在大模型和生成式AI模型大规模发达的今天,利用大模型生成音乐也是其中一个重要的发展方向。今天我们就介绍一个这样的音乐生成模型ACE-Step,可基于关键字和歌词生成歌曲;基于歌曲生成伴奏等等功能。
概述ACE-Step的目的是建立一个基础人工智能音乐模型架构,可实现一个快速、通用、高效且灵活的架构,使其能够轻松地实现子任务训练,为开发强大的工具铺平了道路,这些工具可以无缝集成到音乐艺术家、制作人和内容创作者的创意工作流程中。

现有的基于LLM的音乐生成模型,比如Yue、SongGen等虽然在歌词对齐方面表现出色,但推理速度慢且存在结构性问题。基于扩散模型,比如DiffRhythm虽然能够实现更快的合成速度,但通常缺乏较长段落的结构连贯性。为了克服这些现有模型的局限性,ACE-Step通过统一的架构设计实现了最佳性能,在生成速度、音乐连贯性和可控性之间多方面的改善。
ACE-Step通过diffusion生成与Sana的深度压缩自动编码器 (DCAE) 和轻量级线性变换器相结合,并利用MERT和m-hubert在训练过程中对齐语义表示 (REPA),从而实现快速收敛。整体结构图如下:
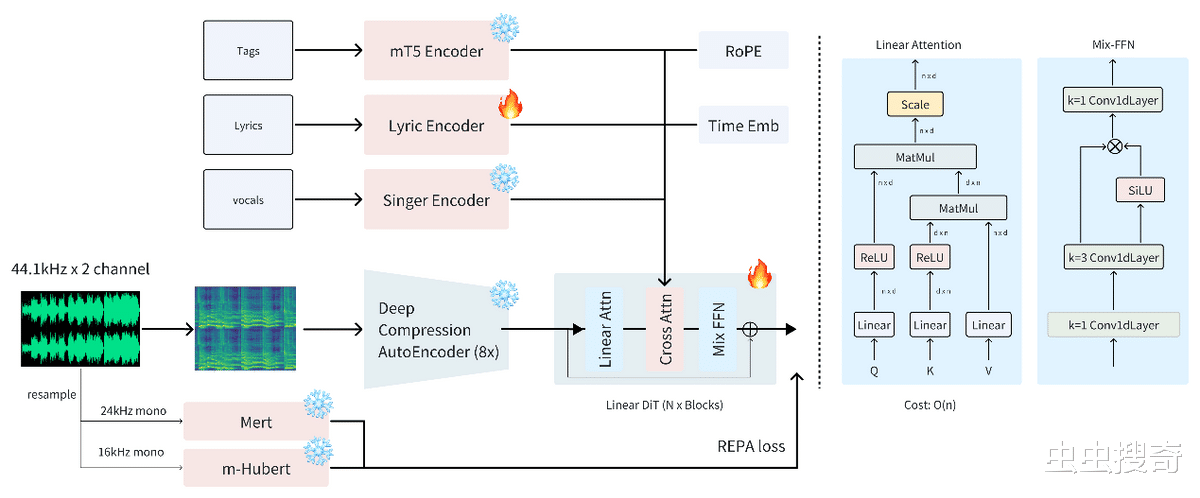
ACE-Step可实现在A100 GPU上仅需20秒即可合成一首4分钟的音乐。这比基于LLM的基准快15倍。同时还在旋律、和声和节奏指标上实现了完美的连贯性和歌词对齐。对不同硬件条件下的其系能表现得对比基准测试:

多风格和流派:
支持所有主流音乐风格,提供多种描述格式,包括短标签、描述性文字或用例场景。可使用适当的乐器和风格创作不同类型的音乐。
多国支持:
支持多达19国语言,其中对US英语、CN中文、RU俄语、ES西班牙语、JP日语、DE德语、FR法语、PT葡萄牙语、IT意大利语和KR韩语等大众语言的支持最佳。
器乐风格方面:
支持不同流派和风格的各种器乐生成。
能够为每种乐器制作具有适当音色和表现力的逼真的乐器曲目。
可以使用多种乐器进行复杂的编曲,同时保持音乐的连贯性。
发声技巧:
可高质量地呈现各种声音风格和技巧;支持不同的声音表达,包括各种歌唱技巧和风格。
变体生成:
使用无需训练、推理时间优化技术实现;
流匹配模型生成初始噪声,然后使用trigFlow的噪声公式添加额外的高斯噪声;
可调节原始初始噪声和新高斯噪声之间的混合比,以控制变化程度。
重新修饰:
通过在目标音频输入中添加噪声并在ODE过程中应用掩码约束来实现。
当输入条件与原始生成不同时,只能修改特定方面,同时保留其余方面。
可以与变体生成技术结合,在风格、歌词或人声上创造局部变化。
歌词编辑:
创新性地运用流程编辑技术,实现歌词的局部修改,同时保留旋律、人声和伴奏。
可与生成的内容和上传的音频配合使用,大大增强了创作可能性。
功能组成ACE-Step主要有两个大的功能应用构成,后续会陆续推出Rap机,StemGen和唱歌伴奏等功能。
Lyric2Vocal(LoRA)基于对纯语音数据进行微调LoRA,可直接从歌词生成语音样本。
提供众多实用应用,如人声演示、指南曲目、歌曲创作辅助和人声编排实验。
提供一种快速测试歌词演唱效果的方法,帮助歌曲创作者更快地进行迭代。
Text2Samples (LoRA)与Lyric2Vocal类似,但针对纯乐器和样本数据进行了微调。
能够根据文本描述生成概念音乐制作样本。
有助于快速创建乐器循环、音效和音乐元素以供制作。
本地部署ACE-Step是一个完全开源的大模型,在硬件算力支持的情况下可实现本地私有化部署。如果只是想体验一下的同学,可以通过huggingface的在线示例:
huggingface.co/spaces/ACE-Step/ACE-Step

