演讲嘉宾|李也 博士
编辑|Kitty
策划|QCon 全球软件开发大会
大模型 Agent 在智能运维场景落地时常常遇到“做 demo 容易,泛化难”的问题。在 2025 年 QCon 全球软件开发大会(上海站) 上,阿里云云原生可观测算法专家,香港中文大学计算机专业博士李也作了题为 “突破泛化瓶颈:阿里云智能运维 Agent 评测体系实践”的演讲,他深入介绍了如何利用评测集验证并提升基于 Agent 的智能运维算法泛化性的实践。
预告:将于 4 月 16 - 18 召开的 QCon 北京站设计了「Agent 可观测性与评估工程」专题,本专题立足架构与工程实战,系统探讨如何构建面向 Agent 的全链路语义观测体系,实现对意图决策、中间状态与工具调用的可追踪、可回放、可诊断;同时通过覆盖离线评测与在线实时度量的评估体系,对任务成功率、路径质量、输出稳定性与效果进行持续量化,驱动 Agent 从“基于经验的盲目调优”转向“基于数据驱动的持续演进”。敬请关注。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
今天我带来的分享题目是《突破泛化瓶颈:阿里云智能运维 Agent 评测体系实践》。我所在的团队专注于智能运维,我们的口号是“让天下没有难查的故障”——这句话借用了阿里电商“让天下没有难做的生意”的句式,但故障排查至今仍远未变得轻松。就在不久前,一家海外友商就爆发了一次重大故障;倘若“天下已无难查故障”真的成为现实,这类事故或许就能被提前化解。
1 智能运维泛化之痛
我们深耕智能运维多年,真正的痛点究竟在哪里?为何“天下无难查故障”仍停留在口号?首先,我把自己这些年踩过的坑、流过的汗,浓缩成“泛化之痛”的心路历程。最早,我们像所有人一样,从“规则 + 算法”起步:先写死一条条规则,再让算法在规则的缝隙里补位。大模型浪潮到来后,我们又忙着搭上下文工程、跑大模型工作流。最近,智能体(Agent)概念爆火,我们自然也没缺席,或多或少都试过几轮。
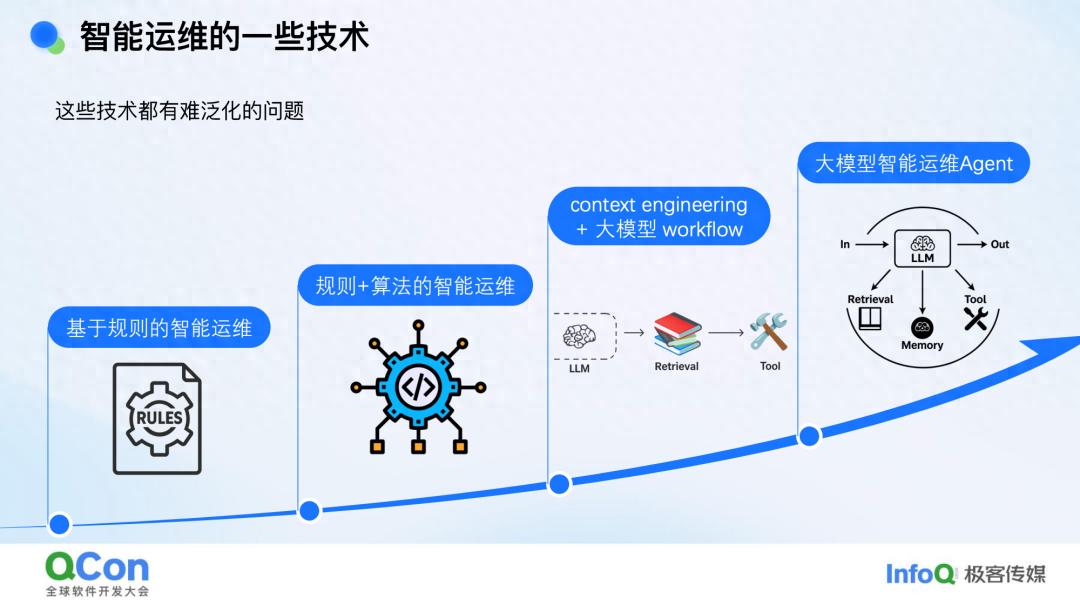
然而,无论规则、算法还是大模型,都绕不开“泛化”这道坎。日常运维里,我们依旧依赖阈值:CPU 超 80 % 就告警,磁盘剩余 10 % 就红灯——这种做法简单直接,也确实救过急。但经验告诉我们,固定阈值像一把刻度不变的尺子,量不准千变万化的系统。同一台机器 80 % 是常态,换一台就可能异常;昨天有效的日志关键词,今天系统升级后消失,告警立刻哑火。于是,我们写下一串又一串 if-else 规则:若网络断开且下游大面积告警,则判定为网络故障。
后来,我们做算法的同事登场,承诺用“动态基线”取代死板阈值:不再 80 % 一刀切,而是让曲线自己“长”出上下界,还贴心地剔除节假日、周末周期。听上去很美,用起来却棘手——不同指标对周期、敏感度要求各异,调参调到怀疑人生。日志侧也一样:模板提取算法能自动把相似日志归堆,却常把 IP 地址固化进模板,或把常量错当变量,结果误报比手配规则的方案还多。再激进一点,有人提出“全自动规则挖掘”,声称无需人工写 if-else。现实是,标注数据要人堆,算法假设又多,产出的规则很可能不如手写的那几行规则鲁棒。
