编辑:3DCV
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群。
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、3D视觉最新模组、3DGS系列(视频+文档)、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
0. 这篇文章干了啥?
单目深度估计(MDE)是一项基本的3D视觉任务,广泛应用于机器人、自动驾驶和虚拟现实/增强现实等领域。为了减少对深度标注的依赖,自监督单目深度估计已成为一种便捷且实用的解决方案,该方法利用单目视频、立体图像对或两者结合来通过视图合成生成监督信息,在此过程中将图像光度重建损失降至最低。与已知相机姿态的立体训练案例相比,从单目视频中学习更具挑战性,因为它需要一个额外的姿态网络来估计相机的自我运动。即便如此,与立体图像对相比,单目视频的收集要容易得多,这使得单目训练更具吸引力。因此,本文也专注于使用未标记的单目视频进行自监督训练。
最近的研究工作为提高准确性做出了各种尝试,例如引入掩蔽技术和利用分割先验。然而,这些方法仅在视频数据集中现有的固定相机视图之间进行视图合成,导致在遮挡或消失导致的不可见区域中指导不足。考虑到视频数据具有时间连续性,一个直观的想法是生成新的帧,即在时间维度上的虚拟相机视图。我们称之为时间增强,这可以通过视频帧插值(VFI)来实现。
从另一个角度来看,由于许多应用场景中都可以使用多帧进行推理,因此最近对多帧推理范式进行了研究。ManyDepth提出使用基于多帧匹配特征构建的成本量。它基于静态场景假设明确地推理几何信息,但这很容易受到动态对象和遮挡的影响。DynamicDepth试图解决动态场景的问题,但在推理时依赖于动态对象的深度先验和分割掩码。为了规避这些方法在多帧推理中遇到的动态对象问题,我们回归到了传统的范式,即直接聚合多帧特征。然而,不对齐的直接特征融合会损害时间表示的学习,因为相邻帧中相同位置的特征嵌入通常是不相关的,这使得模型难以利用多帧之间的相关性。因此,我们认为在聚合之前进行特征对齐是一个合理且必要的步骤。正如在视频超分辨率和视频帧插值等视频增强任务中所揭示的那样,帧间特征对齐可以通过光流扭曲来实现。这启发我们采用基于光流的视频帧插值(VFI)模型来同时进行时间增强并为特征对齐提供明确的对应关系。此外,VFI模型可以推理出相邻帧之间的遮挡掩码,有助于缓解特征融合中的帧间遮挡问题。基于上述分析,我们设计了一个VFI辅助的多帧融合模块,用于多帧深度估计。
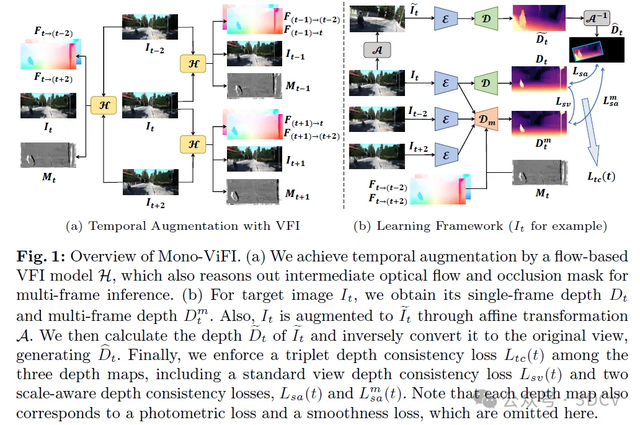
最后,我们构建了一个统一的框架,用于双向连接单帧和多帧深度。直接的方式是通过深度一致性,这通常用于自监督单目深度估计中的几何正则化或知识蒸馏。ManyDepth从单帧模型向多帧模型进行了单向蒸馏。DynamicDepth将其扩展为双向相互增强,但仅限于运动物体区域。与之不同的是,我们的框架在整个图像上应用了双向一致性。对于原始目标图像,我们在其来自单帧和多帧模型的两个深度图之间使用了标准视图深度一致性(SVDC)损失。我们还包含了经典的数据增强策略,归类为空间增强。具体来说,我们将调整大小-裁剪与图像旋转相结合,形成了一种通用的仿射变换。然后,我们给出了使用相对物体大小线索进行仿射增强视图合成的校正相机姿态公式。对于来自增强目标视图的深度图,我们分别在它和上述两个标准视图深度之间施加了两个尺度感知深度一致性(SADC)损失。SADC源于相对大小线索,该线索假设当图像按某一因子放大时,深度会按相同的因子减小。它引导深度模型从场景变化中学习一致的几何尺度关系。SVDC损失和两个SADC损失统称为三元深度一致性损失。我们的框架被命名为Mono-ViFI,因为自监督单目深度估计在很大程度上得益于视频帧插值。据我们所知,我们是第一个利用视频帧插值来改进自监督单目深度估计的研究。
下面一起来阅读一下这项工作~
1. 论文信息
标题:Mono-ViFI: A Unified Learning Framework for Self-supervised Single- and Multi-frame Monocular Depth Estimation
作者:Jinfeng Liu, Lingtong Kong, Bo Li, Zerong Wang, Hong Gu, Jinwei Chen
机构:vivo
原文链接:https://arxiv.org/abs/2407.14126
代码链接:https://github.com/LiuJF1226/Mono-ViFI
2. 摘要