ACE-Step是一个python框架,需要Python环境以及conda和venv来部署多Python环境避免版本冲突问题。
先创建一个Python3.10的环境(conda为例)并激活:
conda create -n ace_step python=3.10 -y
conda activate ace_step
安装项目依赖组件:
pip install -r requirements.txt
然后可以启动该框架
python app.py
启动时候可以自定义监听端口,根目录等,更多参数可以按官方详细文档:
python app.py --checkpoint_path /path/to/checkpoint --port 7865 --device_id 0 --share true --bf16 true
使用ACE-Step界面提供了几个页签,用于不同的音乐生成和编辑任务:
Text2Music输入字段:
标签:输入描述性标签、类型或场景描述(以逗号分隔)。
歌词:输入带有结构标签的歌词,例如 [verse]、[chorus] 和 [bridge]。
音频时长:设置生成的音频所需的时长(-1 为随机)。
设置项目:
基本设置:调整推理步骤、指导尺度和种子
高级设置:微调调度程序类型、CFG类型、ERG设置等
生成按钮(Generation):单击“生成”即可根据您的输入创建音乐
音乐修饰使用不同的种子重新生成略有变化的音乐。
调整差异以控制重拍与原始拍摄的差异程度。
重新绘制选择性地重新生成音乐的特定部分。
指定重新绘制部分的开始和结束时间。
选择源音频(text2music 输出、上次重绘或上传)。
编辑通过更改标签或歌词来修改现有音乐。
在“only_lyrics”模式(保留旋律)或“remix”模式(改变旋律)之间进行选择。
调整编辑参数来控制保留原始内容的程度。
扩展在现有乐曲的开头或结尾添加音乐。
指定左右延伸长度。
选择要扩展的源音频。

首先要本地部署安装部分所述运行环境。
如果计划训练LoRA模型,则需要额外安装PEFT库:
pip install peft
提前准备Huggingface格式的数据集。数据集需要包含以下必须字段:
keys:每个音频样本的唯一标识符
tags:描述性标签列表(例如, ["pop", "rock"])
norm_lyrics:规范化的歌词文本
可选字段:
speaker_emb_path:扬声器嵌入文件的路径(如果不可用,则使用空字符串)
recaption:各种格式的附加标签描述。
一个典型数据格式:
{
"keys": "1ce52937-cd1d-456f-967d-0f1072fcbb58",
"tags": ["pop", "acoustic", "ballad", "romantic", "emotional"],
"speaker_emb_path": "",
"norm_lyrics": "I love you, I love you, I love you",
"recaption": {
"simplified": "pop",
"expanded": "pop, acoustic, ballad, romantic, emotional",
"descriptive": "The sound is soft and gentle, like a tender breeze on a quiet evening. It's soothing and full of longing.",
"use_cases": "Suitable for background music in romantic films or during intimate moments.",
"analysis": "pop, ballad, piano, guitar, slow tempo, romantic, emotional"
}
}
基础模型训练可使用trainer命令对基础模型进行训练,相关参数请参考官方详细文档:
python trainer.py --dataset_path "path/to/your/dataset" --checkpoint_dir "path/to/base/checkpoint" --exp_name "your_experiment_name"
LoRA训练LoRA训练,需要额外提供一个LoRA配置文件,其配置示例如下(lora_config.json):
{
"r": 16,
"lora_alpha": 32,
"target_modules": [
"speaker_embedder",
"linear_q",
"linear_k",
"linear_v",
"to_q",
"to_k",
"to_v",
"to_out.0"
]
}
然后也使用trainer命令进行具体操作
python trainer.py --dataset_path "path/to/your/dataset" --checkpoint_dir "path/to/base/checkpoint" --lora_config_path "path/to/lora_config.json" --exp_name "your_lora_experiment"
总结ACE-Step是一个非常有意思的项目,是大模型在音乐方面的成功尝试,根据项目中作者名字推测,其作者可能几个中国人。项目私有化部署、训练和调整都非常简单,可适合音乐人,爱好者使用提高生产力,也适合AI工程师尝试找寻灵感。吃瓜群众也可以去在线试试玩玩,说不定哪天也可以用的上。