你每和AI说一句话,背后都在消耗一种叫“Token”的东西。直到最近,它才有了官方规范的中文名称——“词元”。它看不见摸不着,甚至被称为“数字石油”。为什么中国模型能让全世界抢着调用?这篇文章,带你一次看懂Token。

01
Token:AI看得懂的最小语言碎片
当你跟AI说一句话时,它会将这句话拆分成最小的单位来处理,这些小块单位就叫做Token(词元)。它既不是字也不是词,而是模型,是用来理解世界的最小计量单位。也可以把它理解为“把人类语言拆解成机器能懂的碎片”。

我们做一个测试。“你是谁?”一般是4个Token,包括(你、是、谁、?)这四个。而英文“who are you?” 也是4个Token(who、are、you、?)。
和AI聊十句话大约需要500个Token。生成一张图片需要的Token少则1000,多则5000。生成一段15秒的AI视频大概需要消耗二三十万个Token,相当于一本中篇小说的文字量。
也就是说,人类与AI的对话,本质上是一场Token的流动。
02
Token的算法秘密
Token计算背后的原理,其实就是一个“分词”算法。
简单说,先定好一个“词表”,也就是模型提前统计了大量文本,把最常见的字、词、子词(比如“ing”“er”等)、标点都放进词表。切分时,尽量让每个片段都在词表里,并且让总片段数尽量少。
比如英文常用词“who”是一个Token,“are”也是一个Token,不常见的词会被拆成更小的部分。比如“unhappiness”,就会被拆成“un”和“happiness”两个Token。

