导读 本次分享题目为基于 Apache Paimon 的实时湖仓架构探索。分享主要分为三个部分,首先简单介绍小米目前的实时湖仓架构和在建设实时湖仓的过程中所遇到的问题,以及期待的理想实时湖仓;然后简要介绍 Apache Paimon 项目,并通过几个典型的使用案例来说明 Apache Paimon 如何解决我们在建设实时湖仓过程中所遇到的问题;最后是对未来的展望。
主要内容包括以下几个部分:
1. 背景
2. 探索基于 Paimon 构建近实时的数据湖仓
3. 未来展望
分享嘉宾|钟宇江 小米 软件研发工程师
编辑整理|曾凤
内容校对|李瑶
出品社区|DataFun
01
背景
1. 实时湖仓建设现状
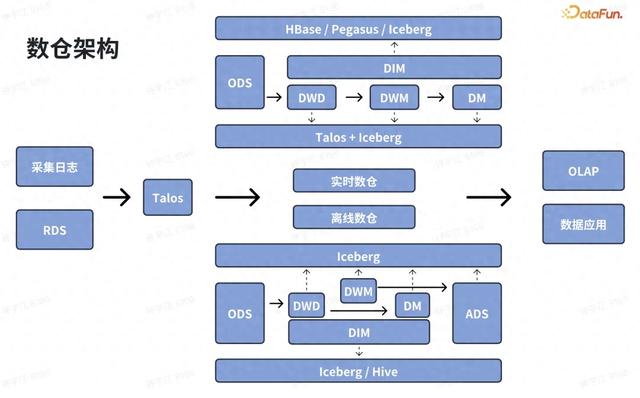
小米当前的实时湖仓计算框架以 Flink + Talos + Iceberg 为主。上图是目前典型的数仓架构,数据源通常是终端所采集上报的日志以及在线系统的交易数据,通过数据集成平台输送到 Talos 消息队列。其中,Talos 是小米内部自研的消息队列框架。图的上半部分是数仓的实时链路,计算框架以 Flink Streaming + Talos 为主,并使用 Iceberg 作为数据湖仓存储。此外我们会引入 KV 系统做大数据维表的 Join。数据经过分层加工之后输送给下游应用消费,包括即席查询、BI 和数据推送等等。在图的下半部分,除了数仓的实时链路部分,还有一条离线链路。实时链路一般为了追求性能,可能只会保留部分的数据属性,同时也会抛弃部分延迟上报的数据,存在数据准确性的问题。因此通常使用一条单独的离线链路来保证数据的完整性,确保在最后能够计算出正确的数据。
这套架构遇到了以下痛点:
第一是实时计算的成本比较高。目前 Iceberg 对于流计算的语义支持有限,对流计算过程中常用的操作,比如对 Stream Join、数据去重、部分列更新以及流读 changelog 功能的支持不是很好。因此需要把这些操作给放到计算里面去做,导致消耗的计算资源非常多,并且作业逻辑复杂。第二是架构复杂、稳定性差。比如大数据量下的双流 Join 场景,用户需要自定义大量的 Timer 来优化延迟关联情况;且因为数据量大导致 Flink State 非常大,需要引入外部 KV 系统来做补充,让逻辑进一步复杂化。第三是存储成本高。前文提到,我们的离线链路和实施链路分开,有两份的数据冗余,同时还有外部 KV 系统中的数据冗余,且一般来说 KV 系统的价格相比数据湖仓贵非常多。2. 典型案例
下面通过一个典型案例来说明。这是一个简单的 Flink Streaming 作业,消费两个 Talos 的事件流并进行过滤和转换操作,然后完成一个基于主键的双流 join。因为存在数据延迟上报,为了防止 Flink 作业状态过大,只会保存最近一段时间的数据,因此需要将更长周期的数据导入到外部的 KV 系统里。我们一般会用 HBase 或者 Pegasus 来做外部 KV 存储。对于延迟上报的数据,若 Join 本地状态数据失败,会读取外部的 KV 系统数据完成 Join,并写入下游进行消费,一般写入 Iceberg 或 Talos Topic。

