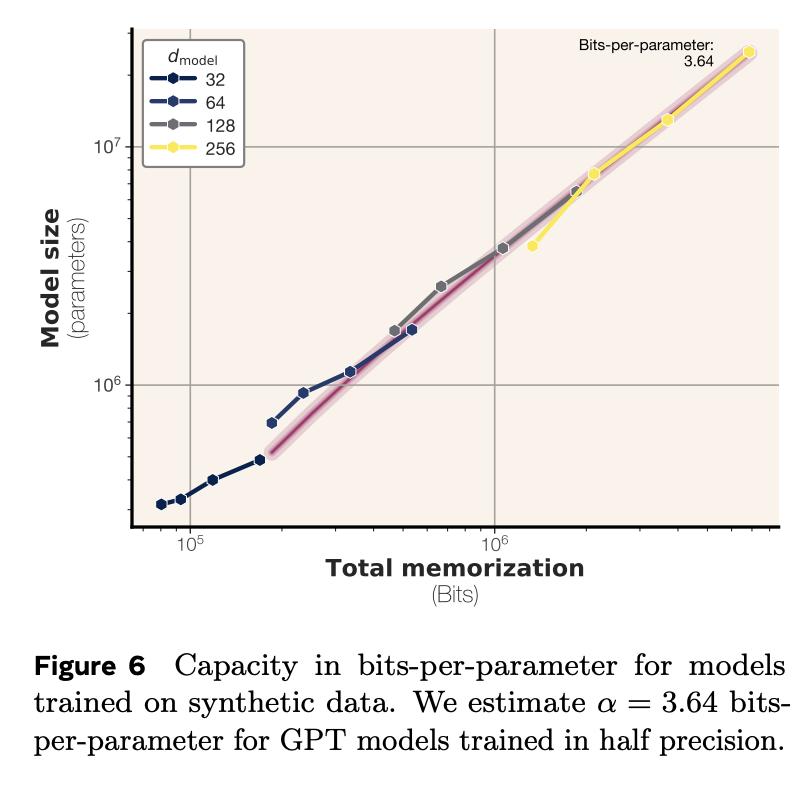
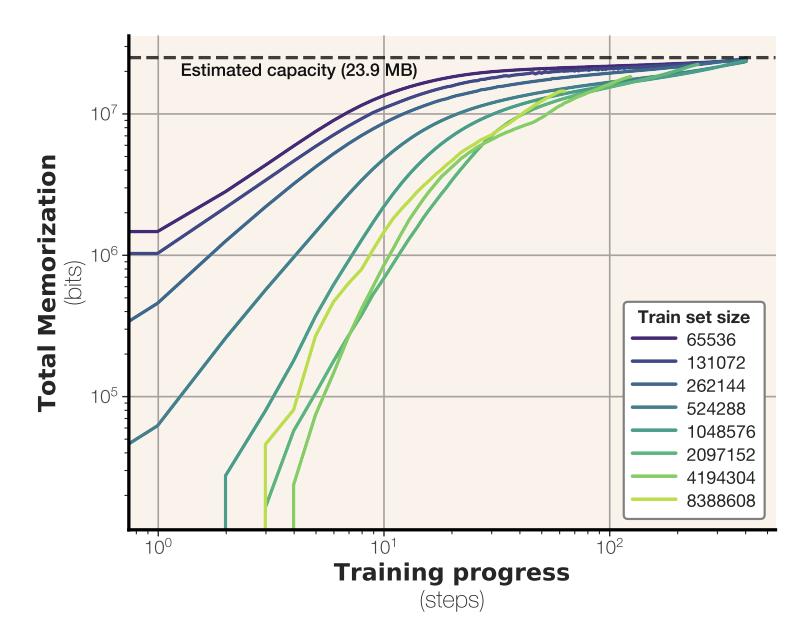
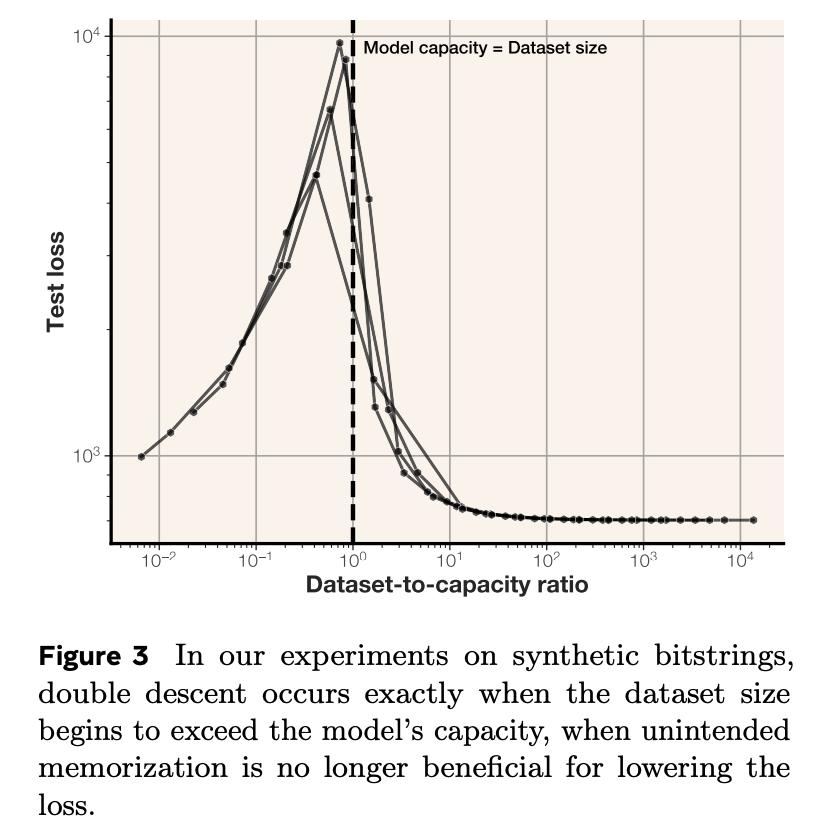
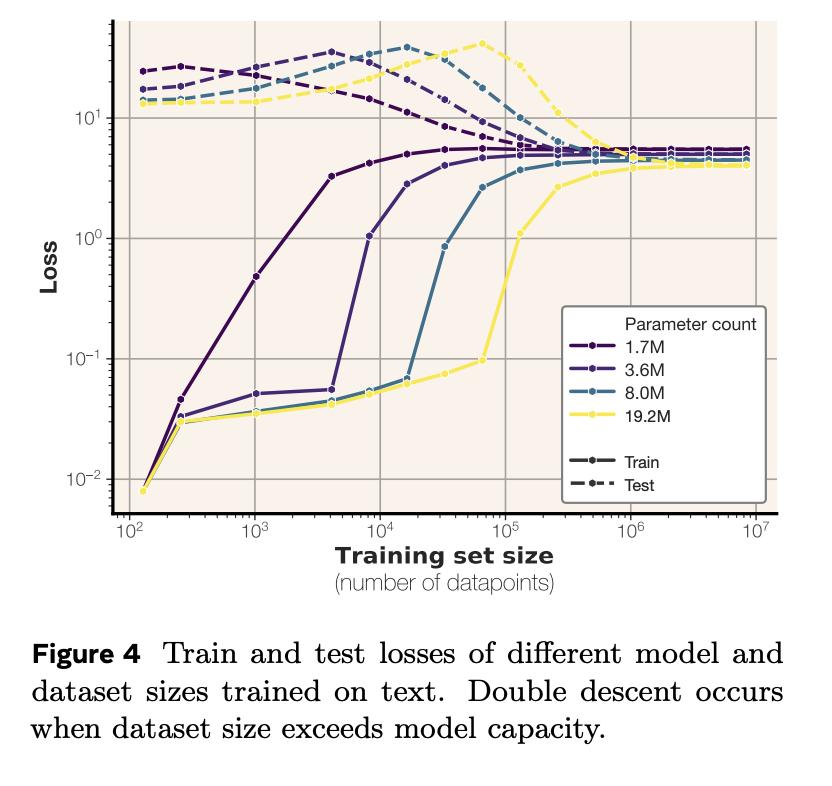
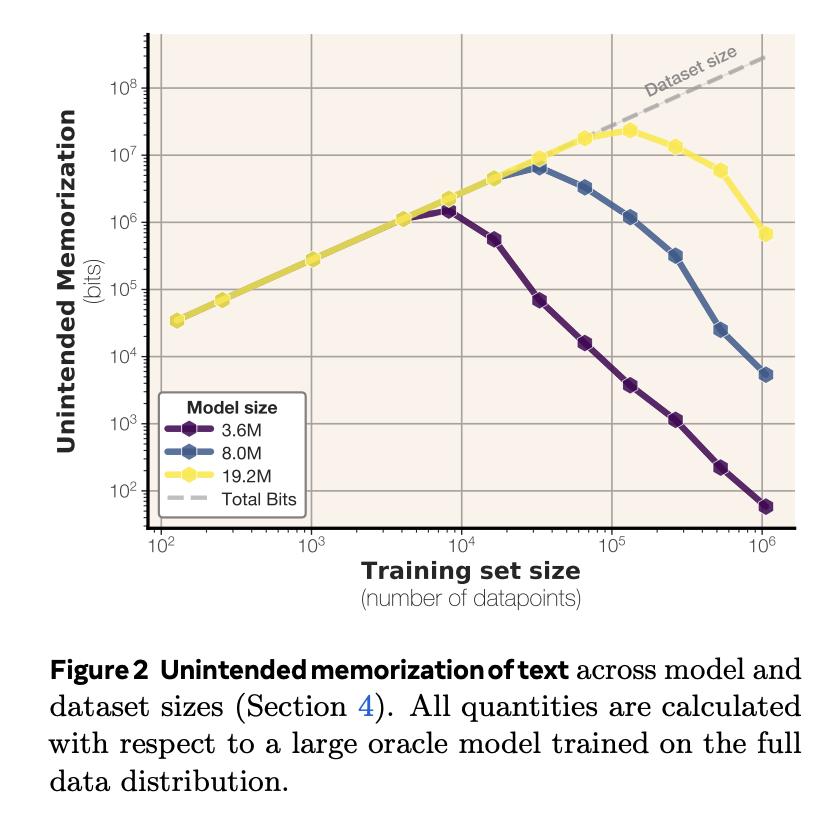
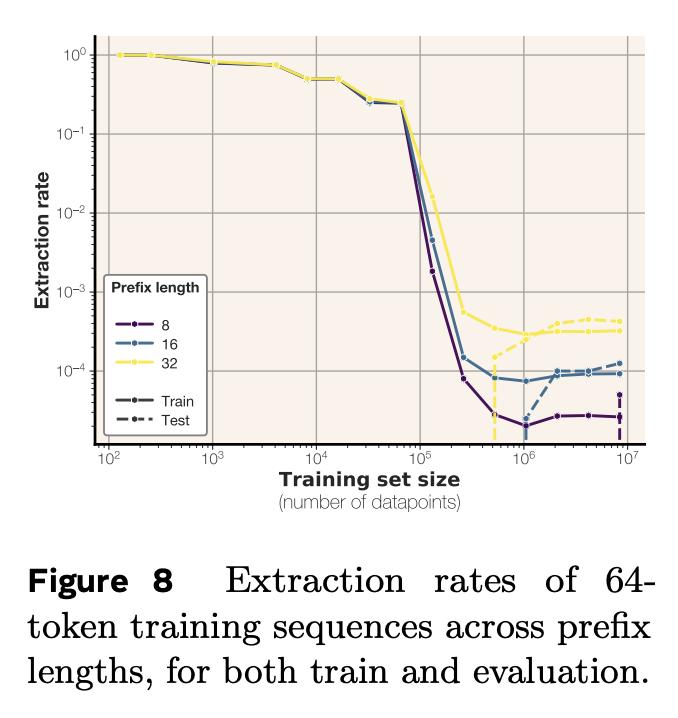
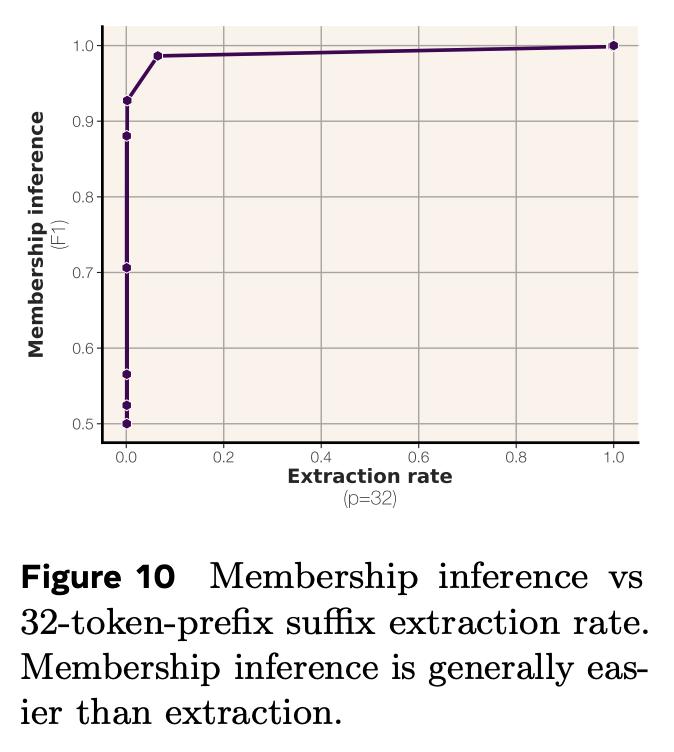