中文一般按常用字或常见词切,所以“你是谁?”通常分成“你”“是”“谁”“?”四个Token。而有些常见双字词会被当成1个Token,比如“我们”、“可以”等。
平均下来,1个英文单词约等于1至1.5个Token,1个汉字约等于0.8至1.2个Token。
不同模型用的词表不同,合并规则不一样,所以同一个句子在不同模型里Token数量可能差一两个。
有人说Token像用电时“度”这个单位,衡量用电的多少。两者像也不像。像的地方在于,两者都是计量单位和收费标准,电力公司按度收费,大模型公司按Token收费。
不像的地方在于,一度电在物理上是固定的能量,但一个Token的长度不是固定的,字符数不同。
03
Token如何计费?
编程、聊天、办公等算力消耗以Token为计量单位。无论是文本问答,还是文生图、文生视频、图生视频,都会消耗大量算力。前不久,OpenAI宣布关闭Sora视频应用,便是例证。运行视频生成服务需要消耗庞大计算资源和电力,这对任何企业而言都是一笔巨额开支,而关闭Sora则将释放大量算力资源。
一个Token大概多少钱,得看你用哪个模型。贵的和便宜的能差出几十上百倍。
数据显示,Anthropic Claude 3.5 Sonnet输出100万Token约15美元,而中国头部模型同等性能下可降至2.6美元甚至更低。
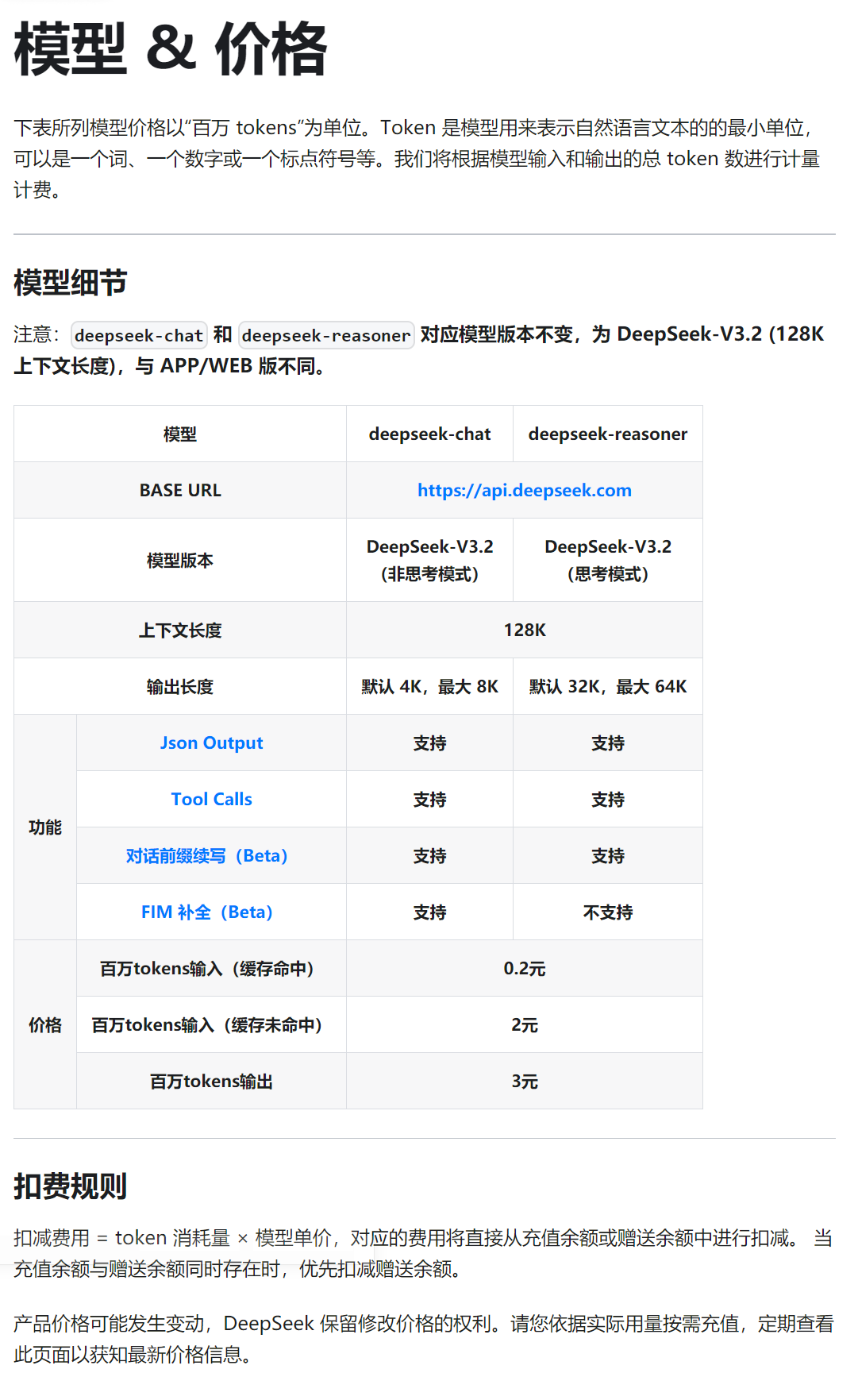
这里提到的100万Token是AI行业里API计费的标准单位,其价格分为“输入(你问的)”和“输出(它答的)”两块,后者通常更贵。
据DeepSeek开放平台显示,百万Token,输入与输出相差十倍。
04
为什么感觉Token很费钱?
很多朋友养了“龙虾”,结果发现,租云空间和服务器花不了多少钱,可买Token却花钱如流水。这是为啥呢?
原因其实很简单。你花钱买的100万Token是输入和输出加在一起算的,而且输出占了大头。这里的大头,一方面指输出的内容多,另一方面指输出的内容贵。输出价格通常是输入的3到10倍,因为模型“想答案”比“看问题”更费劲。所以,尽量把问题问清楚,别让AI写废话。

