最近和前同事聊天,他被裁后意外进了一家AI公司做算法,工资看似涨了很多,但工作时长也比原来每周多了十几个小时,而且公司做的是跨境电商营销增长业务,通过AI去精准获客,业绩压力非常之大。
他说现在出海获客不再是简单的做SEO、内容推广了,而是要做AI引擎优化(AEO),让你的内容被AI更多的收录,从而获得天然曝光,还需要通过分析Youtube、Reddit等平台用户偏好去精准化营销,这些都需要实时采集大量的数据用于模型训练。

聊到大模型,他说他现在在做一个舆情监测的多模态大模型,专门对Youtube进行采集训练,作为世界上最大的媒体平台,自然有最丰富、最及时、最真实的用户内容,但是数据采集是个难题,因为现在的自动化爬虫多到令人发指,Youtube的反爬机制异常严格。
类似于yt-dlp这样的开源爬虫小工具,可能采集少量视频内容时还可以,但它是在有限的IP资源上运行的单点脚本,所以一旦规模化就很容易遇到HTTP 429 (Too Many Requests) 错误。
我突然想之前用过的亮数据网页抓取API,类似封装好的数据采集流水线,能自动处理各种反爬技术,或许能支持Youtube的大数据采集,而且不需要花时间去维护,很适合他的现在的需求。
https://get.brightdata.com/webscra
亮数据有3个优势,能支持高并发的规模化数据采集任务。
1、庞大的IP网络: 亮数据拥有超过1.5 亿个真实用户 IP 地址,覆盖全球195 个国家和地区。这样规模的IP池确保了地理位置定位的精确性和反封锁策略的弹性。
2、网页解锁能力:亮数据开发了一款专门为解决复杂网站反爬虫挑战而设计的网页解锁API,用来处理人机验证、Cookie配置等。它通过AI算法自动执行一系列复杂的解锁任务,你不需要任何手动配置。
3、抓取浏览器:这是专门用于网页抓取的远程浏览器, 和普通浏览器类似,可以模拟高级用户交互,比如如点击、滚动、登录),它的优势是能通过单一 API接口提供无限并发会话和工作负载,不管多大数据体量,都能支撑,比本地或者其他服务器更加稳定。
亮数据还有一个优势是,只有数据采集成功了才付费,相比传统的计费模式,像是按带宽或按请求次数计费,亮数据更加合理,因为网页结构更新迭代很快、反爬虫机制实时升级,采集请求失败(返回 429/403)是常态,按成功付费是成本最低的。

另外,亮数据在底层保证了数据采集的安全性,它会严格遵守全球主要的隐私法规,包括欧盟的《通用数据保护条例》(GDPR)和《加州消费者隐私法案》(CCPA),所以你不需要担心爬虫会违规。
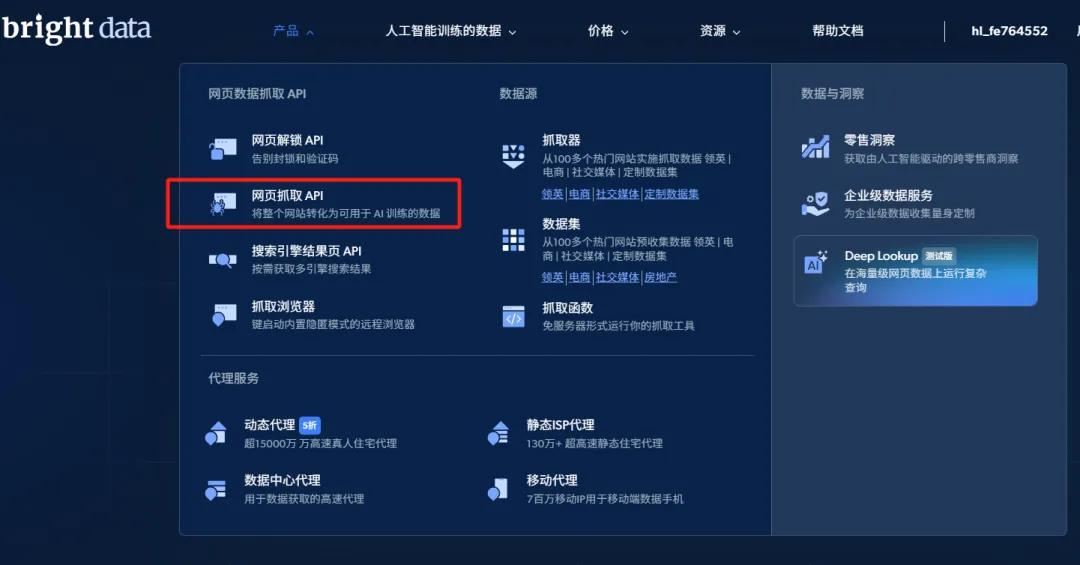
我让这位同事去亮数据官网找到了专门用于Youtube的网页抓取API,能直接通过requests访问并获取相应的视频、评论、互动等数据。

