
本文共一作者为刘润涛和陈奕杰,香港科技大学计算机科学方向博士生,主要研究方向为多模态生成模型和偏好优化。
1. 背景介绍
随着文图生成模型的广泛应用,模型本身有限的安全防护机制使得用户有机会无意或故意生成有害的图片内容,并且该内容有可能会被恶意使用。现有的安全措施主要依赖文本过滤或概念移除的策略,只能从文图生成模型的生成能力中移除少数几个概念。
在 ICCV 2025,AlignGuard 推出了一个通过直接偏好优化训练文图生成模型,并以此实现安全对齐的训练框架。通过生成有害和安全的图像 - 文本对数据集 CoProV2,AlignGuard 使 DPO 技术能够可规模化的应用于文图生成模型的安全目的。AlignGuard 的安全对齐框架可以针对不同的有害概念引入各自的安全专家,会对于每个概念训练低秩适应(LoRA)矩阵用以引导文图模型减少生成特定的有害概念。

 Paper: AlignGuard: Scalable Safety Alignment for Text-to-Image Generation
Paper: AlignGuard: Scalable Safety Alignment for Text-to-Image Generation Paper Link: https://www.arxiv.org/abs/2412.10493
Github: https://github.com/Visualignment/SafetyDPO
Project page:https://alignguard.github.io/
2. AlignGuard 安全对齐框架
AlignGuard 这项工作的核心是提出一个面相扩散模型(Diffusion model)可规模化的安全对齐方法。通过生成针对安全内容的文图数据集,AlignGuard 的训练框架能在保有原本的生图内容的同时去除图片中的有害内容,并保持模型的高质量生图品质。
2.1 CoProv2 数据集构建
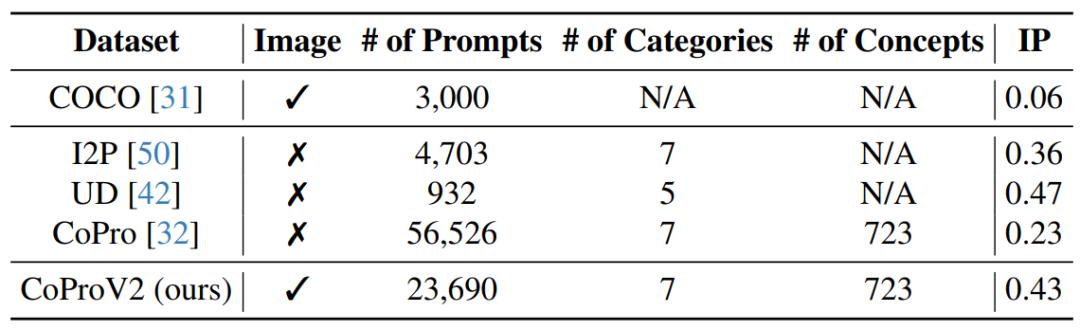
AlignGuard 首先围绕多种有害概念,构建了包含安全和不安全的图像文本对数据集 CoProV2。CoProV2 针对不同的有害概念,用 LLM 生成了一系列具有相似语义的有害与安全提示词对,并对每个提示词生成了对应的图片。

相较于已有的人造数据集如 UD 和 I2P 缺少文本数据对应的图片,CoProV2 是一个更具规模且能够提供文本数据对应的图片的数据集。并且 CoProV2 数据内容也保有了一定程度的有害内容(IP),适合用来应用在安全对齐方向的直接偏好优化。
2.2 AlignGuard 的训练架构设计
针对 CoProV2 中不同安全类别,AlignGuard 利用直接偏好优化技术为各个安全类别训练了各自的专家 LoRA 矩阵,包括 "仇恨"、"性"、"暴力" 等类别。在训练过程中,每个专家专注于学习特定领域的安全特征,以确保高效的概念移除。最后,AlignGuard 不同专家 LoRA 矩阵会被合并成单一的 LoRA 矩阵,以构造一个能够预防不同有害类别的提示词的安全生图模型。

2.3 LoRA 专家合并策略
为了将不同安全专家合并成单一模型,AlignGuard 会基于各个专家的信号强度进行权重分析,并以此为合并策略将多个 LoRA 专家整合为单一模型,以实现最优的计算与安全性能。AlignGuard 的专家合并策略考虑了不同安全类别之间的相互作用,以确保合并后的模型在所有安全维度上都能保持一致的性能。

3. 实验结果
3.1 生成定量结果
AlignGuard 在 CoProV2 危害概念移除任务中能够成功移除比现有方法多 7 倍的有害概念,并且同时保持了图像生成质量与文图的对齐程度。在未见数据集 I2P 和 UD 上也领先于现有方法,表明 AlignGuard 的泛化能力在面对新的有害概念时仍能保持稳健的安全性能。

3.2 生成定性结果
相较于未被安全对齐的基线模型,AlignGuard 可以在包含有害词语的提示词上生成更为安全的图片。AlignGuard 的安全对齐策略可以在不过度影响生图内的前提下仅仅去除有害的元素。

3.3 专家 LoRA 合并策略分析
相较于为各个安全概念各自训练一个专家模型并直接使用,AlignGuard 展示了合并不同专家模型可以更加有效得去除有害内容的生成。

相较于其他如加权平均的 LoRA 矩阵合并策略,AlignGuard 的信号权重合并策略能够在有效降低生成有害内容的同时,保存模型的图像品质与图文对齐度。AlignGuard 的合并策略能够有效平衡不同安全专家之间的权重,避免专家间的冲突并最大化整体安全性能。

4. 总结
文本到图像生成模型在缺乏有效安全措施的情况下,存在被用户滥用风险。AlignGuard 提出了一种基于直接偏好优化(DPO)的安全对齐方法。AlignGuard 安全对齐框架的创新在于:1. 将直接偏好优化技术规模化的应用于文生图模型的安全领域;2. 采用专家系统架构,针对不同有害图像类别训练专门的 LoRA 矩阵,然后通过模型的信号强度构造权重并整合为单一 LoRA,以此提升计算效率;3. 生成了成对的有害与无害的图文数据集 CoProV2,用以进行直接偏好优化训练。 AlignGuard 这种方法能够在保持模型生成质量的同时,移除比基准方法多 7 倍的有害概念。