说明:本文主要介绍材料筛选为何依赖高通量计算,以及候选空间、统一计算基准、筛选指标和验证约束之间的关系。

材料筛选到底筛的是什么?
材料筛选面对的是一组会不断扩张的候选空间:元素组合、晶体原型、缺陷类型、表面晶面、掺杂位点、吸附构型和反应环境都会改变候选材料的身份。筛选的定量任务是在这一大片空间里建立可比较的判断顺序,先排除明显不合适的候选,再把少量值得精算和实验验证的体系留下来。
高通量计算在材料计算里指向一套标准化的数据生产过程:用统一规则生成结构,用同一套近似和收敛要求计算能量、电子结构或力学量,再把结果解析成可检索的数据表。可比性是筛选表的骨架,因为筛选问题关心大量候选在同一基准下的相对位置。
候选集合、目标性质和判断约束共同决定筛选表的物理含义,也决定后续排序能否被复查。第一类是候选集合,例如氧化物、二维材料、金属有机框架、合金表面或单原子催化位点;第二类是目标性质,例如形成能、能带、弹性常数、离子迁移能垒、吸附自由能或光吸收范围;第三类是判断约束,例如相稳定窗口、元素成本、毒性、合成温度、电化学电位和工作气氛。少掉任一类,筛选结果都会失去物理约束,看起来整齐的排行榜也会变成只按单个数字排序的表格。
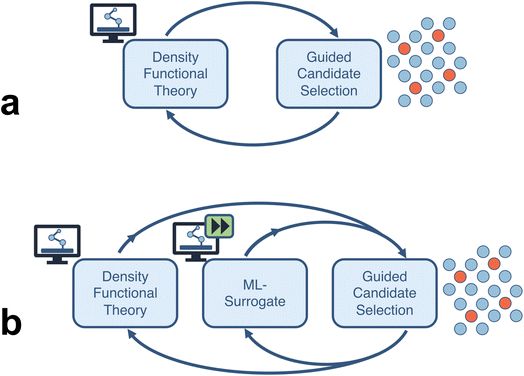
图1. 闭环筛选框架把 DFT 计算、机器学习代理模型和候选选择连成迭代过程。DOI:10.1039/D2DD00133K
这样的循环把研究者的经验判断转化成可重复的数据生产过程。经验仍然负责提出材料家族和约束条件,DFT 负责给出结构弛豫、总能和电子结构,机器学习模型负责在已计算数据附近加快候选排序。高通量计算承担的是中间的定量筛分,它把“可能有希望”这种模糊判断改写为带有能量、结构和性质来源的候选清单。
第一性原理计算在这里的价值来自物理定义清楚。形成能来自总能差,带隙来自电子本征态,弹性常数来自应变能或应力响应,吸附能来自表面和吸附物的能量差。每个指标都带有模型前提,高通量流程要把这些前提一并记录下来,后面的排序才有复查依据。
为什么候选空间必须成批计算?
材料空间的增长速度很快。二元体系已经包含大量组成比例和结构原型,进入三元、四元体系后,可能的化学计量比、占位方式和有序构型会继续增加;若研究对象变成表面、缺陷或吸附体系,晶面、覆盖度、缺陷电荷态和吸附位点又会加入组合。人工逐个挑选候选很容易沿着熟悉元素和高频结构前进,错过成分相近但能量更接近目标窗口的区域。
高通量计算把“候选太多”这个难题分解为几个可以批量执行的判断:结构是否能弛豫到合理局部极小值,形成能是否进入可竞争范围,能量高出凸包 Ehull 是否过大,目标性质是否接近需求,元素约束是否符合应用条件。Ehull 不提供合成保证,它只是相稳定筛选中的早期门槛,后面仍需处理动力学、温度、缺陷和实验路径。
OQMD 这类数据库的价值就在于把大量已知和预测化合物放到同一相空间里。单篇研究只能覆盖少量体系,数据库可以把不同组成、结构和能量关系拼成连续图景,让研究者看到哪些区域已被实验占据,哪些区域只有计算候选,哪些区域被竞争相压低。筛选真正依赖的是相互比较,单个材料的总能再精确,也无法脱离邻近相判断稳定竞争。
