作者:阿里云数据库
审校:陈姚戈
2026年3月,在全球人工智能与GPU计算领域最具影响力的技术盛会——NVIDIA GTC 2026大会上,阿里云资深技术总监张为受邀发表演讲,带来了《基于全局KV Cache存储系统的高效LLM推理加速方案》的深度分享。
这不是一次普通的技术发言。NVIDIA GTC大会汇聚了全球顶尖的AI科学家、工程师与产业领袖,每一个受邀Session都经过严苛筛选。这次入选,不仅是对阿里云Tair在AI推理基础设施领域多年积累的高度认可,更标志着中国云计算厂商在全球AI底层技术话语权上迈出了关键一步。
在AI从"模型能力竞争"转向"工程效率竞争"的今天,KV Cache管理正成为大模型推理链路中最关键的性能瓶颈之一。GPU显存贵、上下文长、并发高——这三重压力叠加之下,如何用存储的智慧释放算力的潜能,是整个行业都在苦寻的答案。
阿里云数据库Tair给出了自己的回答:从分层调度、全局池化、混合模型适配,到与SGLang社区深度共建、联合NVIDIA Dynamo AIConfigurator团队开发高保真仿真器,再到面向未来硬件的G3.5定制存储探索——一套覆盖全链路的系统性解法,正在重新定义AI时代的存储基础设施。
本文是对张为GTC演讲的深度复盘与延伸解读,带你从原理到架构、从挑战到未来,完整理解这场正在发生的存算协同革命。
当前,AI的应用正经历从“单一模型交互”向“自主智能体(Agent)集群协作”的关键范式转移。随着OpenClaw等新一代框架的爆发,应用侧对长上下文、多轮记忆及复杂任务规划的需求呈指数级增长,基础设施面临前所未有的挑战。在此背景下,阿里云资深技术总监张为在GTC 2026 Session 中介绍《基于全局KV Cache存储系统的高效LLM推理加速方案》(点击查看视频回放、点击下载PDF),这一分享不仅引发了业界的广泛讨论与共鸣,更标志着存储层在AI推理链路中的战略地位从“辅助支撑”向“核心驱动”转变,确立了存算协同作为突破算力瓶颈的关键路径。本文将以此次分享为核心线索,从KVCache的技术原理、架构演进、工程挑战到未来硬件趋势,为大家带来一次系统性的深度复盘与解析,旨在为构建高效、经济的AI推理基础设施提供实践参考。