下面讲解下具体的流程。
首先需要注册亮数据并登录用户控制面板,它会送你试用额度。
然后进入Web Scrapers菜单,这是用来配置网页采集API的功能区,Youtube采集模板就在这里。

接着进入Youtube采集页面,里面有各种接口,包括按url采集视频信息及评论,或者按搜索关键词来采集。

先选择“Youtube - Videos posts - collect by URL”,测试下使用Python requests调用API来采集视频信息。

进入到配置页面,你需要配置API请求构建器,一般选择url导入格式为CSV、编程语言为Python即可。

url csv格式如下,里面是要采集的Youtube视频链接。

这里要把url csv文件地址改成你的本地文件地址,然后把配置好的Python代码复制到Vscode编辑器里,就能开始下载数据了。

数据采集任务开始后,代码会返回一个snapshot_id,代表采集的数据会保存在亮数据的数据库里,通过特定的snapshot_id可以调用,这一般需要等待几秒钟。
下载好后,就可以去提取数据,我把数据转换为pandas格式,方便查看。
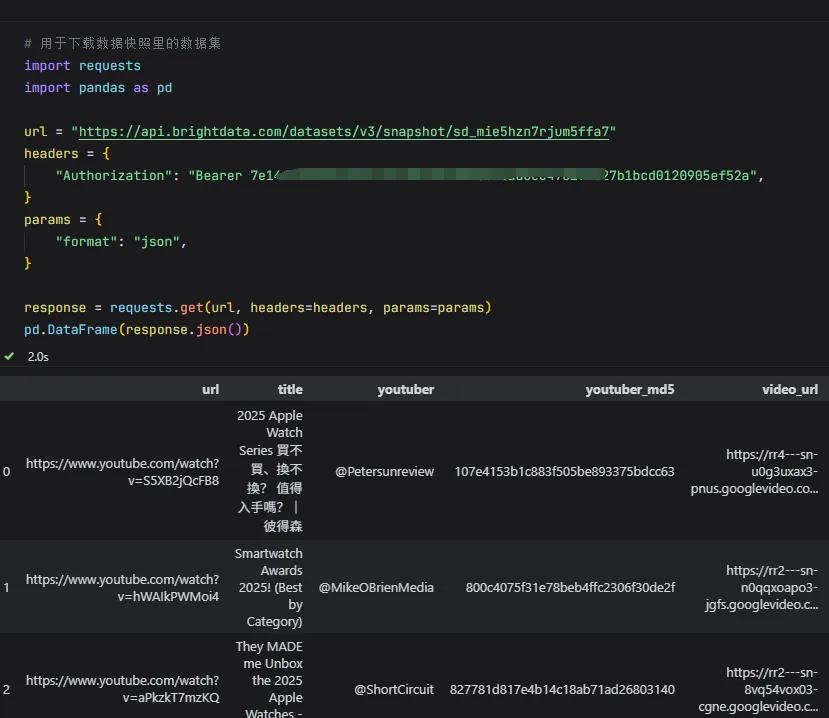
这样咱们就成功采集了3条Youtube视频的数据详情,包括url、title、youtuber、video_length、views等43个详细字段。
还可以通过Youtube - Comments - collect by URL来下载视频的评论数据,调用方法和上面类似。
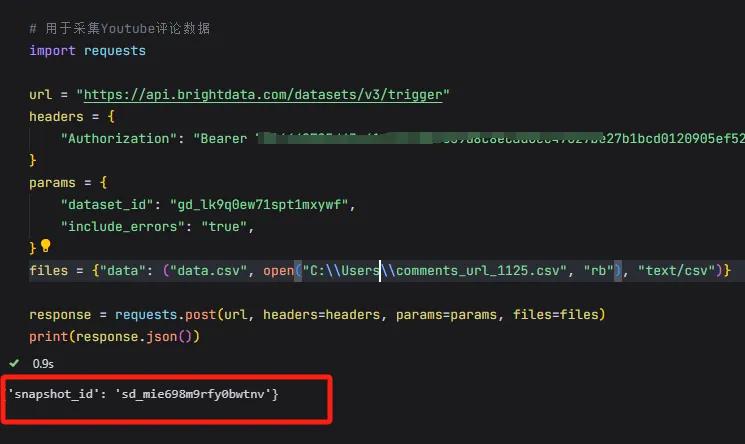
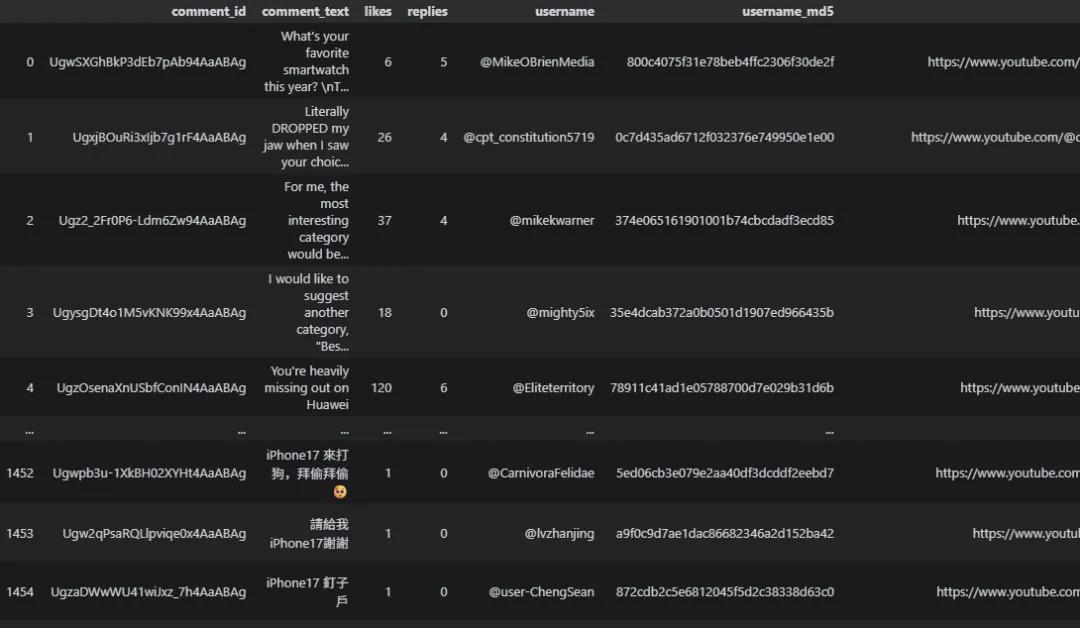
评论数据包含comment_id、comment_text、likes、replies等13个字段,非常详细。
