推理模型倾向于知难而退苹果新研究发现推理模型越难越摆烂
越困难的问题,推理模型一定会越努力解决吧!
十分反直觉的是:当问题难到一定程度,推理模型反而就开始“摆烂”了。
不久前,苹果机器学习研究中心的研究团队对这样一个问题产生了好奇:推理模型(LRM)真的在“思考”吗?问题的复杂度如何影响了它们的表现?【图1】
于是,他们深入观察了几个推理模型(Claude 3.7 Sonnet、DeepSeek-R1、o3-mini、DeepSeek-R1-Qwen-32B)的“思考”过程,得出了几项有趣的结论:
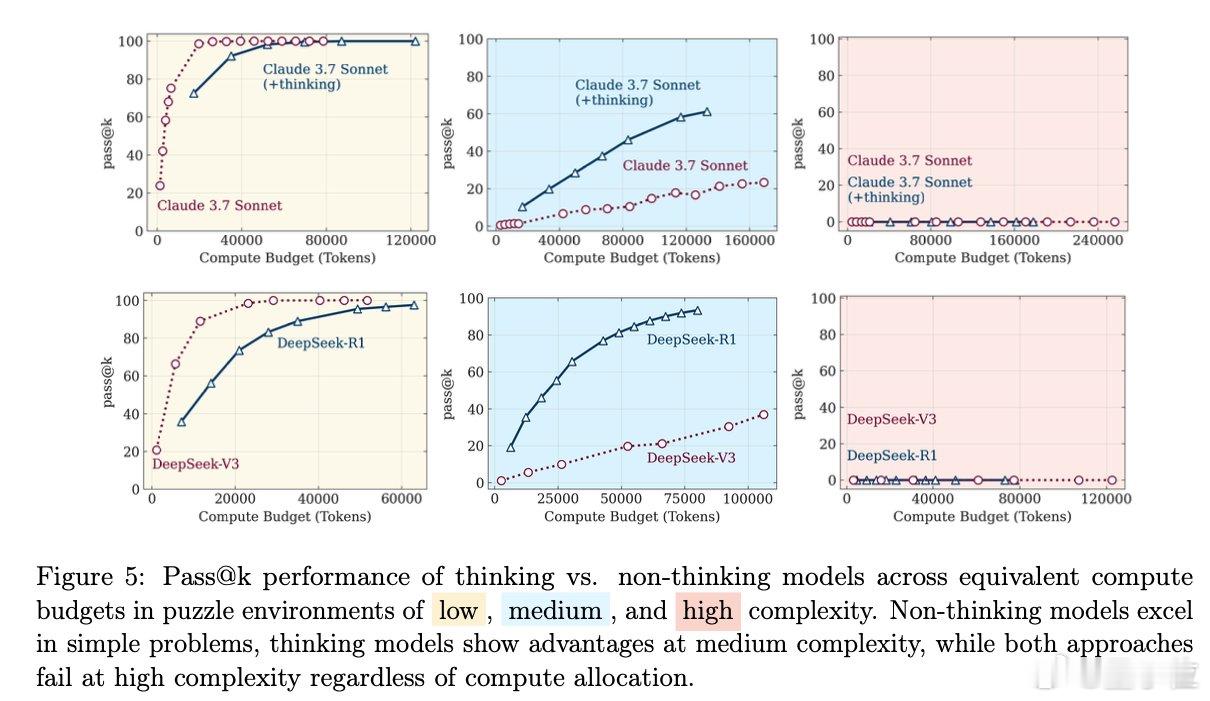
- 中等复杂度是推理模型的“舒适区”:实验表明,推理模型只有在中等复杂度下的表现优于标准语言模型。一旦问题复杂度超过某个阈值,推理模型和标准语言模型的准确率都会彻底“崩盘”。【图2】
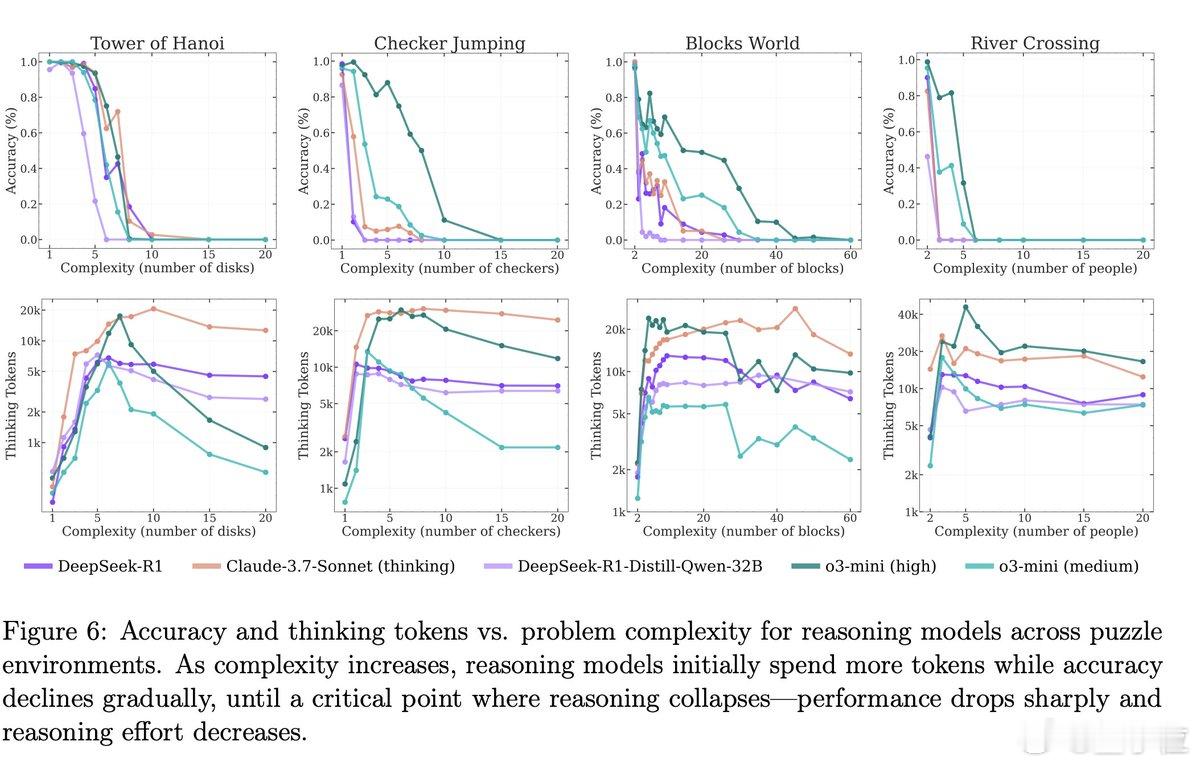
- 越难越“不想思考”:随着问题难度增加,推理模型一开始会进行更多“思考”,但很快它们的“思考量”反而会减少,即使它们还有充足的token预算。【图3】
