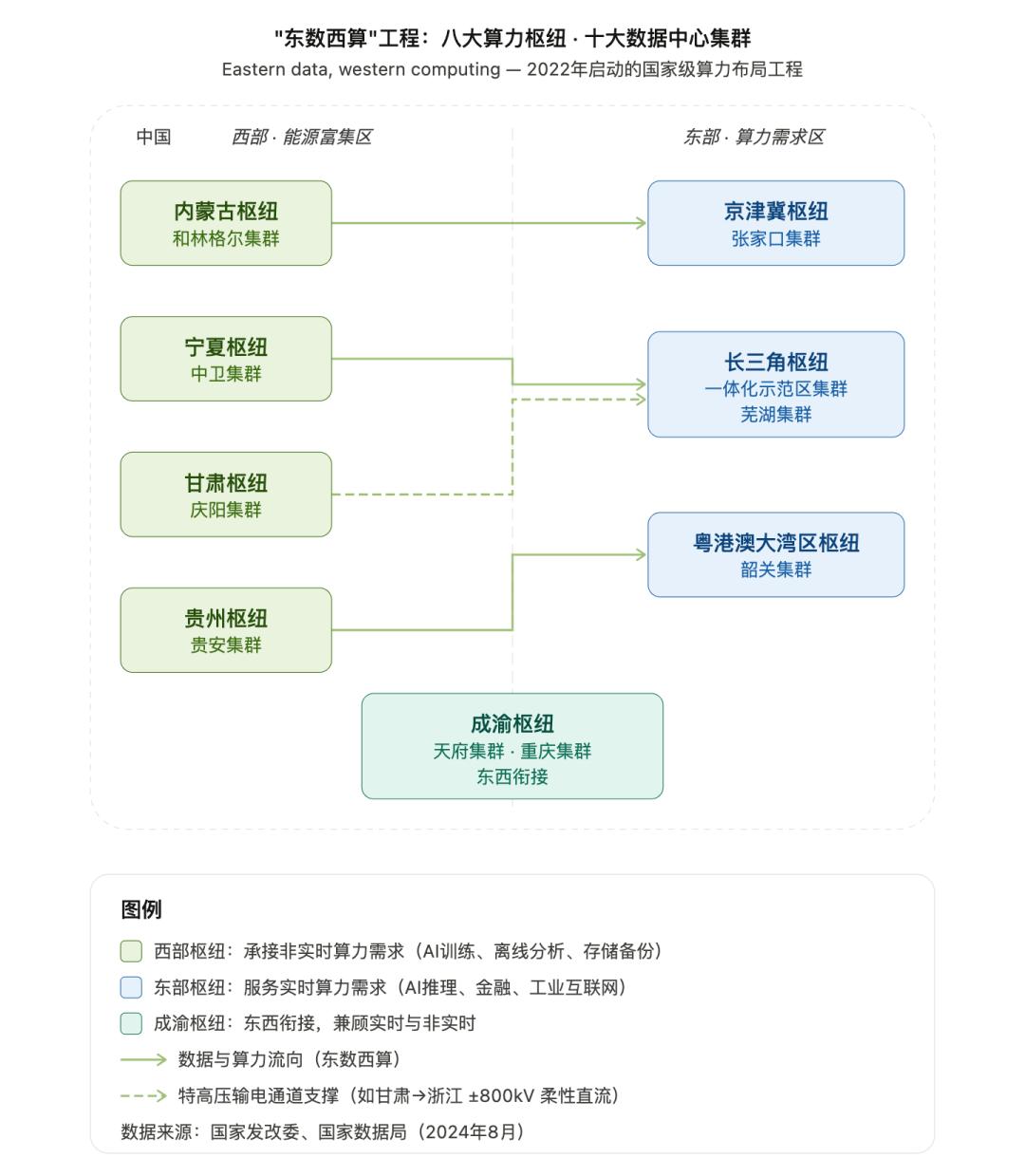
“东数西算”工程;制图:Claude
还有一个杀手锏——储能。中国已建成全球最大的新型储能体系,2025年储能装机超80吉瓦,可有效平抑风电、光伏的波动性,为数据中心提供24小时稳定绿电。而美国的储能装机不足中国的三分之一。
总体而言,中国用国家战略级的能源基建,为AI大模型打造了一个“发电-输电-储能-配电”一体化、低成本、高可靠的电力底座,这在全球是独一无二的。
美国困局——手握GPU,却卡在“电”上再看大洋彼岸,情况相当尴尬。
高盛2026年1月发布的《AI能源困境》报告直言:电力已成为美国AI发展的最大瓶颈。美国数据中心用电量已占总用电量约6%,到2030年将翻倍至11%,而美国电网老化、升级缓慢,70%的变压器超过25年设计寿命,输电线平均服役40年。
微软CEO纳德拉抱怨:“我们手上有成堆的GPU,却因为缺电、缺空间,只能闲置。”弗吉尼亚州和得克萨斯州的数据中心集中区域,停电时长分别高达962分钟和1614分钟。2025年,OpenAI甚至因为一次区域停电导致训练中断48小时,损失数百万美元。
更致命的是,美国无法快速新建电网。一条跨州输电线路从审批到建成平均需要10-15年,而中国建一条特高压只需3-5年。这意味着,即使美国想复制中国的“西电东送”,也至少需要十年时间。
黄仁勋在此前的访谈中更是直言:“中国的电力简直就是免费的。”虽然夸张,但他点出了一个事实:在AI竞赛中,电力基础设施的代差,比芯片代差更难弥补。
技术创新+能源协同,中国模式的“双轮驱动”当然,光有电不会自动产生大模型。中国价格战的胜利是“技术创新降低单次计算能耗”与“能源优势降低每度电成本”的双重红利。
先说技术。DeepSeek的MoE将每次推理激活的参数从671B压缩到37B,计算量减少95%。多头潜在注意力(MLA)将KV缓存从传统方法的每token 500KB降至70KB。FP8低精度训练将内存和计算量减半。这些技术让每度电产出的有效算力提升了10倍以上。