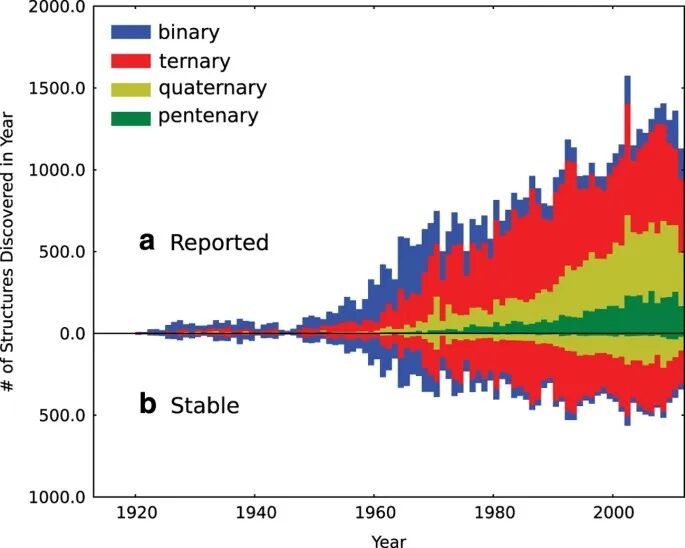
图2. OQMD 统计了实验已知化合物与计算预测稳定化合物随时间增加的关系。DOI:10.1038/npjcompumats.2015.10
成批计算还有一个容易遗漏的好处:失败结果也能留下信息。某些结构弛豫后坍塌,某些候选总是高出凸包很多,某些成分在多个原型里都不稳定,这些负结果会把搜索空间削薄。筛选效率来自正负样本共同约束,漂亮候选和被排除候选共同塑造下一轮搜索范围。
对催化和储能体系来说,候选空间还会受到工作条件重塑。相同材料在不同晶面、不同电位、不同覆盖度和不同溶剂模型下可能给出不同吸附自由能或迁移能垒。高通量流程能够在同一批候选上重复这些条件变化,让筛选从“哪个材料最好”转向“哪个材料在目标条件附近更值得深入计算”。少数手工样本难以外推条件依赖,否则容易把偶然构型当成普遍趋势。
自动化流程怎样规范筛选数据?
同一批候选材料要进入筛选表,前提是计算基准相互一致。泛函、赝势、U 值、k 点密度、截断能、磁性初态、结构弛豫标准和后处理脚本都会影响数值。高通量仍然受精度要求约束,这些设置要固定或显式记录,误差来源才能在全表范围内追踪。
数据库论文经常会拿计算形成能与实验热化学数据对照,用大样本偏差分布评估同一方法的误差范围。这个误差分布决定筛选阈值的宽度:若形成能误差达到几十 meV/atom,筛选时就不宜把相差几 meV/atom 的候选排出过于绝对的名次。阈值必须和方法误差匹配,筛选才不会被数值噪声带偏。
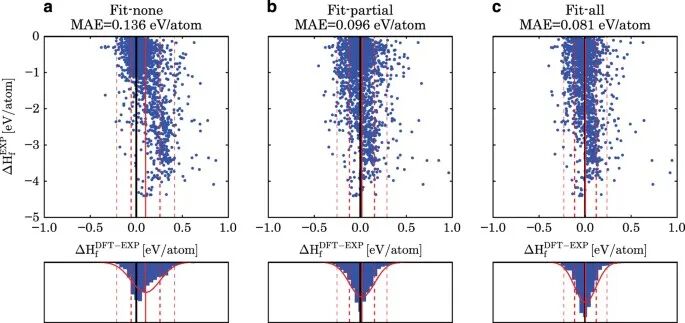
图3. OQMD 用大样本形成能对比评估高通量 DFT 数据的系统偏差和误差范围。DOI:10.1038/npjcompumats.2015.10
统一基准把高通量结果整理成数据表,并区别于文件夹堆积。每一行可以对应一个结构、一个表面模型或一个吸附构型,每一列记录结构指纹、能量、带隙、磁矩、体积、弹性模量、吸附能、反应自由能、计算状态和数据来源。数据表里的“状态”同样是科学信息,例如未收敛、结构重构、磁性翻转或对称性改变,都能提示模型假设和目标性质之间出现偏离。
自动工作流的作用是减少人工切换造成的不可控差异。候选生成、输入准备、任务提交、错误恢复、结果解析和数据库写入各自有明确接口,研究者可以把注意力放在物理筛选标准上,减少在几百个目录里手动确认文件名的劳动。流程自动化服务于可复查的数据生产,并不把材料判断交给脚本。
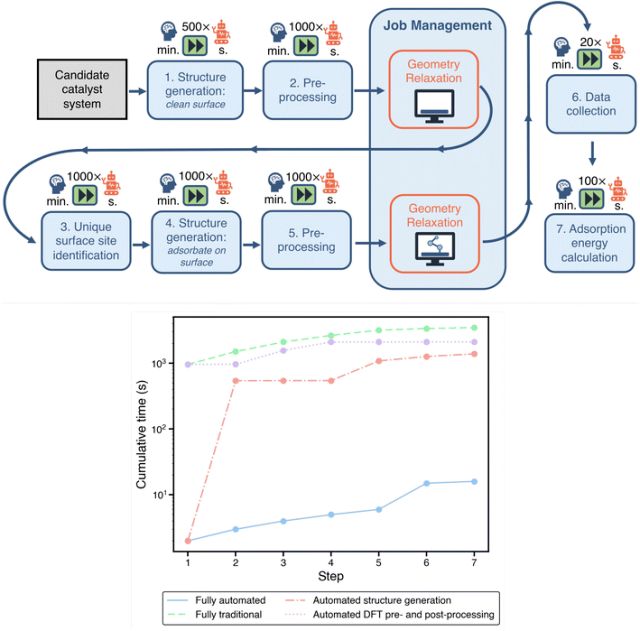
图4. 自动计算框架把候选选择、DFT 数据生成和模型更新组织成可追踪流程。DOI:10.1039/D2DD00133K
