
任何业务只要是上到了一定的量级,那将就变得很复杂,并且可能不仅仅是复杂能描述的清楚,交易系统也不例外,并且交易系统作为电商系统中,核心中的核心,尤为重要,作为架构师,我们就是在架构的稳定性、用户体验以及成本之间寻找平衡点。
交易系统面临的四大挑战那么在千万级的电商的场景下,交易系统面临哪些挑战呢,又该如何去解?
挑战一:单热点的库存问题,尤其是现在一些比如一些直播的场景下,大V的秒杀层出不穷,给库存带来了非常大的挑战性。
挑战二:下单与其他业务的一致性问题,比如下单与库存的扣减一致性问题,下单与券的一致性问题等等,交易作为一个连接枢纽,一致性问题在架构设计中是必须考虑的事情
挑战三、依赖多,编排复杂,稳定性保障问题,说到底,交易更像是一个业务编排系统,把上游的商品、店铺、架构、券等信息进行组装,然后最后生成订单,生成订单的数据都是依赖于其他系统,因此注定它将成为依赖多,编排复杂的系统,那么它的稳定性又该如何保障?
挑战四、订单信息承载多,在架构层面如何保证它在模型设计方面保持可扩展性,电商业务也是不断向前的发展,随时都会衍生出新的业务需求,那么交易订单模型和数据访问接口诉求也会随着业务的变化额变化。
大体上,整个交易系统所面临的就是这四大挑战:单热点问题、一致性问题、稳定性问题以及可扩展性问题。
那么如何去解呢?
问题一、单热点的库存问题常见的库存扣减方式一般就以下这几种
库存存储方案选型
优点
缺点
基于数据库
数据可靠性要高,主从切换可以做到不丢数据
单 key 写入能力远低于 Redis,读场景需要通过搭建从库来支撑读能力,成本较高
基于Redis
能支持超高的单 key 查询和扣减、性能高、存储成本低
在主从切换、主备切换时存在数据丢失的可能
实时扣减基于Redis,异步扣减基于数据库,并记录库存流水,用于后续核对
实时扣减能保证查询和扣减性能。成本较全部使用数据库而然会低同步异步记录库存流水和扣减,在一定程度上保证了数据丢失的风险
架构的复杂度较第一种和第二种更高。
极端情况,会存在着一定数据丢失或者是延迟的可能性
第一种:纯基于数据库,这种方案很难用于这种千万级的体量上面来,因为成本太高,并且单热点商品形成的行锁,很容易将数据库搞垮,当然也有一些大厂基于MYSQL做了大量优化,比如SQL合并,算子合并,锁冲突优化等,使其MYSQL的单热点的更新性能大幅提升,这种情况可以忽略,但是如果是作为非大厂,我们没有这种技术储备,用这种纯数据库的方案,不太现实。
第二种,纯基于Redis的方式,这种方案性能基本上没啥大问题,一般能扛住10w/s的高热点并发,就算是更大的并发,通过热点商品库存通过拆key,前置服务排队限流,也基本能扛住,但是会存在着丢数据的风险,当然现在的云服务,很多Redis都是做了三副本的,数据丢失的可能性也比较低,一般公司采用这种方案,基本上就能满足要求了。
第三种,实时扣减基于Redis,然后再通过异步的方式去记录扣减库存流水,以及进行数据库层面的扣减,这种方案能保证前端对于实时扣减和查询的高性能要求,又能在一定程度上保证了数据丢失的风险,也能基于数据库的库存流水数据去做一些核对动作,提前识别出库存扣减问题,避免因为系统bug,导致很大的库存扣减异常的故障发生,但总的来说,架构的复杂度较高,适合公司发展到一定阶段,对稳定性提出一定要求时采用。
问题二、下单与其他业务一致性问题说到数据一致性问题,可能大家最直观的想法就是是不是要使用到分布式事务,对于这种大流量的交易系统来说使用分布式事务,我想说的是不太可能的,一定是基于数据的最终一致性去解决这个问题。
拿扣减库存来说,下单时我们会同步去扣减库存,如果扣减完库存,下单失败了,会去异步回滚库存,这样就能保证库存的数据与下单数据的最终一致性,当然比如券的扣减也是同样的方式去实现的。
