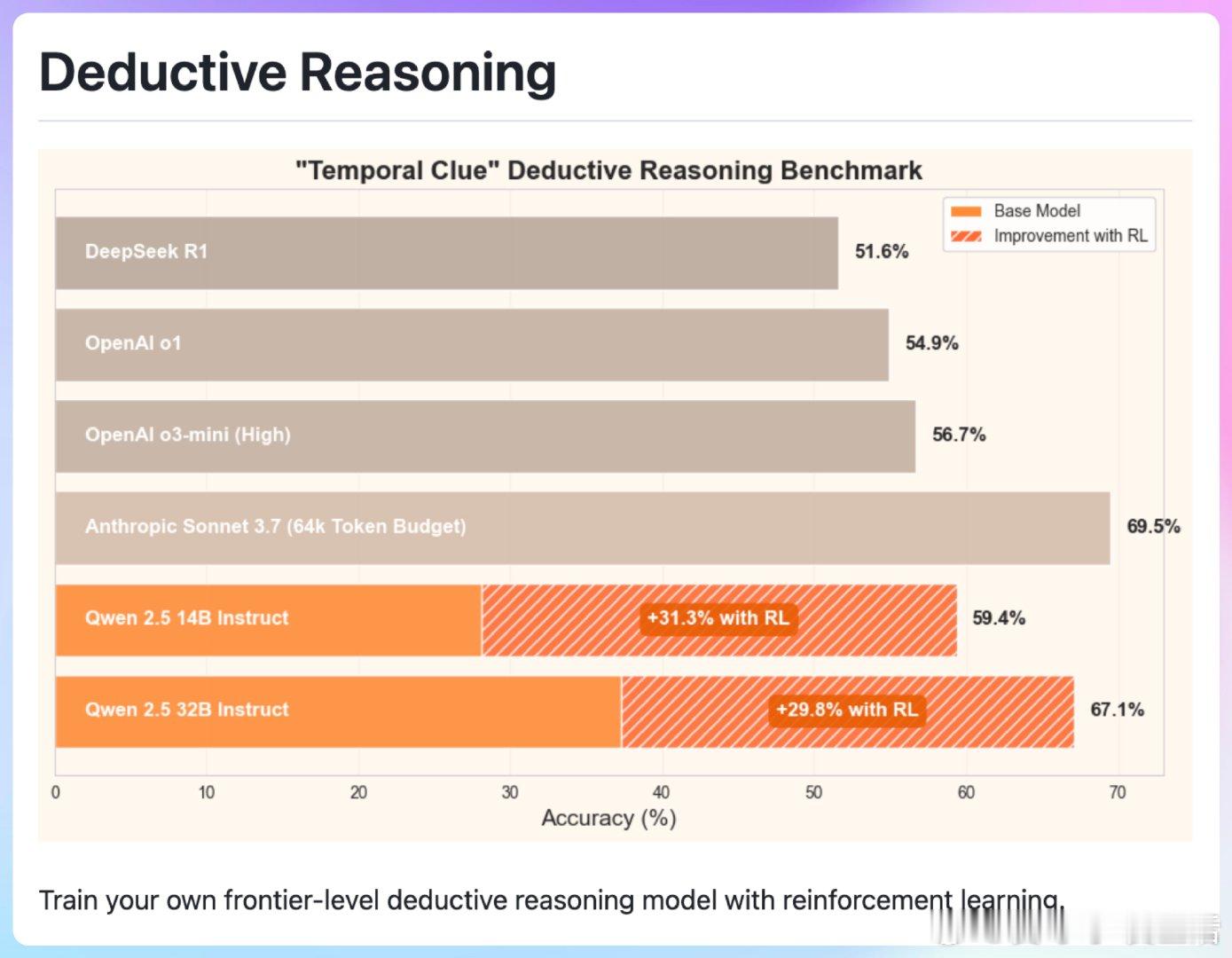
【[36星]OpenPipe/deductive-reasoning:一种训练高级演绎推理模型的方法,通过强化学习使用开源权重的语言模型能够执行复杂的逻辑推理任务,并且在成本效率上具有竞争力。亮点:1. 使用强化学习,让小模型也能达到SOTA性能;2. 仅需16个训练样本即可实现显著性能提升;3. 训练成本低,性价比超高】
'Train your own SOTA deductive reasoning model'
GitHub: github.com/OpenPipe/deductive-reasoning
演绎推理 强化学习 AI训练 AI创造营