这套系统也存在几个问题。第一是作业逻辑复杂。因为状态非常大,稳定性也差。第二是外部 KV 系统虽然能满足需求,但 Join 性能其实不高,且成本很高。
3. 典型案例对于实时湖仓的期待
接下来分享我们对于实时数仓链路的期待。
第一是希望降低计算成本,并能够更好结合流计算和数据湖仓平台,减少实时化带来的额外资源消耗。第二是简化架构,提升稳定性。希望实时的链路尽可能的简单,不需要用户去做定制性优化工作,减少用户开发负担,同时提升作业稳定性。第三是统一数据链路,尽量避免实时和离线两套链路导致的开发和运维成本,同时减少数据冗余。
这里通过一张图来说明我们对于实施数仓的期待。横轴代表数据的新鲜度,纵轴代表为了达到数据新鲜度所需要付出的代价。这条曲线的每个点代表在达到特定数据新鲜度时,所需要付出的最少成本。三角形代表当前的离线处理方案。离线处理的输入数据完整,或者说至少在进行离线计算的时候会假设输入数据是完整的,需要考虑的内容比较少,因此计算比较简单,很容易在达到某一个数据新鲜度时贴近理想曲线。但用户总是会想要更新鲜的数据。我们在做数据实时化的过程中会发现,提高数据新鲜度所要付出的成本会很高。比如正方形是我们当前实时方案所处位置,五角星是我们的理想状态。我们想要做的其实就是尽可能的让我们的实时方案往五角星的方向贴近,也即在界定好数据正确性的前提下,平衡好数据新鲜度和成本的关系。
02
探索基于 Paimon 构建近实时的数据湖仓
1. Apache Paimon 简介
Apache Paimon 创新地将 LSM 结构融合到 Lakehouse 架构,在有效应对流处理语义挑战的同时,对批处理及 OLAP 也有不错的支持。
Lakehouse:Data lake, ACID, Schema evolution, Time travelStream: LSM, Changelog, Lookup joinBatch: Row-level update, Z-Order, Statistics metadata接下来,通过几个典型的使用案例来说明 Apache Paimon 如何解决我们在建设实时湖仓过程中所遇到的问题。
2. 探索场景 1:使用 Paimon 优化 Stream join
首先是使用 Paimon 优化 Stream Join。

前文提到,在现有的 Iceberg 架构下,使用 Flink Streaming 完成双流 Join,存在一些痛点,包括成本高和架构复杂。Join 效率低的根本原因包括:
高频次的磁盘随机读网络 IO数据冗余
使用 Paimon 可以优化 Stream Join 的过程。Paimon 基于 LSM 数分层有序结构的 Partial-update merge 可以消除 Stream Join 过程中磁盘随机,从而将随机读磁盘变为顺序读磁盘,并减少 Join 带来的网络 IO。通过引入 Paimon,带来如下的预期收益。
省去 HBase 成本 10w/月作业稳定性提升作业逻辑简化,Flink Jar -> SQL3. 探索场景 2:Streaming upsert
第二个场景是 Streaming Upset。当前 Flink Upsert Iceberg 遇到了几个问题。第一是每次写入除了 data file 外,还会同时生成两个 Delete 文件,导致小文件比较多。第二就是它的每一个 Equality Delete 的应用范围是同个分区的全部历史文件,文件积累过多会导致读取性能变得很差,所以需要频繁 compaction。第三是对 Stream 流读支持不友好。我们在内部做了一些拓展,使其支持 Stream 流读,但其产生的不是精准的 Changelog,用户需要在下游加一个算子来生成精准的 Changelog。

相比之下,Paimon 通过使用分层排序的 LSM 树,其每一次数据合并不用合并全量的历史文件,而只需要对增量文件进行合并。并且由于其合并是分层的,不用每次都做 Full Compaction。

我们做了一个简单的测试,用一个 Flink Streaming 作业同时写 CDC 数据到 Iceberg 表和 Paimon 表,连续地以 Upsert 形式写入数据,然后通过 Compaction 来保证两种表的 Delta 文件不超过一定数量,保证查询性能要求。经过一段时间之后,计算产生的空间放大,我们发现 Iceberg 的空间放大远超过 Paimon。原因是 Iceberg 的数据没有经过合理地分层和排序。Iceberg 的 Streaming Upsert 功能在社区也被认为是一个尚未完成的特性,不推荐使用。