同理,也可以按照关键词搜索来采集Youtube视频数据,比如我们搜索smart phone、smart watch、wireless headphones这三个关键词,结果会返回指定数量和内容的视频信息。
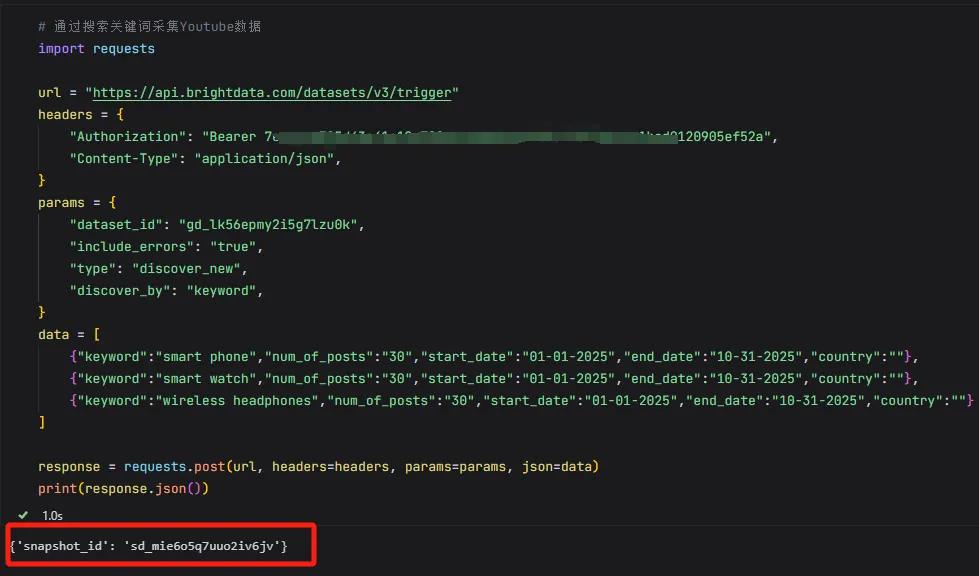
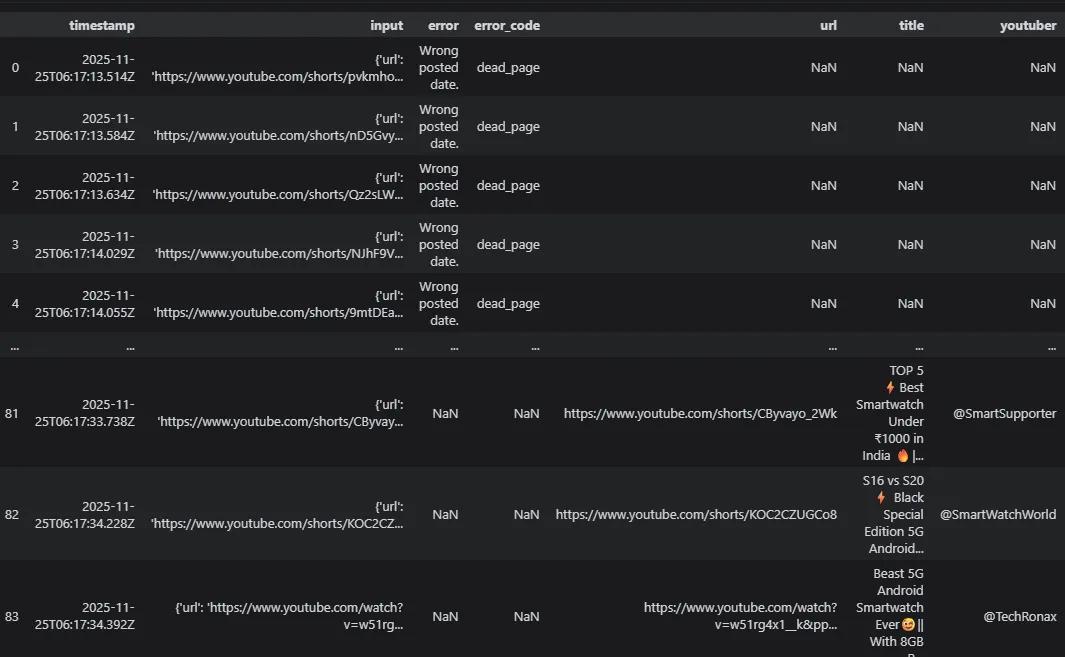
通过以上几个案例,你会发现亮数据API把爬虫的复杂过程打包成一个黑盒子,你只需要提交url或者关键词,它就会给你返回数据,不需要担心任何IP限制、人机验证等反爬机制。
如果觉得写代码比较麻烦,你可以尝试将以上的采集API封装到web应用里,通过可视化的界面来采集、分析Youtube数据。
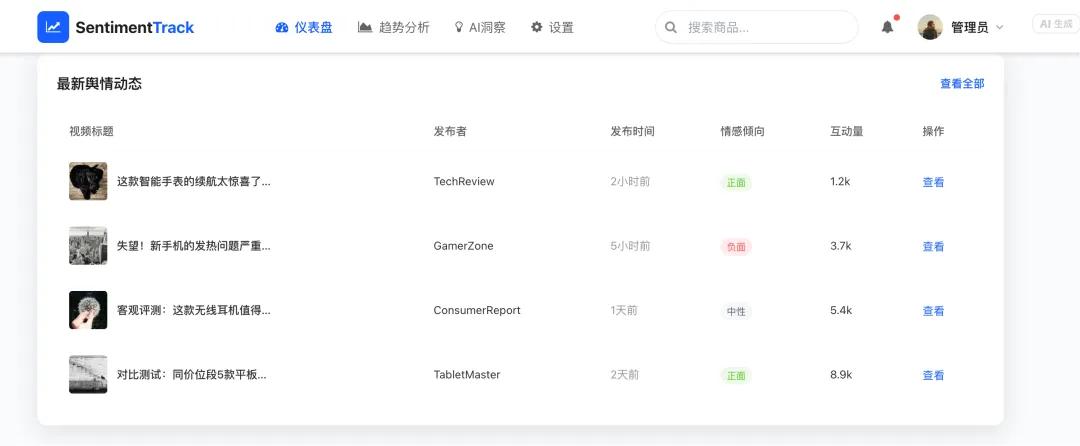
以下是我基于streamlit搭建的应用,所有功能都可以正常使用,且流畅度不错。
1、支持数据采集操作
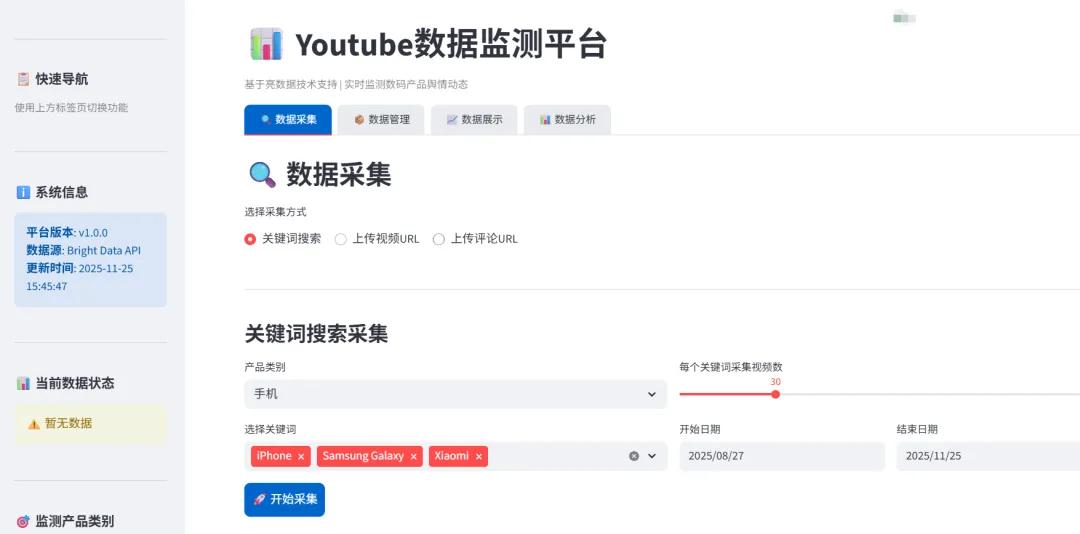
2、进行数据管理,调用数据快照

