
分组处理数据,你只会使用 pandas? 那你就错了。其实不借助第三方库,我们也可以轻松实现数据分组。
今天内容:
使用字典做数据分组使用 itertools 的 groupby 实现数据分组如何封装函数,使其更具通用性分组字典是python中非常常用的一种数据结构。我们可以用字典来实现数据分组。
比如,我们有这样一个列表:
people_list = [ {'姓名': '张三', '性别': '男', '年龄': '25'}, {'姓名': '李四', '性别': '女', '年龄': '30'}, {'姓名': '王五', '性别': '男', '年龄': '22'}, {'姓名': '赵六', '性别': '女', '年龄': '28'}, {'姓名': '周六', '性别': '女', '年龄': '26'}, {'姓名': '陈七', '性别': '男', '年龄': '24'}, {'姓名': '杨八', '性别': '女', '年龄': '27'},]我们想按照性别分组,统计平级年龄和人数。
使用字典的实现方式:
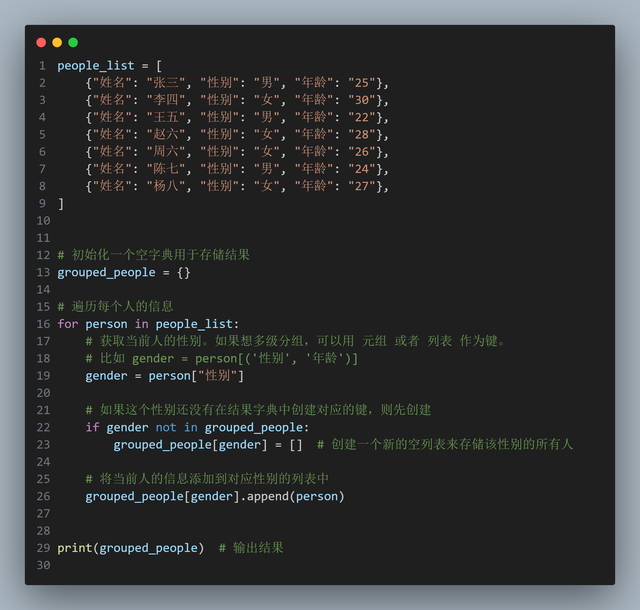
结果:
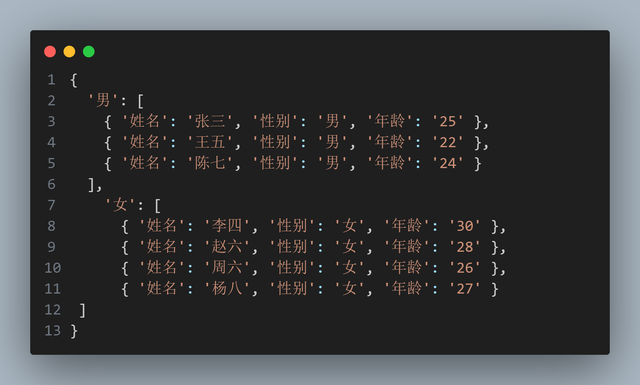
现在结果字典有两项数据(男性和女性),分别对应着两个列表(里面就是该性别的数据,是一个个字典)。
上面代码,可以使用 defaultdict 改进:
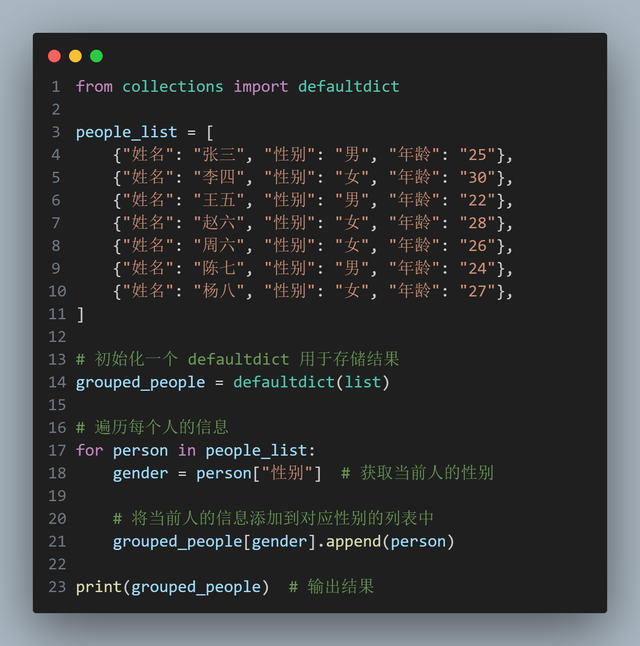 行21: 当访问一个不存在的键时,defaultdict 会自动创建一个空列表,并返回它。