KVCache作用和应用发展趋势
KV Cache是大语言模型推理的核心优化技术,其本质是"以内存换算力"。在Prefill阶段缓存Key/Value状态,Decode阶段直接复用历史缓存,避免重复计算,将冗余的矩阵运算转化为高效内存读取,显著降低延迟与推理成本。
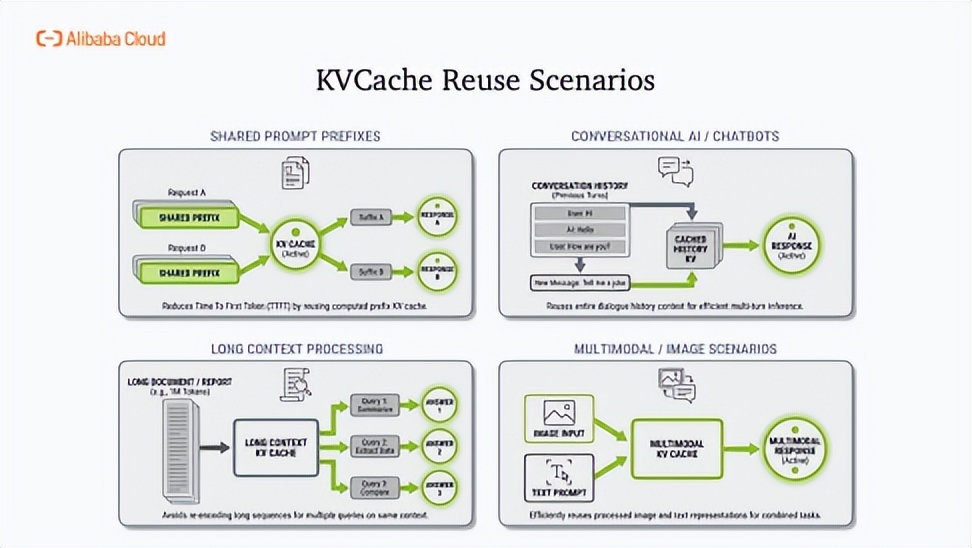
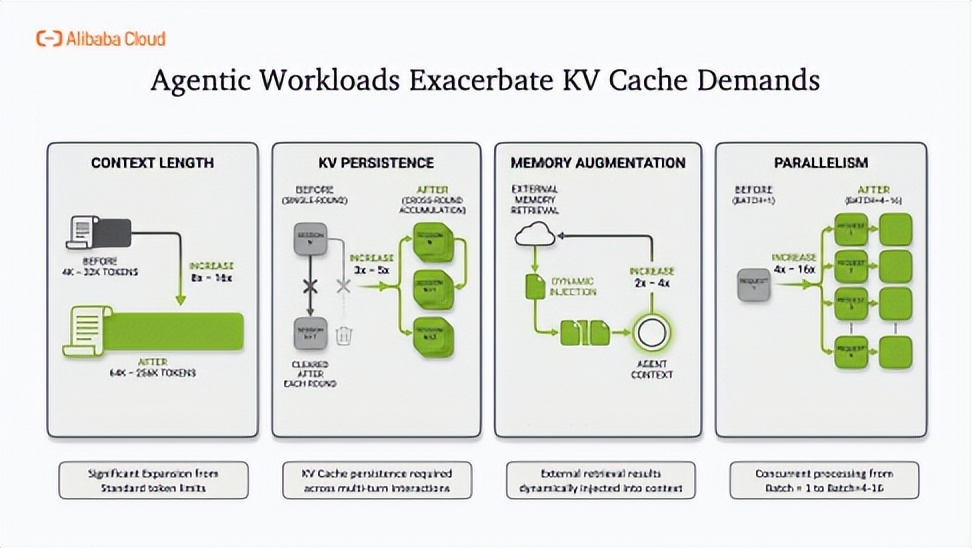
当前,KV Cache已广泛应用于系统提示词复用、多轮对话记忆、长文档检索及多模态处理等场景,成为提升生产效能的关键。随着自主智能体时代到来,其需求呈指数级增长:上下文长度从4K扩展至256K tokens、跨轮次缓存持久化、RAG动态注入外部知识、高并发批处理,四大维度叠加使内存压力激增8-16倍。
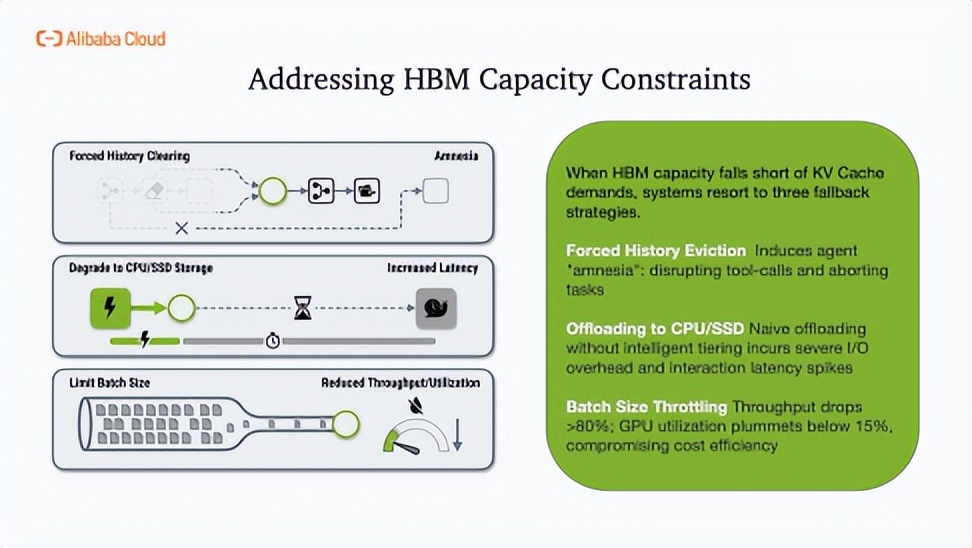
然而,GPU高带宽内存容量已成为物理瓶颈。传统方案如强制清除历史、卸载至CPU或降低批量,均会损害可靠性或实时性。
基于与主流模型厂商的深度研讨,针对OpenClaw类Agent应用及未来多模态1M长上下文场景,行业共识已指向构建智能分层、业务感知的KV Cache管理体系,这将是突破“内存墙”、释放智能体潜力的核心方向。
具体演进路径包含三个层面:
1. 存储智能分层: 建立类似操作系统虚拟内存的多级架构,热数据驻留GPU HBM,温数据卸载至Host DRAM,冷数据持久化至远端高性能存储,实现容量与成本的平衡。
2. 业务感知调度: 淘汰策略从简单的LRU(最近最少使用)升级为基于任务类别的冷热数据区分。
3. 存算分离与池化: 推动KV Cache存储与计算算力解耦,通过全局资源池化打破单卡显存限制,为“无限上下文”提供底层支撑。