刚才说到算法难以泛化,那么大模型是否就能破局?在座或许有人试过:把线上 Dashboard 截图、诊断页面、日志和监控画面一并丢给大模型,让它“看图说话”。初次体验确实惊艳——昔日只有老专家才能一眼识别的异常,如今模型竟也能侃侃而谈,甚至直接给出根因。日志再多,它也能梳理得头头是道,仿佛通用智能真的降临。
然而用得久了,便会发现“幻觉”如影随形。这不是 bug,而是大模型自带的 feature:它会把一次普通的 GC 增多臆断为内存泄漏,若按此排查,只会南辕北辙。GC 上升或许只是刚升级的 Java 版本在重新调整策略。又如日志里明明没有 500 错误,只因提示词里出现了“错误”二字,模型便一口咬定“肯定有 500”,任你如何纠正,它都固执己见。
倘若再往前走一步,用所谓“大模型工作流”把诊断过程编排成固定节点,局限性同样明显:节点一旦写死,便难以随场景变化。更棘手的是,模型并不总听指挥。过去我们 debug 传统代码,if-else 逻辑清晰,错了总能定位;如今却像在驯服一匹烈马,你叮嘱它“只读勿写”,它却可能顺手删库;同事用 Cursor 生成脚本,一不留神确认了 rm .*,半天成果瞬间归零。实验也表明,即便是最前沿的模型,当指令超过两百条时,遵循率也会急剧下降。
大模型 Agent 看似无所不能,实则把旧疾与新病一并打包:幻觉、提示词不服从依旧存在,又额外添加了“自主决策”带来的麻烦。JSON 少一个引号、SQL 多一个逗号,它便原地卡死;陷入死循环后,会无休止地“分析—探索”,却迟迟给不出终点。要把 Agent 做扎实,必须为其配备成体系的工具链,这本身就需要大量时间与精力。
对我而言,最难受的是失控感——按下葫芦浮起瓢。我们试着收紧缰绳,要求“仅基于证据作答”,它立刻变得过度保守,一句“无法判断”便不再行动;限定“只能使用内部知识库”,遇到稍有外延的问题便拒绝合理泛化。再让它严格按模板输出,它竟能生成格式完美却毫无价值的 Mock 数据,令人哭笑不得。
2 高质量的评测集的重要性
既然“泛化性”被反复提起,那我们究竟在谈论什么?坦率地说,在缺乏明确边界之前,我们甚至说不清自己希望模型泛化到哪些场景。于是,我斗胆提出一个“暴论”:唯有先构建一套评测集——一块可复现、可度量的“试金石”——泛化性才会从抽象口号变成可触摸的目标。
他山之石,可以攻玉。代码生成、数学推理、科学问答等社区早已铺就大量公开 benchmark;一旦基准确立,模型能力便在这些榜单上肉眼可见地跃升。数学定理证明、LeetCode 做题,过去遥不可及,如今大模型捷报频传。这让我们不禁设想:倘若智能运维也能拥有同样严谨的评测体系,是否就能复现“刷榜即进步”的良性循环?