自监督单目深度估计因其能够从对深度标注的依赖中解脱训练过程而备受关注。在单目视频训练的情况下,最近的方法仅对现有的相机视角进行视图合成,导致指导不足。为了解决这个问题,我们尝试通过基于流的视频帧插值(VFI)来合成更多的虚拟相机视角,这被称为时间增强。对于多帧推断,为了避开ManyDepth等基于显式几何的方法遇到的运动物体问题,我们回归到特征融合范式,并设计了一个VFI辅助的多帧融合模块,利用基于流的VFI模型获得的运动和遮挡信息来对齐和聚合多帧特征。最后,我们构建了一个统一的自监督学习框架,名为Mono-ViFI,以双向连接单帧和多帧深度。在该框架中,通过图像仿射变换进行空间数据增强以增加数据多样性,同时采用三重深度一致性损失进行正则化。单帧和多帧模型可以共享权重,这使得我们的框架紧凑且内存效率高。广泛的实验表明,我们的方法能够显著改善当前先进的架构。源代码可在https://github.com/LiuJF1226/Mono-ViFI获取。
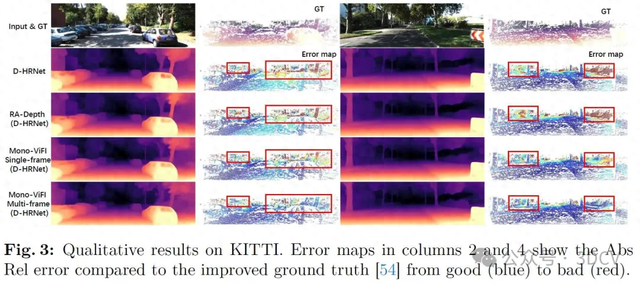
3. 效果展示
4. 主要贡献
我们提出了Mono-ViFI,这是一个统一的学习框架,用于双向连接自监督的单帧和多帧MDE。在Mono-ViFI中,单帧和多帧模型可以共享权重,使得统一框架更加紧凑且内存效率高。
我们通过基于流的VFI进行时间增强,并开发了一种新颖的VFI辅助多帧融合模块,该模块利用基于流的VFI模型中的运动和遮挡信息来改善多帧深度估计。
我们将图像仿射变换作为空间增强,并结合三元组深度一致性损失进行正则化和提炼。
实验表明,Mono-ViFI可以达到最先进的性能。此外,我们的方法与架构设计正交,允许当前先进的深度网络通过无缝集成Mono-ViFI得到进一步改进。
5. 基本原理是啥?
在本文中,我们提出了一种新颖的单目视频帧插值辅助(Mono-ViFI)方法,用于自监督单目训练,该方法将单帧和多帧深度模型双向连接到一个统一的学习框架中。我们利用基于流的视频帧插值(VFI)模型引入了时间增强,并开发了VFI辅助的多帧融合深度估计方法。此外,我们的框架还结合了空间数据增强和三重深度一致性损失。最后,我们给出了总体训练目标。Mono-ViFI的概述如图1所示。
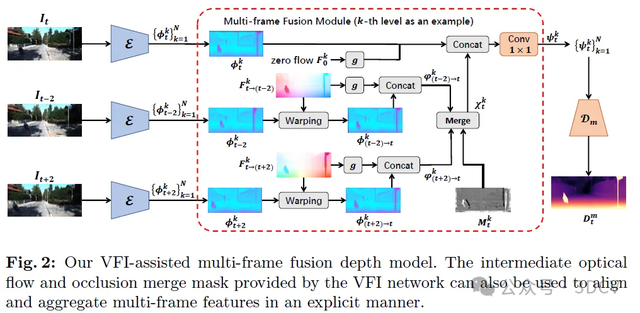
除了时间增强之外,我们使用的VFI模型还可以提供其他帧间信息,如光流和遮挡合并掩码。这使我们能够设计一种新颖的VFI辅助多帧融合模块,用于多帧深度预测,如图2所示。该融合模块由两部分组成,即运动感知特征对齐(MAFA)和遮挡缓解特征融合(OAFF)。以原始三重帧{It−2, It, It+2}为例,我们实现了VFI模型的前向过程,以插值等式(9)中{It−2, It+2}的中间位置t,生成中间光流Ft→(t−2)和Ft→(t+2)以及合并掩码Mt,用于对齐和聚合多帧特征。
6. 实验结果
KITTI数据集结果。在640×192分辨率下,使用原始真实值和改进后的真实值在KITTI数据集上进行定量比较的结果分别列于表1和表2中。显然,我们的方法结合D-HRNet可以实现最先进的性能。此外,我们的Mono-ViFI在不增加模型复杂度的情况下,为三种深度架构带来了显著的性能提升(参见由虚线分隔的各个小节)。尽管在表1中,Mono-ViFI(D-HRNet)与RA-Depth在单帧模式下的差异很小,但在表2中使用改进后的真实值时,差异更为显著。对于多帧推理,使用ResNet18的Mono-ViFI在某些指标(包括Sq Rel、RMSE、RMSE log、δ2和δ3)上已经表现出优于ManyDepth和DynamicDepth的优势。当更换为D-HRNet主干网络时,提出的Mono-ViFI可以完全超越它们。尽管我们的模型在预测单个帧时具有更多的乘加计算(MACs),但在处理长视频序列时,每帧的平均MACs是可比较的。


7. 总结 & 未来工作
总之,本文提出了一种新颖的自监督学习框架,名为Mono-ViFI,以统一的方式将单帧和多帧深度估计双向连接。首先,采用基于流的视频帧插值(VFI)模型进行时间增强。然后,我们提出了一个VFI辅助的多帧融合模块,以获得更精确的多帧深度。此外,将调整大小-裁剪扩展到仿射变换,作为空间增强,以丰富数据多样性。最后,我们开发了一种新的三元组深度一致性损失,以实现更好的正则化。实验表明,我们的方法能够在更大程度上释放现有深度模型的潜力,同时不会增加推理复杂度。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3DCV技术交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:具身智能、Mamba、CV、大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、BEV感知、Occupancy、目标跟踪、端到端自动驾驶等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。