我们(阿里云数据库Tair KVCache)在做什么?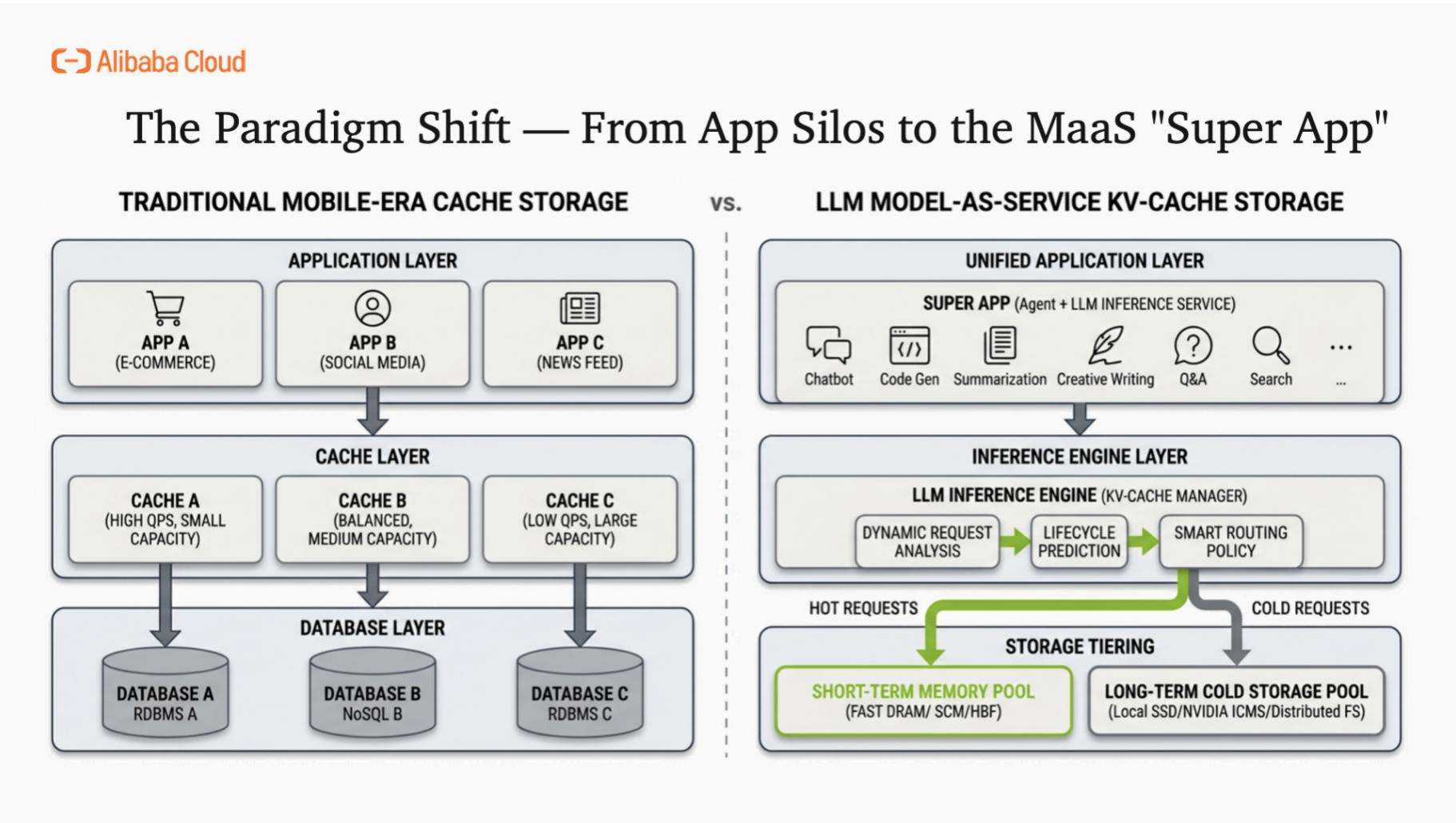
我们看到范式转移:当前正从"移动时代"的孤立应用架构(每应用独立数据库),迈向"模型即服务"的超级应用时代。用户通过统一入口与智能体交互,由底层LLM推理服务并发处理代码生成、对话、分析等多元任务,实现能力融合与资源集约。
在这一变革中,数据访问模式发生了根本性变化。传统的Transactional Load(交易型负载)正演变为Inference Load(推理型负载)。阿里云数据库Tair KVCache正顺势而为,实现从互联网时代面向高并发交易,到AI时代面向高吞吐推理的战略延展,成为连接算力与模型的关键存储枢纽。
传统缓存经验在AI时代的复用尽管负载类型变了,但存储系统的核心设计哲学在AI推理中依然成立。Tair将互联网时代成熟的缓存架构经验,平滑迁移至AI基础设施中:
1. 接口标准化: 正如互联网应用依赖Redis协议,AI推理引擎同样需要一个标准的KV抽象层。Tair提供的高兼容KV接口,使得推理框架无需关心底层是DRAM还是SSD,实现计算存储解耦。
2. 存储层级化: 传统架构中,本地缓存解决延迟,远端缓存解决容量。在AI中,GPU HBM极其昂贵且有限,必须将不活跃的KVCache快速卸载(Offload)到Host DRAM或远端Tair存储中,实现“无限显存”。
3. 计算下推与预取: 传统缓存通过预计算加速查询;AI缓存则通过预取(Prefetching)和前缀复用(Prefix Reuse),避免重复计算相同的Token序列,直接利用存储能力加速推理效果。
应对推理上KVCache的新挑战回顾过去一年的技术演进,阿里云数据库Tair 深度融入开源生态,与合作伙伴共同补齐了KVCache解决方案的关键拼图。针对推理链路中的核心痛点,我们从分层调度、模型支持、存储优化、全局管理,经济效应及算法创新六个维度进行了系统性优化。