在回答“评测集到底有什么用”之前,我更想先描述一种在没有评测集时几乎必然出现的场景,它听起来像故事,却每天都在真实地上演。
某日,高层突然决定要做一次 AIOps 演示:线上数据库被打爆,事后发现大量慢 SQL 的根因,源于某次代码变更引入了长连接。老板只给一句话:“把根因定位做成 Demo,下周演示”。如果目标只是让屏幕上的流程跑通,我们总有办法“交卷”:先写一条规则,把“长连接、CPU 飙高、活跃线程数激增”等现象全部 if-else 串起来;再套一层算法壳,让曲线看起来有“智能”;最后用大模型工作流把巡检、日志检索、知识库问答封装成 Agent,把前因后果写进 Prompt,一个光鲜的 Demo 便宣告诞生。老板若说“一个不够,再来五个”,我们只需把同样的套路复制粘贴,换几组关键词即可。可一旦现场数据稍有偏差,整套演示便可能当场穿帮,因为没人知道这套“万能脚本”在真实世界到底能跑多远。
倘若没有评测集,仅凭 Demo 验证,老板的任务确实可以快速完成:只要针对“变更导致连接池耗尽”这一单一场景,规则、算法或大模型工作流都能交出漂亮答卷。然而一旦场景换成“Java 版本升级引发 GC 陡增”,同样的方法便可能失灵——大模型时而答对,时而答错,成败全凭运气。所谓“泛化”不过是一句空话。
评测集的价值,正在于把“泛化”从口号变成可度量的指标。它首先像一面镜子,照出任何 AIOps 方法的边界:Demo 中光鲜的流程,可能在评测集上寸步难行。其次,它又是一把磨刀石,让优化有迹可循。最朴素的实践,是把内部评测集铺开到日常可能出现的各类故障,再以“打补丁”的方式增补规则,手工消解冲突,直到规则集能覆盖九成以上案例。
若再往前一步,算法工程师可依据评测集调参;大模型工作流可据此重塑节点与提示词;Agent 开发者则能看清缺哪些工具、需何种脚手架,甚至直接拿评测集里的标注数据做监督微调或者强化学习。有了评测集,我们做的就不再只是实验室里的“玩具”,而是可以放到成千上万真实线上故障里去验证和打磨的“正式产品”。

评测集的价值贯穿智能运维的全生命周期。开发阶段,我们只需抽取少量典型样本,就能快速验证算法或数据采集链路是否跑通;进入评估与调优环节,同一套评测集又成为衡量改进效果的标尺。上线后,随着真实故障不断汇入,评测集持续扩容,形成“越用越真、越真越用”的正反馈。若公司愿意开源,社区便可可以共同丰富这套基准,让评测集像雪球一样越滚越大。
3 如何构建高质量的评测集
既然 benchmark 的重要性已成共识,下一步便是“如何落地”。要回答这个问题,先得对软件系统做一次简洁而完整的抽象。在我看来,任何系统都可被拆成四层:最上层是输入,即持续涌入的 workload 与请求;中间是代码与配置,它们共同决定业务逻辑;再往下是计算、存储、网络等系统资源;若系统带状态,历史数据和状态也会影响软件系统的运行。最终,所有处理结果汇聚为输出。所谓故障,正是输出与预期发生偏离。
因此,一份高质量的 benchmark 必须尽可能覆盖上述全部维度:输入的多样性、代码 / 配置的多样性、资源瓶颈的多种形态,以及状态演化带来的长尾异常。只有把这些“面”都考虑到,评测集才能真正成为衡量智能运维方法泛化能力的标尺。
我们回头审视最初那个“代码变更导致数据库线程打满”的案例:输入流量本身并无异常,真正的变量是代码变更;新代码在运行过程中耗尽了数据库线程这一关键资源,最终表现为大量慢 SQL,拖垮整个系统。在这个故障案例中,我们可以把这一链条拆成“根因—传播路径—结果”三节点。类似地,只要我们能用同样方式拆解所有潜在故障,并确保 benchmark 覆盖每一类根因、每一条传播路径、每一种结果,就能说这套评测集的“覆盖度”是完整的。