行21: 当访问一个不存在的键时,defaultdict 会自动创建一个空列表,并返回它。如果不想使用字典,而是想使用 itertools 的 groupby 实现,可以这样:
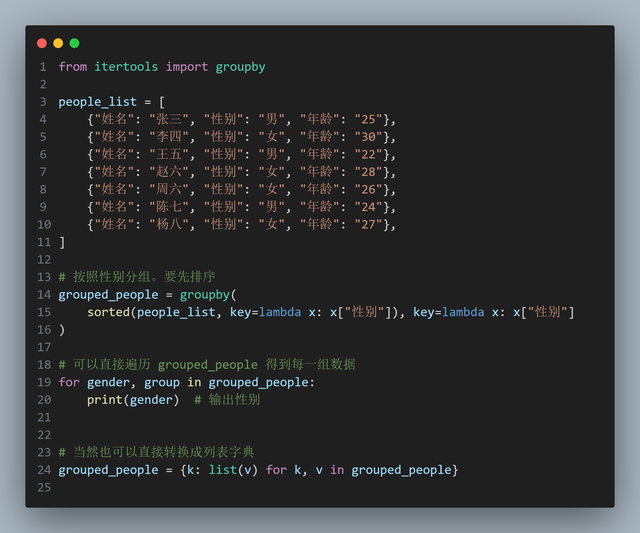 行15:分组前对数据做排序才行封装函数
行15:分组前对数据做排序才行封装函数现在已经对数据进行了分组,所谓的分组统计(平级年龄和人数),只不过是对每个性别的列表进行遍历,统计每个人的年龄,然后求和。
但统计处理多种多样,为此我们可以封装成通用的函数。
假设封装的函数叫 group_by ,看看我们期待的使用方式:
 行9:参数 by :指定分组的字段,也可以指定多个字段,比如 by=["性别", "年龄"] 。行9:参数 aggregate :指定聚合函数。
行9:参数 by :指定分组的字段,也可以指定多个字段,比如 by=["性别", "年龄"] 。行9:参数 aggregate :指定聚合函数。确定了使用方式,那么我们可以开始封装函数:
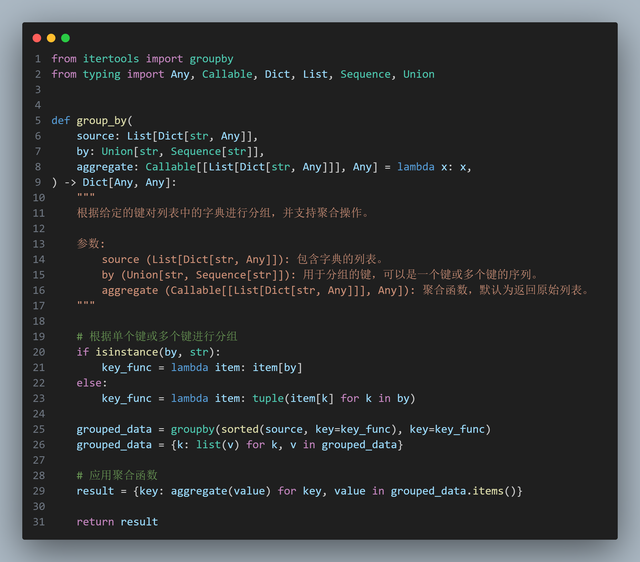 行20-23:让参数 by 支持单个字符串或多列分组行29:再次遍历分组的结果,然后应用聚合函数
行20-23:让参数 by 支持单个字符串或多列分组行29:再次遍历分组的结果,然后应用聚合函数转发、关注我,私信"itertools",获得本期源码和数据。
不要忘记一键三连。你的点赞、收藏、关注,是我创作的动力。