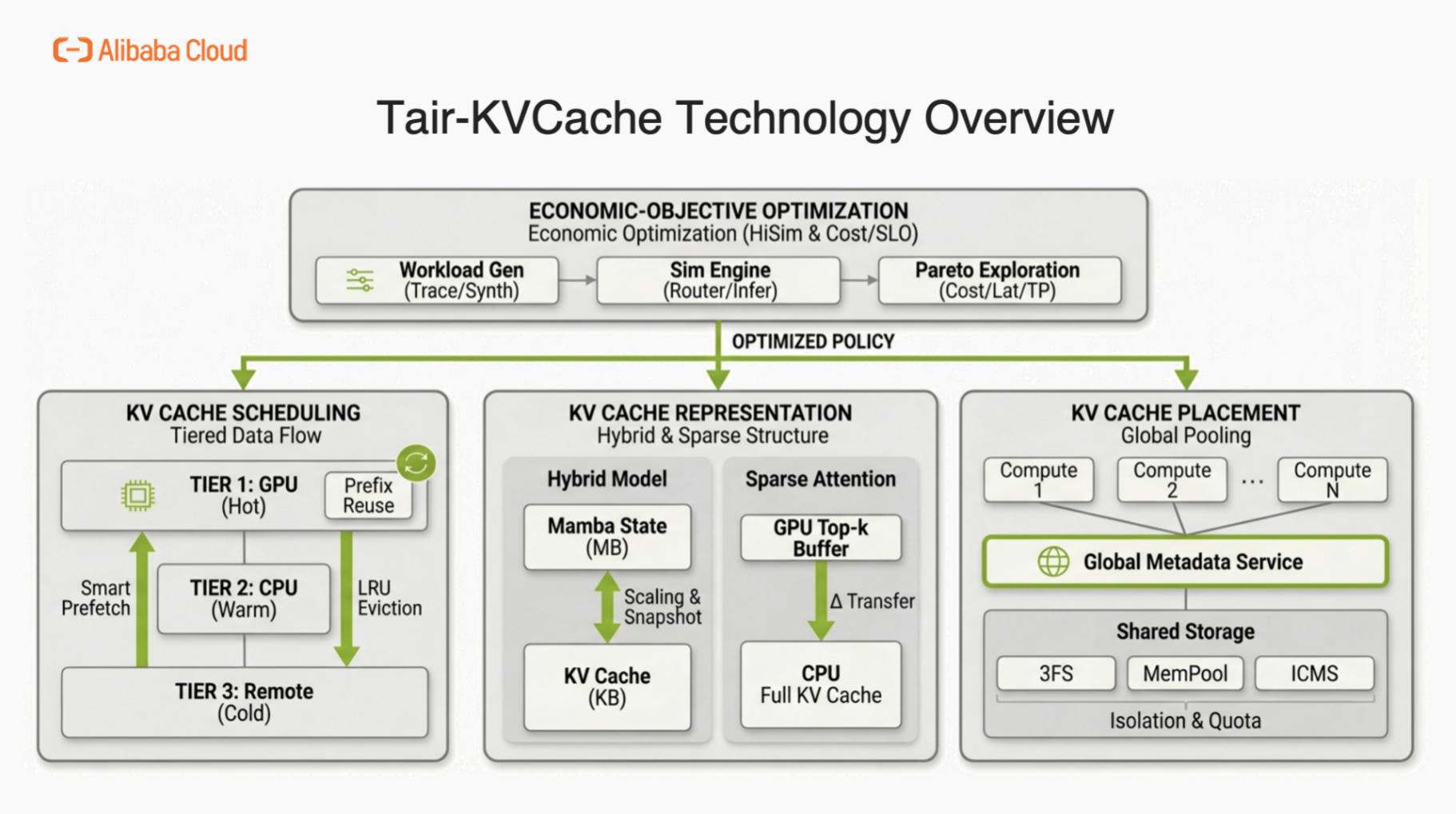
1. 推理引擎调度与分层缓存(Scheduling & HiCache)针对推理引擎(如vLLM、SGLang)与存储间缺乏统一标准的问题,我们与SGLang社区合作推出了HiCache分层缓存体系。该方案通过显存-内存-3FS多级卸载与全局共享,解决了存储绑定严重、难以实施多级缓存和智能预取的痛点。缓存命中率提升至80%,TTFT降低56%,推理QPS翻倍,支撑智能体时代的大模型高效推理。具体的工作可以参考阿里云Tair联手SGLang共建HiCache,构建面向“智能体式推理”的缓存新范式
2. 混合模型架构适配(Hybrid Model Support)随着模型实现从Full Attention快速迭代至Linear Attention(如QWen、Kimi)及Sparse Attention(如DeepSeek、GLM),我们及时优化了KVCache的管理方式。在SGLang社区中,我们负责实现了对Mamba-Transformer等混合架构模型的远端KVCache支持及表示层兼容。确保新一代高效模型也能享受存算分离带来的容量红利,无需因架构差异而牺牲缓存性能。具体的工作可以参考Hybrid Model Support:阿里云Tair联合SGLang对Mamba-Transformer等混合架构模型的支持方案 、SGLang Hierarchical Sparse Attention技术深度解析
3. 元数据管理与全局池化(KVCache Manager)针对Agent长会话、高并发导致的调度与命中率冲突,我们建设Tair KVCache Manager。基于高性能网络实现KVCache全局池化,引入LLM语义层 抽象管理元数据,向上暴露原生接口,向下高效调度存储,兼顾落地速度与长期演进。实现存算彻底解耦,支持推理容器弹性伸缩而不影响缓存命中率;提供ROI评估、可观测性及高可用等企业级能力,显著降低GPU消耗并提升服务质量。具体的工作可以参考我们和集团RTP-LLM开源共建的 阿里云Tair KVCache Manager:企业级全局KVCache管理服务的架构设计与实现