覆盖度只是第一关,第二关是“真实度”。首先,系统架构必须真实。我们注意到,不少学术 benchmark 直接拿开源项目“造”场景,与生产环境差距甚远。其次,流量必须真实。有些 benchmark 的流量靠“拍脑袋”模拟;而真正贴近业务的流量,通常只有一线运维团队才拥有。再次,各组件的可观测数据也必须真实。很多 benchmark 为了突出异常,直接把 CPU 利用率从 0 % 拉到 100 %,或编造一条看似吓人的日志,而线上系统的曲线往往平缓得多,日志也没那么戏剧化。唯有把这些细节都还原,benchmark 才能经得起真实世界的考验。

既然目标已定为“既真实又全面”,下一步便是落地路径。我们初步梳理出三条互补思路,并尝试取长补短。
第一条最理想:直接采集线上真实故障。每当系统异常,立即抓取当时的可观测数据快照,并完整记录前因后果。为降低人工成本,可借助大模型做初稿标注,但经验告诉我们,完全依赖模型并不可靠——若大模型已能精准归因,便不会仍有“难查故障”。因此,最终仍需人工复核与修正。
第二条借鉴学术界常用的故障注入法:在开源系统里植入缺陷,快速生成案例。更进一步,可借用阿里云内部的演练环境——一个按比例缩微的真实集群——回放真实流量并注入故障,从而复现部分线上场景,兼顾成本与逼真度。
第三条则是构建可运行的模拟系统。该系统仅对输入输出做轻量级 Mock,却保留真实调用链路与资源消耗特征,可低成本、大批量地生成故障样本。
上述三种手段在“覆盖度”与“真实度”上各有利弊。我们的实践是:先用真实案例打底,哪怕故障现场没有被保留下来,也要尽量靠资深专家的记忆将其还原;若线上难以复现,则到演练环境或开源系统里做故障注入;若仍受限于环境差异,再退而求其次,用模拟系统补充边缘场景。通过层层递进,力求让评测集既贴近生产,又足够丰富。
关于案例的生成方式,我们已对“真实性”有了直观感受;接下来需要厘清“覆盖度”究竟指什么。在阿里云,我们使用 UModel 对可观测数据做统一建模:所有指标、日志、链路追踪被归拢到同一张以实体为中心的图里——应用、容器、主机、数据库等皆是节点,各自的监控项、日志字段 作为属性挂在节点上。下面这张大图便是我们可观测数据的全景 Schema。

因此,只要故障案例能触及图中每一类实体、每一条属性,我们便认为覆盖度足够。衡量方法也简单:从实际故障出发,若每个真实异常都能在评测集中找到对应样本;同时,所有被采集的可观测字段(既然我们决定收集,就默认其有用)都被至少一个案例触发,那么这套 benchmark 的完备性即可得到验证。
4 阿里云 AIOps 评测集 (持续发布)
一套高质量评测集是讨论“泛化性”的前提,也是持续优化各类 AIOps 方法的抓手;同时,我们也摸索出一套“既真实又全面”的建设思路。
阿里云对 AIOps 及配套评测集均作长期投入。我们将沿着前文所述路线,持续采集并脱敏更多真实故障,逐步扩大覆盖范围,并把可开源的部分全部开放。目前,我们已接入三类数据源:开源系统、内部演练环境以及线上生产系统;所有数据统一存入阿里云云监控 2.0 与日志 / 指标存储,任何持有阿里云账号的用户均可免费访问。对于需要主动注入的维度——请求流量、系统资源、代码变更及历史状态——我们主要使用 ChaosBlade 与 ChaosMesh 等混沌工程工具。实践中发现,这些工具偶尔会带来副作用:例如注入 CPU 故障可能连带推高内存,内存泄漏也可能触发 CPU 飙高。因此,若今后在由故障注入产生的评测集中看到类似现象,请多留意,真正的根因未必是注入点本身。相较之下,直接采集线上可观测数据得到的案例,在真实性上仍无可替代。
目前,我们已沉淀 2 000 余个原始案例,经脱敏与校验后发布 200 余个,并仍在持续扩充。这套评测集可与学术界同类基准(如 Open-RCA)互补使用——基准越多越好。若某种方法在多套评测集上均表现稳健,其可靠性便不言而喻。
5 基于评测集的智能运维 Agent 能力提升实践
前面我们反复论证了评测集的重要性,也介绍了如何构建它。接下来,大家最关心的恐怕是:这套评测集到底有没有带来实打实的提升?