此外,Paimon 还有一个能力是能够实时生成 Changelog,下游就可以通过 Streaming 的 source 消费这些 log 数据。同时 Data File 也可以被下游的 OLAP 或者 ETL 直接查询,且支持多种不同 changelog-producer 以适应不同的场景。比如 INPUT 适合 CDC 写入;LOOKUP 可以支持实时性要求高的场景;FULL-COMPACTION 因为消耗比较大,适合数据量比较大但新鲜度要求不高的场景。通过 Paimon 来替换 Iceberg,带来的预期收益是降低 Compaction 资源消耗、减少写入小文件以及提升流读体验。
4. 探索场景 3:Lookup Join 提效
第三个场景是 Lookup Join 的提效。
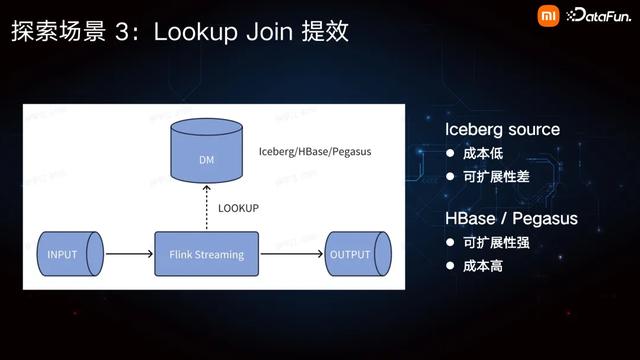
我们当前 Flink Streaming 的 Lookup Source 主要是 Iceberg、HBase、Pegasus 以及 Redis。对于 Iceberg,我们拓展了其 Lookup Source,且支持增量更新。它的一个特点是成本非常低,但是因为我们会把它直接缓存在内存数据里,所以其可扩展性比较差,数据量大一点可能就没办法支持。对于数据量大的场景,我们通常会使用 HBase 或者是 Pegasus 这样的 KV 系统来做 Lookup Join,其特点是可扩展性强,且由于脱离于作业之外,不会对作业的稳定性造成影响,但缺陷是成本会比较高。
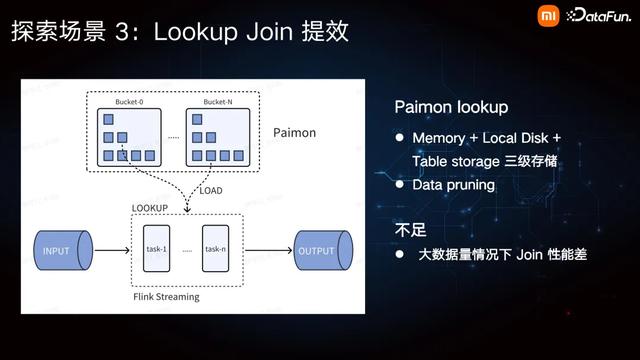
Paimon 支持直接作为 Lookup Source,并且 Paimon 在 Lookup 时会使用三级存储,也即内存、本地磁盘以及远程文件系统上的 Table storage。也就是说,Join 时先把最近常用的数据缓存在内存,使用少的数据放在本地磁盘。如果本地磁盘过期,它会直接拉取远程的数据。此外,Paimon 支持 Data pruning,使用方便。尽管如此,Paimon 现在的一个不足是在大数据量的情况下,Join 的性能会比较差,原因是他对数据流没有做很好的 Repartition。
因此,在 Flink Streaming 作业的每一个 lookup task 里,都可能 Join 到整张表的每一个分区里每个分桶的数据,所以需要经常把很大数据量都给拉取到本地磁盘来做 Join 操作。倘若维表经常更新,其拉取数据以及构建本地索引的负载会更高。

这里的一个优化方式,也是 Paimon 社区和 Flink 社区推动在做的事,是在 Lookup Join 之前,根据 Paimon 的 bucket 的聚类模式,加一个定制化的 Repartition 操作。数据流通过采用 Lookup 表相同的 bucketing 策略,避免在每个并发中都加载全表数据。我们预计用这种场景代替一部分的 Join HBase 或者 Join Pegasus 的成本,当然其灵活度没有 HBase 和 Pegasus 高,因为其对于作业的并发有要求,但是可以代替相当一部分场景。总结来说,我们预期的收益一是简化数据链路、节省 HBase 成本,二是数据统一收敛到湖仓平台。湖仓平台的运维以及开发比较方便,在我们内部也对接了非常多的查询引擎以及数据集成系统。
03
未来展望
最后对未来工作做一个展望。首先我们会继续挖掘 Paimon 在内部流计算场景下的应用。比如在 CDC 的数据集成平台上,之前很多是离线的,即落 Iceberg 表和落 Hive 表,后续可能会在数据新鲜度要求比较高的场景,直接集成到 Paimon 表,因为其对 Compaction 的要求不高。并且会在 Changelog 的场景做更深的挖掘。
第二个方面,我们希望做自动化的 Maintenance 服务。Paimon 当前的一些 Maintenance 服务,比如快照的过期、数据合并以及分区的 TTL,都支持在作业里面完成。这样的好处是非常方便,不需要平台的一些任务去帮忙维护。从长期的角度来讲,我们希望尽可能将这些 Maintenance 服务和作业做解耦。其一,这些 Maintenance 服务所需要的资源的负载以及时间跟生产作业是不同的,通过解耦能够进一步增加数据生产作业的稳定性;其二是可以利用一些混布的在线资源去做这些 Maintenance 服务,进一步降低资源消耗。
最后一个方面是智能优化。我们之前围绕 Iceberg 做了一套数据聚类策略智能推荐的服务。我们后续希望在数据查询 ETL 场景,把这一套服务拓展到 Paimon。
以上就是本次分享的内容,谢谢大家。