4. 高性能远端存储落地针对KVCache对带宽与容量的双重需求,我们和服务器团队以3FS为基座,通过RDMA全链路加速、GDR零拷贝、小I/O调优及云原生Operator等系统性升级,打造专为LLM推理优化的L3存储层,并与SGLang/vLLM深度集成。实现20GB/s+单节点带宽与PB级弹性容量,长上下文场景TTFT下降78%、推理吞吐提升520%,在保障低延迟的同时显著降低单位存储成本。具体的工作参考: 阿里云Tair基于3FS工程化落地KVCache:企业级部署、高可用运维与性能调优实践
5. 经济效应模拟与ROI评估(Simulation & ROI)面对MaaS时代负载波动大、配置空间爆炸的"黑盒"挑战,我们和NVIDIA Dynamo团队联合推出Tair-KVCache-HiSim高保真仿真器。采用分层解耦+事件驱动架构,支持端到端推理流程建模与细粒度时延预测,实现配置空间的帕累托最优搜索。仿真成本降低39万倍、端到端误差<5%,帮助客户从"经验规划"转向"数据驱动",在满足SLO约束下快速定位成本-延迟-吞吐的最优平衡点。具体的工作参考: 阿里云Tair KVCache仿真分析:高精度的计算和缓存模拟设计与实现
6. 算法优化与多模态支持(Algorithm)针对多模态输入重复场景,我们与通义实验室联合推出VLCache缓存复用框架。首次形式化识别"累积复用误差效应",提出层感知动态重计算策略,协同复用KV Cache与Encoder Cache,仅需计算2–5% tokens即可实现准确率持平。TTFT加速1.2–16倍,显著降低多模态场景显存占用与计算成本;基于SGLang的工程实现,支持实际部署中的高效推理。同时KVCache量化,压缩,稀疏化的工作正在积极和各大高校和实验室合作,相关的学术研究工作正在投递中。 具体的工作参考:VLCACHE: Computing 2% Vision Tokens and Reusing 98% for Vision–Language Inference
