哈喽,你好啊,我是雷工!
MES和SCADA的数据库设计是项目成败的关键,
核心环节包括需求分析、概念模型、逻辑模型、物理模型、性能优化和安全设计。
数据库的设计是建立在需求分析完成,功能模块设计之后的事情。
这里让人工智能整理了一份超详细的步骤指南,从表结构到索引策略都涵盖了。
 01 需求分析
01 需求分析1.1 业务需求梳理
①MES侧:生产工单管理,物料追溯、设备状态监控、质量检验数据、绩效分析(OEE/良率)。
②SCADA侧:实时设备数据采集(真空度、温度、电流、转速、设备状态)、报警记录、控制指令日志、历史数据存储(可选择周期存储、变化存储)。
③协同需求:MES需获取SCADA的实时加工数据(如设备的温度、转速),SCADA需接收MES下发的任务数据及工艺配方等。
1.2 技术指标明确
①数据量预估:SCADA每秒采集20000个点位数据;MES每分钟处理50条工单记录;
②响应要求:SCADA报警延迟<3秒,MES报表查询<5秒。
③保留策略:SCADA的时序历史记录需存1年以上,业务数据存6个月;MES业务数据存5年。
 02 概念模型设计
02 概念模型设计2.1 核心实体识别
①MES实体:工单(WorkOrder)、工序(Operation)、物料批次(MaterialLot)、质检记录(Inspection)。
②SCADA实体:设备(Device)、传感器(Sensor)、报警事件(Alarm)、实时数据点(Tag)。
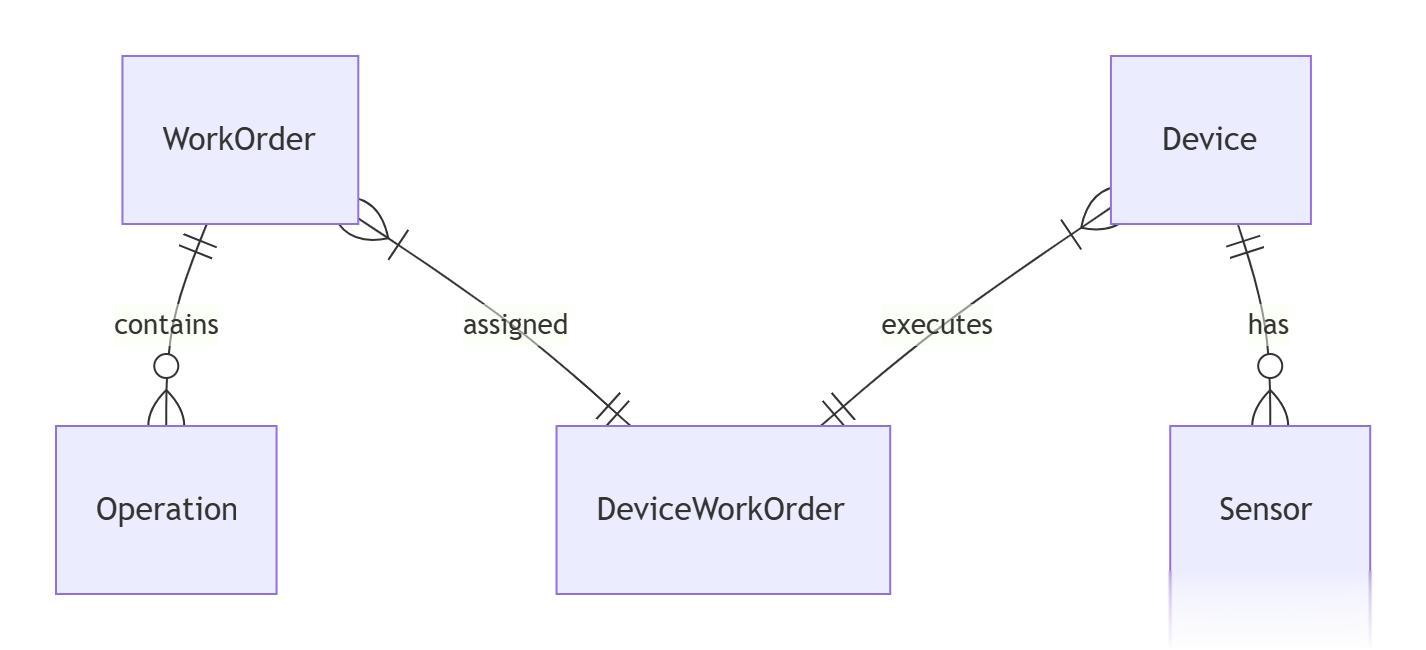
③关联实体:设备工单映射表(DeviceWorkOrder),用于绑定SCADA设备与MES任务。
2.2 关键关系定义
①一对多:一个工单对应多道生产工序,一台设备对应多个传感器(采集项)。
②多对多:物料批次与质检记录通过中间表关联。
示例:设备-工单关联
 03 逻辑模型设计
03 逻辑模型设计3.1 表结构设计
①MES核心表
CREATE TABLE WorkOrder ( order_id VARCHAR(20) PRIMARY KEY, product_code VARCHAR(10), planned_start DATETIME, status ENUM('Pending','Running','Completed') );②SCADA核心表
CREATE TABLE TagValue ( tag_id VARCHAR(30) PRIMARY KEY, device_id VARCHAR(20), value FLOAT, timestamp TIMESTAMP(3), -- 精确到毫秒 FOREIGN KEY (device_id) REFERENCES Device(device_id) );3.2 协同表设计
工单-设备映射表
CREATE TABLE DeviceWorkOrder ( mapping_id INT AUTO_INCREMENT PRIMARY KEY, device_id VARCHAR(20), order_id VARCHAR(20), start_time TIMESTAMP, FOREIGN KEY (device_id) REFERENCES Device(device_id), FOREIGN KEY (order_id) REFERENCES WorkOrder(order_id) ); 04 物理模型设计
04 物理模型设计4.1 存储优化
①SCADA高频数据:
1>按时间分区:每月一个分区表(如tag_value_202511)。
2>列式存储:Apache Parque格式(查询效率比CSV高10倍)。
②MES与SCADA业务数据
索引优化:对Work Order.status和MaterialLot.bath_id建B+树索引。
4.2 数据库选型
①SCADA:用KingSCADA实施的SCADA项目比较多,时序数据库可以采用工业库KingHistorian,支持高吞吐写入。关系型数据库可以选择MySQL,不过像军工等一些项目由于国产化不允许使用MySQL,可以使用达梦DM数据库。
②MES:关系型数据库(MySQL/达梦DM),保持事务一致性。
 05 后记
05 后记其实以上是AI人工智能给出的答案,太过简洁,但是可以了解整体流程和大概过程。
遇到设计数据库时可以按照这个思路一步步的考虑遇到具体问题再做具体分析,进一步解决问题。
2025-11-27
四川·绵阳