一个候选来自实验结构、原型替换、枚举有序化、随机生成还是机器学习生成,会影响后续信任程度,也决定筛选表能否追溯到具体模型来源。对于含缺陷、表面和吸附体系的筛选,模型尺寸、真空层、覆盖度和电荷补偿方式也必须进入元数据。没有来源记录的高通量结果很难复核,因为看似相同的材料名称可能对应完全不同的计算模型。
寻找稳定半导体时,Ehull、带隙、有效质量和介电响应常被并列使用;寻找电催化候选时,ΔGH*、ΔG*OH、ΔG*OOH、表面稳定性和导电性会共同限制排序;寻找固态电解质时,迁移能垒、相稳定窗口、电子带隙和界面反应能都应进入候选排序。单个描述符承担的筛选功能有限,描述符选择必须回到具体材料问题和目标应用条件。
多保真筛选如何缩减材料候选?
高通量筛选给出的通常仍是一批候选。第一轮筛选常用便宜且稳定的指标压缩空间,例如组成合理性、相稳定窗口、基础电子结构和元素约束;第二轮再加入更贵的计算,例如混合泛函、声子谱、AIMD、NEB、表面自由能、缺陷形成能或微观动力学。多保真筛选的本质是把计算成本放到最可能改变判断的位置。
实验复核不负责给计算“盖章”。高通量计算多半在理想周期模型、零温或有限近似条件下工作,真实样品还包含晶粒尺寸、杂质、非化学计量、应力、溶剂、界面和制备路径。候选进入实验之前,计算结果要转化成可观测的结构、谱学、电化学或输运指标。计算筛选和实验筛选之间要有可对应的观测量,否则候选排名无法被样品结果有效检验。
在新能源材料、催化剂和半导体筛选中,许多研究会把热力学稳定、目标性质和可制备因素叠加成筛选漏斗。某个材料可能带隙合适,却在竞争相中不稳定;另一个材料可能吸附自由能接近理想值,却存在表面重构或中间体毒化;还有材料在 DFT 数据库里表现突出,但元素成本或毒性不适合目标场景。高通量计算负责暴露这些取舍,它把候选从单指标排名转成多条件约束下的优先级。
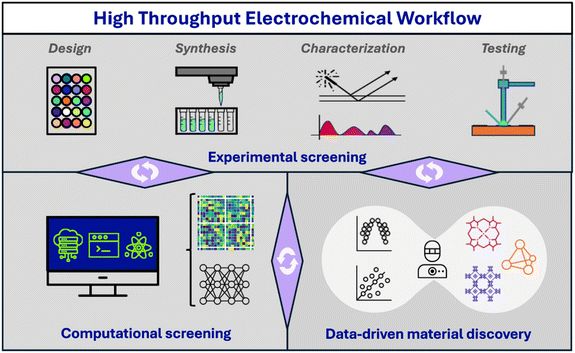
图5. 高通量材料研究把计算预测、样品制备、表征和性能反馈连接成筛选流程。DOI:10.1039/D5TA00331H
DFT 常用的交换相关泛函会低估部分半导体带隙,强关联体系对 U 值或磁性初态敏感,表面吸附能会随覆盖度和溶剂模型变化,缺陷浓度还受费米能级、化学势和动力学迁移控制。这些限制决定补证方向,候选清单进入下一轮计算时才知道该补声子、AIMD、NEB、缺陷还是实验表征。
材料筛选离不开高通量计算,原因并不神秘:候选空间太大,单点计算缺少相互比较;目标性质太多,单一指标无法承载完整判断;模型条件太细,人工记录难以保证基准一致;实验成本太高,计算先把搜索范围压缩到可操作规模。高通量计算的真正作用是把材料发现从零散试探转为有来源、有阈值、有误差范围的候选排序。
当筛选结果进入后续研究,最值得保留的是每个候选为什么留下来:它在哪个相空间内稳定,目标性质落入什么范围,主要计算使用了哪些近似,哪些风险还没有排除。保留这些记录,候选清单才能继续承接更高精度计算、实验制备和机理分析。材料筛选的速度来自批量计算,判断质量来自对每个筛选指标物理含义的约束。