下面我们来算笔账:
如果你买的是普通模型,你问一句(输入),消耗50Token;模型答一大段(输出),消耗500Token。这样聊10轮,一次对话就耗掉5500Token。
加之频繁使用,不断修正问题,甚至让它生图生视频,一天几万甚至几十万Token很正常。100万Token有200次深度对话就用完了。
如果你用的是推理大模型,就像DeepSeek-R1这样的,会更“烧钱”。因为它在回答前会自己先“思考”一大段,这个思考过程也烧Token。甚至,思考过程通常比最终回答还长。有时候回答输出了500 字,实际思考却输出了1000字。
更有甚者,如果你上传文档让大模型帮忙处理,上传了一本10万字的书,就相当于输入了大约10万Token。然后再问问题,它再回答,那这个消耗量更是惊人的。
05
谁在为你的Token买单?
以上的很多动作,如果我们不用“龙虾”,而是直接跟大模型交流,却不需要花一分钱(有的可能会消耗积分),这又是为什么?
还是那句话,免费不等于不消耗Token,而是有人替你买单了。

你在DeepSeek网页版、豆包App里随便问,确实不用花钱。但这背后,你问的每一句话、它答的每一个字,都在实实在在地消耗Token,只是平台方替你付了这笔钱,没找你要罢了。就像你用微信不花钱,但腾讯的服务器、带宽、电费一样在烧钱。
那平台又在图什么呢?
首先,平台肯定不会做赔钱的买卖。他们会向企业也就是B端收API调用费,DeepSeek、豆包都提供企业API服务。企业按Token用量付费,这才是真金白银的收入来源。我们用“龙虾”,就相当于“龙虾”作为B端智能体向大模型购买Token,这个钱最终要落在使用者头上。
另外,很多像阿里、字节、腾讯这些大厂都有云业务,不少人的“龙虾”就是在这些云服务器上配置的。有时候大模型推出Token包月,实则在用云服务的钱补贴,这背着抱着一般沉,只是营销手段罢了。
最重要的一点,平台在培养用户习惯,跑马圈地,建立生态。等用户离不开它了,再考虑收费,或者用其他方式变现,比如AI电商、增值服务、会员等。这个逻辑和当年的杀毒软件、网约车、外卖大战一模一样。
06
Token就是数字石油
过去公司之间拼什么呢?拼人拼团队,拼谁更努力。但现在,变成了拼谁的Token更便宜,更智能。
原来为人类劳动者付报酬,是在购买他人生中不可逆的一段时间。而现在,脑力劳动开始像支付水电费一样被使用了。打开龙头,才思泉涌,然后按Token付费,还不用担心龙头那边的大模型是在发呆还是在摸鱼。
公司的竞争变了,国家之间的竞争同样是颠覆式的。

工业时代,中国输出的是商品。而在AI时代,中国输出的是Token。
谁掌握了Token的定价权,谁就掌握了这个时代的新能源。没错,Token就是数字时代的石油。
我们安排给AI的每一项任务,它都要按消耗的算力来计费,算得越多、花得越多,而算力的燃料,归根结底是电。
中国是发电和用电大国。2025年中国全社会用电量首次突破10万亿千瓦时,相当于美国全年用电量的两倍多,也超过了欧盟、俄罗斯、印度、日本四个经济体用电量的总和。同样,中国总发电量也已突破10万亿千瓦时,其中清洁能源发电占比显著提升。
中国有这么多电,但存储困难,运输有损耗,还很难出口。但,Token可以。
有消息称,截至3月15日,中国AI大模型周调用量达到4.69万亿Token,连续两周超越美国,全球调用量前三名被中国模型包揽。
为什么全世界的开发者抢着调用中国模型呢?因为我们电太便宜了,转化到Token上,具有碾压般的优势。
算力中心直接建在电站旁边,富余的电、甚至负成本的电,可以一股脑灌进GPU,炼成Token卖给全世界,还不用装船、不用报关、零库存。
Token不只是技术术语,它正在成为AI时代的硬通货。从个人使用到企业竞争,再到国家之间的算力博弈,Token就像数字世界的石油——谁拥有更便宜、更充足的Token,谁就掌握下一轮增长的主动权。从用电到用Token,人类正在进入按“思维流量”付费的新时代。