此前,业界KVCache方案往往局限于单一环节(如仅优化引擎或仅做存储),缺乏统一标准、全局管理及效果评估手段,导致落地困难、成本不可控。Tair KVCache通过上述六大模块,首次实现了从引擎调度、存储底座、元数据管理、仿真评估到算法优化的全链路覆盖。这不仅补齐了行业在标准化、可观测性及经济性评估上的缺失环节,我们还联合清华、火山、腾讯、华为等业内伙伴,共同推动KVCache服务化标准的制定,为Agent时代的大模型推理提供了坚实、完整的基础设施底座。
AI Memory对于未来存储的演进需求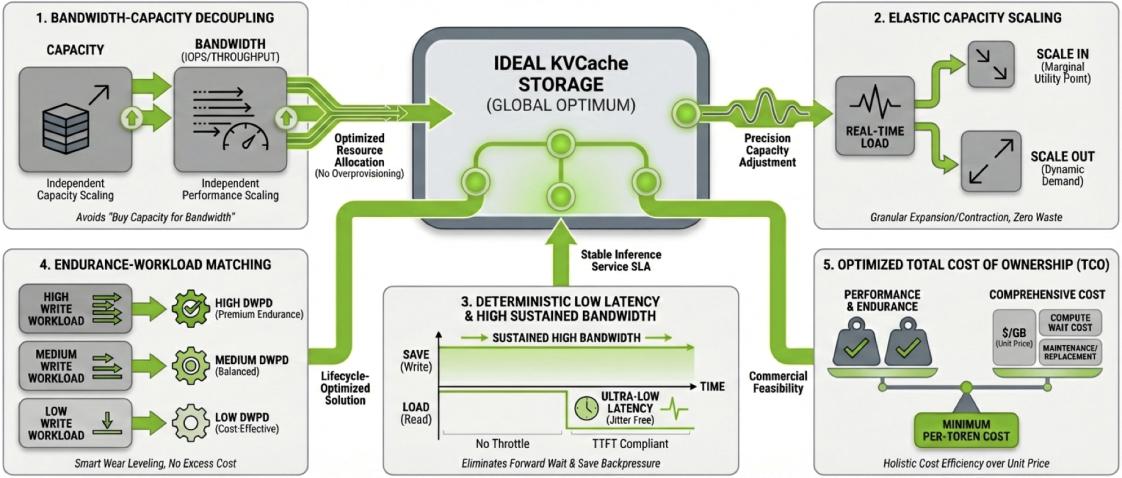
 理想KV Cache存储的5大支柱
理想KV Cache存储的5大支柱● 带宽-容量解耦。核心诉求是TB级存储容量与IOPS性能能够独立扩展,解决的问题是不再为了达到带宽目标而"被迫购买额外容量",降低资源浪费。
● 弹性容量。核心诉求是支持平滑扩容、按需付费,解决的问题是避免资源闲置带来的成本浪费,提升资源利用效率。
● 可预测低延迟。核心诉求是严格满足TTFT(首token时间)的SLA要求,解决的问题是保障每个请求的用户体验一致性,避免长尾延迟影响服务质量。
● 负载-存储匹配。核心诉求是根据不同工作负载的访问模式,匹配最适合的存储介质类型,解决的问题是延长SSD使用寿命,同时优化整体成本结构。
● 最优总拥有成本(TCO)。核心诉是在综合考虑硬件采购、运维管理、能源消耗等所有成本因素后,实现整体成本最优,这是技术方案商业可持续的关键。
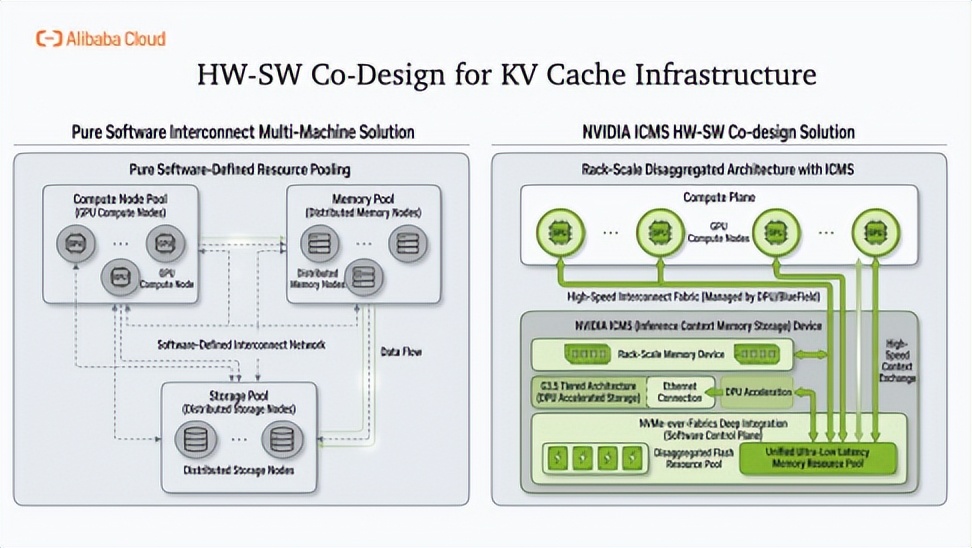
软硬结合KV Cache定制的G3.5存储与传统通用存储方案相比,G3.5方案有四个核心差异:第一定位上专为KV Cache优化,而非通用数据存储;第二接入方式采用网络附加+智能预取,而非简单的本地或网络挂载;成本效率上实现容量与带宽独立扩展,按需付费,避免资源浪费。