你有没好奇过,语言模型究竟能记住多少信息? Meta的最新研究带来了答案:GPT类模型,每个参数能记忆3.6比特数据。【图1】 并且,在通过随机均匀字符串进行约100万步的超大批量训练,将所有模型训练至“饱和”状态之后,研究团队还发现个很有趣的现象: 模型记忆总量与训练数据规模无关。这意味着模型本身有一个固定的“记忆上限”,即使给它再多的样本,它的记忆也会“摊薄”,无法记住所有细节。【图2】 这个发现也很好地解释了模型为什么会突然“顿悟”:当模型的记忆容量饱和,无法完美记住所有训练样本时,它就必须开始智能地共享样本之间的信息。【图3】【图4】 当模型用文本数据进行训练时,情况会稍有不同:它只会记住参数容量允许范围内的样本。一旦超过这个记忆极限,模型就会放弃逐个样本的记忆,转而共享信息,这就是我们常说的“泛化”。【图5】 研究团队在完全去重、纯净的文本数据环境中进行了实验,还发现了一些关于隐私的重要结论: 当模型记忆容量充分饱和后,测试样本反而比训练样本更容易被提取出来。【图6】 最容易被提取的是那些包含极其罕见token的样本 成员推理远比数据提取容易【图7】 最终,研究团队得出结论:接受海量数据训练的模型无法记忆全部训练数据。根本原因在于容量不足。【图8】 Meta团队的研究人员究竟是如何准确计算记忆容量数据的呢?这背后具有两项关键创新: 排除泛化的影响 研究团体将记忆现象划分为“非预期记忆”和“泛化”,泛化是模型对真实数据生成规律的理解。 研究团队用没有内在规律的随机均匀字符串进行测试。这样就迫使模型只能通过记忆数据点来降低错误。 用“压缩率”量化模型记忆程度 团队使用Kolmogorov复杂度理论来定义和测量模型对数据的记忆,计算出了模型在给定数据集上的压缩率。 你可以这样理解:模型对数据的记忆量,就是原始数据的“混乱程度”(熵)减去模型压缩后数据的“混乱程度”。 在随机均匀字符串数据集上,由于数据完全随机,其“混乱程度”是已知的,所以可以直接计算出模型对数据的记忆量。