规则 + 算法在已收集的 3000 余个真实样本上,自动规则挖掘算法在训练集里取得了接近 100 % 的准确率与召回率。虽然存在过拟合风险,但至少说明算法能够充分拟合已知故障模式。
大模型工作流以“正则表达式生成”这一高频需求为例:裸用通用大模型时,正则可解析率不足 50 %,字段抽取完整度也徘徊在 50 % 左右。我们针对评测集里的 bad case 设计了一条专用工作流,把上下文、日志样例、目标字段一并喂入,再辅以校验与回退节点,最终把可解析率提升到 98 %,字段完整度提升到 95 % 以上。
大模型 Agent基于同一批评测集,我们持续调优脚手架与工具链。在首批 200 余个已验证案例中,根因召回率达到 87.5 %,定位准确率超过 80 %。这些数字并非刻意刷榜,而是日常迭代的自然结果;如果评测集本身覆盖全、场景真,刷榜也就有了实际意义。将评测集里已标注的根因诊断结果用于监督微调和强化微调,排序任务的准确率已稳定在 80 % 以上。

听到这里,大家或许仍觉抽象。做个总结 -- 我只希望大家记住三件事:
第一,没有评测集,泛化性就无从谈起,生产环境只能“开盲盒”。第二,构建高质量评测集有方法论可循:真实场景优先,覆盖度兜底,持续迭代。第三,阿里云正按这套方法论建设并开源评测集,同时用它驱动算法、工作流和 Agent 的持续改进。
最后,回到我们的口号——“让天下没有难查的故障”。第一步,便是把天下可能出现的故障悉数纳入评测集。愿今天的分享能让各位有所收获。谢谢大家。
演讲嘉宾介绍
李也,阿里云云原生可观测算法专家,香港中文大学计算机博士,在智能运维和数据驱动的决策方向有近 10 年科研和落地经验。主导的异常检测和根因定位等 AIOps 算法在阿里云大规模落地。在 ASPLOS、SIGMOD、WWW、VLDB、TKDE、TON 等顶会顶刊发表过多篇 AIOps 算法论文,并在这些国际会议上做报告。目前他专注于大模型 Agent 及其强化学习在智能运维场景的落地。
会议推荐
OpenClaw 出圈,“养虾”潮狂热,开年 Agentic AI 这把火烧得不可谓不旺。在这一热潮下,自托管 Agent 形态迅速普及:多入口对话、持久记忆、Skills 工具链带来强大生产力。但这背后也暴露了工程化落地的真实难题——权限边界与隔离运行、Skills 供应链安全、可观测与可追溯、记忆分层与跨场景污染、以及如何把 Agent 纳入团队研发 / 运维流程并形成稳定收益。
针对这一系列挑战,在 4 月 16-18 日即将举办的 QCon 北京站上,我们特别策划了「OpenClaw 生态实践」专题,将聚焦一线实践与踩坑复盘,分享企业如何构建私有 Skills、制定安全护栏、搭建审计与回放机制、建立质量 / 效率指标体系,最终把自托管 Agent 从可用的 Demo 升级为可靠的生产系统。