ICMS核心能力包括三点:上下文智能放置(决定哪个KV数据块存放在哪个位置)、硬件级加密(保障数据安全的同时不拖累性能)、块级追踪(精准预取数据,减少冗余传输)。性能指标达到800Gbps线速处理。关键价值在于绕过CPU,实现GPU与Flash存储之间的直连,大幅降低延迟。
Tair-KVCache负责全局调度决策。NVMe-over-Fabrics深度集成两者协同的效果是让远程闪存在应用层面"看起来像本地内存",对上层透明。此时我们在积极和NVIDIA以及云存储团队探索定制KVCache存储的后续发展。
硬件突破展望我们和服务器团队在积极探索下一代KVCache存储介质的选型和发展。
● HBF(High Bandwidth Flash)高带宽闪存 将HBM(高带宽内存)采用的3D堆叠技术直接应用于标准NAND闪存芯片。性能飞跃:单栈可实现1.6TB/s的读取带宽,相当于当前顶级SSD性能的50倍。应用想象:百万token级别的KV Cache可以直接"贴近"GPU部署,获得接近HBM的访问速度、闪存的大容量优势,同时不产生额外功耗负担。
● PIM(Processing-in-Memory)存内计算。 在存储芯片内部嵌入轻量级计算单元,实现"计算向数据移动"。范式转变:传统模式是把原始tensor数据从存储搬到GPU进行计算,容易遇到网络带宽瓶颈;新模式是在存储端直接完成attention分数等关键计算,只将最终的小结果通过网络传输。核心价值:大幅减少数据搬运量,从根源上突破"内存墙"限制。
● CXL 4.0 + PCIe 7.0:互联协议革命 带宽相比CXL 3.0翻倍;新增"Bundled Ports"技术,支持多链路聚合;跨机架内存池带宽可达1.5TB/s。架构意义:让"内存"真正成为可池化、可共享的资源,打破单机内存容量限制,为大规模模型推理提供弹性内存支持。