再看能源协同。中国正在推进 “算电协同”——AI调度算法可以根据实时电价和电网负荷,动态将计算任务在东部和西部数据中心之间迁移。当西部风电大发、电价低至0.1元/度时,将大量离线推理任务调度过去;当东部电网负荷高峰、电价上升时,暂停非紧急任务。这种“算力随电走”的模式,使平均用电成本再降低20%-30%。
2025年,国家发改委、能源局联合发布《关于推进“人工智能+”能源高质量发展的实施意见》,明确提出构建“算力与电力协同发展”体系,这是国家级政策对大模型电力底座的直接背书。
反观美国,各州电力市场割裂、实时电价剧烈波动,AI公司只能被动承受高电价,无法通过算力调度来套利。这就是制度优势转化为成本优势的典型案例。
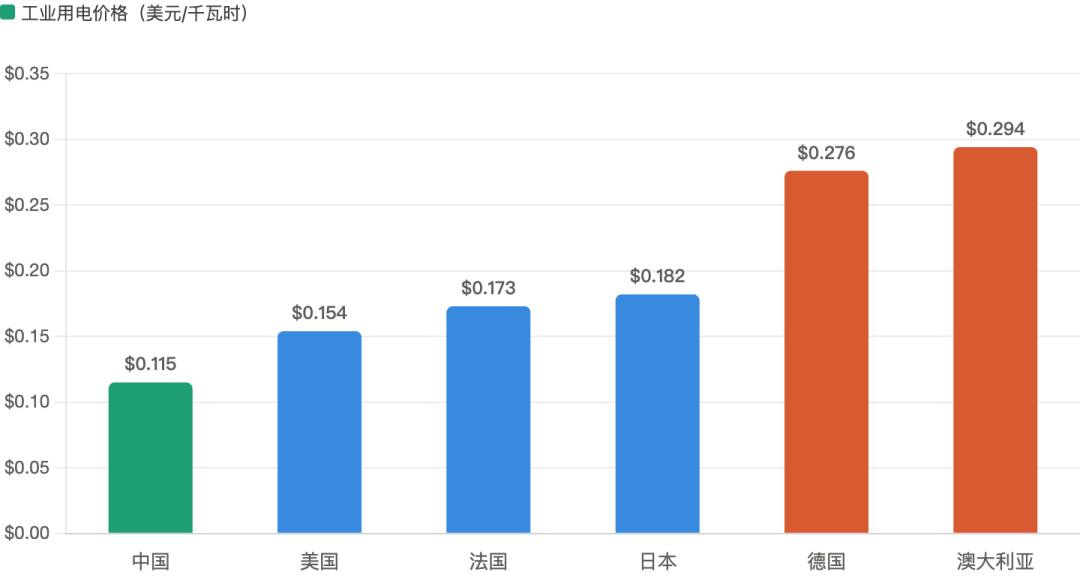
2025年第三季度工业电价横向对比;数据来源:GlobalPetrolPrices
价格战只是开始,下一场是“电力战”2026年,中国大模型价格战仍在继续,但竞争焦点已从单纯的价格转向模型能力和生态。然而,无论表面如何变化,底层逻辑不变:算力的终极竞争,是电力的竞争。
高盛预测,到2030年中国有效备用发电能力将达到400吉瓦级别,是全球数据中心预计用电需求的三倍以上。这意味着,当全球其他国家还在为AI数据中心“抢电”时,中国已经提前二十年做好了能源战略储备。
更有远见的布局是“核聚变与下一代核电”。中国正在建设全球首座钍基熔盐堆商用机组,预计2030年前后并网发电,将为AI数据中心提供几乎无限、零碳、低成本的基荷电力。而美国在这方面的进展至少落后5-8年。
结论很清晰:中国大模型的价格战,不是短期的烧钱补贴,而是几十年能源战略的“溢出效应”。从上世纪90年代布局特高压,到“十四五”建成全球最大清洁能源体系,再到“东数西算”和“算电协同”——这些看似与AI无关的超级工程,如今正成为大模型竞赛中最难以复制的国家级竞争力。
当全球科技巨头还在为H100、B200芯片抢破头时,中国已经悄悄打赢了AI时代最关键的一场战争——电力争夺战。
而这,才是中国大模型价格战的真正秘密。