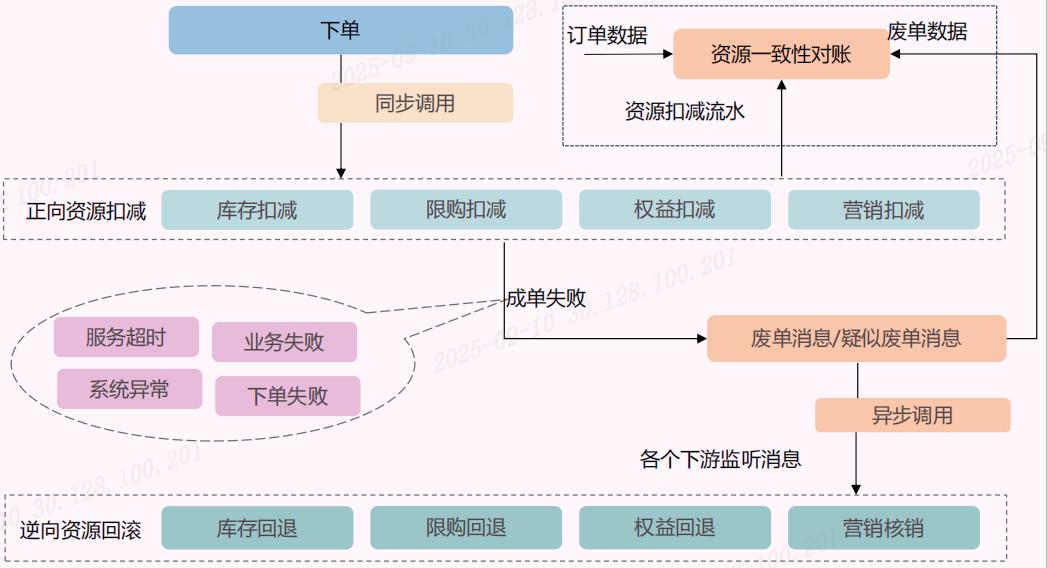
真的别用什么分布式事务,对于这样的系统简直就是一个灾难。
问题三、依赖多、编排复杂稳定性保障交易下单动不动会依赖几十个业务上下游,涉及到非常多方法,想要它灵活起来,就必须将它的业务抽象成为合理单位的原子指令,然后再基于编排的框架,将这些进行编排起来,形成完整的、可用的交易业务,和现在的AI编排框架有的类似,比如Coze。
针对于稳定性这块,总体来说要做以下事情
一、服务的核心分级,哪些是核心原子服务,是一定不要少的,哪些是次核心的,哪些是次次核心的,如果不存在这个节点,将出现什么影响,最终会形成以下表格
原子服务
重要程度
是否可降级
降级策略
降级后的业务影响
扣减库存
核心
可降级
手动调整参数
库存超卖
一定要有这样的一个表格,这是对自己的服务资产进行梳理,做到心中有数,真正线上出问题了也不就不在手忙脚乱的
二、依赖的加固,依赖的加固怎么讲呢?大家是不是都使用到过比如dubbo 、http连接池的超时时间?就是要盘点所有的外部依赖(含中间件),它们的超时时间设计的是否合理,线程池的核心参数设置的是否合理,限流熔断的策略设置的是否合理,要做到真正意义上的“打不死,拖不挂”,如果这些东西,没有设置正确的值,就很容易引起服务之间的雪崩效应,最终引起一系列的连锁反应
三、故障应急,平常多去推敲可能出现问题的地方,建立完备的异常数据追踪、快速修复工具箱,实现快速的业务止血和恢复,避免出问题了,手足无措,不用吝啬在这种地方投入人力和时间,这就是好像我们国防建设一样,宁可不用,但不能没有是同一个道理。
四、故障演练->预案沉淀,光说不练假把式,通过平常的故障演练,发现薄弱的环节,不断的去完善和丰富我们的故障响应处理SOP,做到真正出问题时,要找谁,谁决策,谁处理,怎么处理,免得乱成一锅粥。
交易系统在技术组件慢慢趋于稳定时,往往很大一部分精力都是投入到稳定性建设,确保少出故障,故障出现时能自动感知,故障出现后能快速响应,降级止血恢复。
问题四、订单信息承载多,在架构层面如何保证它在模型设计方面保持可扩展性订单作为交易最核心的模型,记录了各个域的关键数据,随着电商业务的不断发展,订单场景、服务对象、履约模式、优惠信息等等都各有不同,那么交易订单模型就要求要能够快速支撑各种业务的灵活性,总的思路就是:公用结构化+扩展非结构化,分清哪些是订单的公用模型,哪些是订单的扩展模型,公用模型采用结构化数据存储,而扩展模型采用非结构化存储。
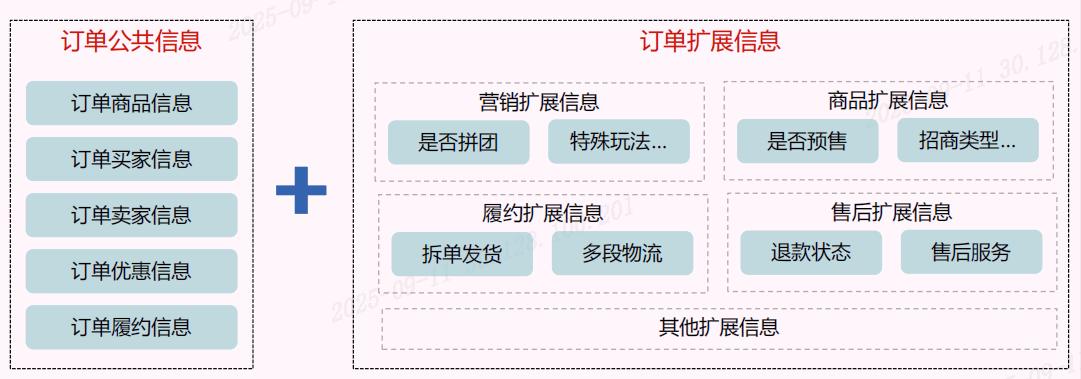
对于扩展模型也要避免把所有的业务类型的数据存储在一个非结构化的数据里面,因为这样做就会导致数据无序扩张,会很乱,同时数据库的字段也未必后面能存的下。
公用模型采用结构化存储,这个好理解,就是采用数据表的列,而扩展模型采用非结构化存储,那么这个数据格式可能大多数的情况都是采用JSON格式,那么这个数据的随意性就比较大。因此还需要有一套能够有效管控的机制,保障它多而不乱。
一、建议针对于不同域所用的信息进行分类,比如优惠信息的扩展信息放到优惠扩展里面,履约所需要的扩展信息放到履约扩展里面。
二、建立好字段使用含义、业务使用规范、长度约束、申请流程等,最好能在代码中直接管控,避免人为导致的问题出现
三、对于扩展字段尽量使用JSON这种通用的,大家很好理解的协议格式,其他下游组件也能更容易兼容,避免使用自定义二进制码,XML这种格式。
写在最后大体上的交易系统就是这样的,当然还有一些很细的一些问题点,比如最终一致性如何做?热点商品拆Key要注意那些细节?扩展模型如何进行管控等等,有些细的问题点应该已经出现在我之前的文章里,有些问题点可能没有,后面有时间在整理。