3、对采集的数据进行统计展示
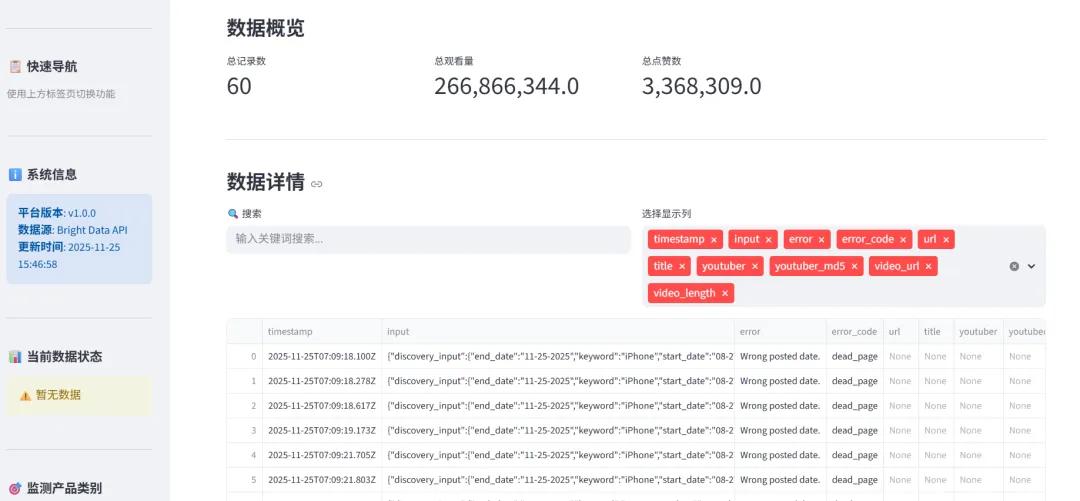
4、进行可视化分析

这样就搭建了一个企业级的舆情监测平台,基于亮数据API来采集数据,稳定性靠谱,省去了很多网页处理、IP配置的麻烦。
上面列举的这些案例纯属个人爱好研究,没有任何商用场景,且数据也是小批量试用,产品demo解释权归个人所有。