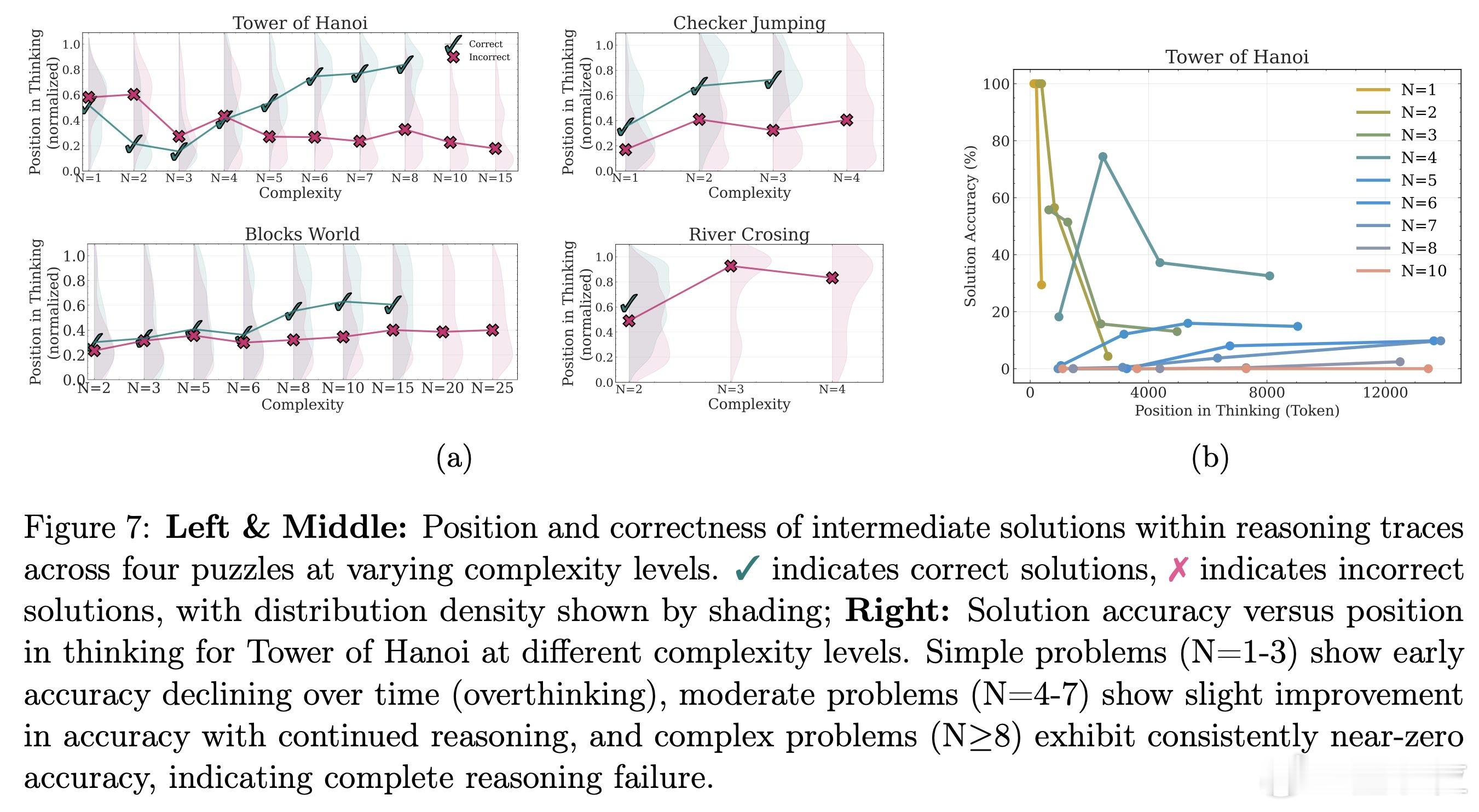
- 面对简单问题,模型会在早期就找到答案,但继续"过度思考"出错;中等问题时,模型会先探索错误的路径,但在后期能找到正确的解决方案;困难问题则完全失败。【图4】
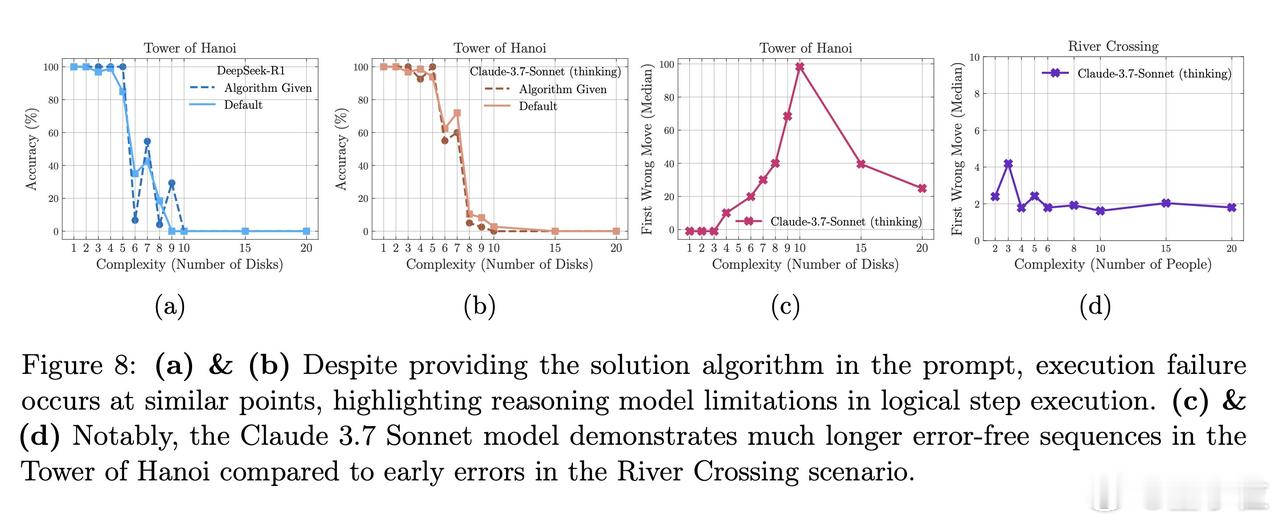
- 即使直接给模型解决问题的算法,让它们只需按步骤执行,推理模型仍然在相同的复杂度点上失败。这表明,AI在处理符号操作上存在根本性的局限。【图5】
可能有人就要问了,这个实验如何进行的?
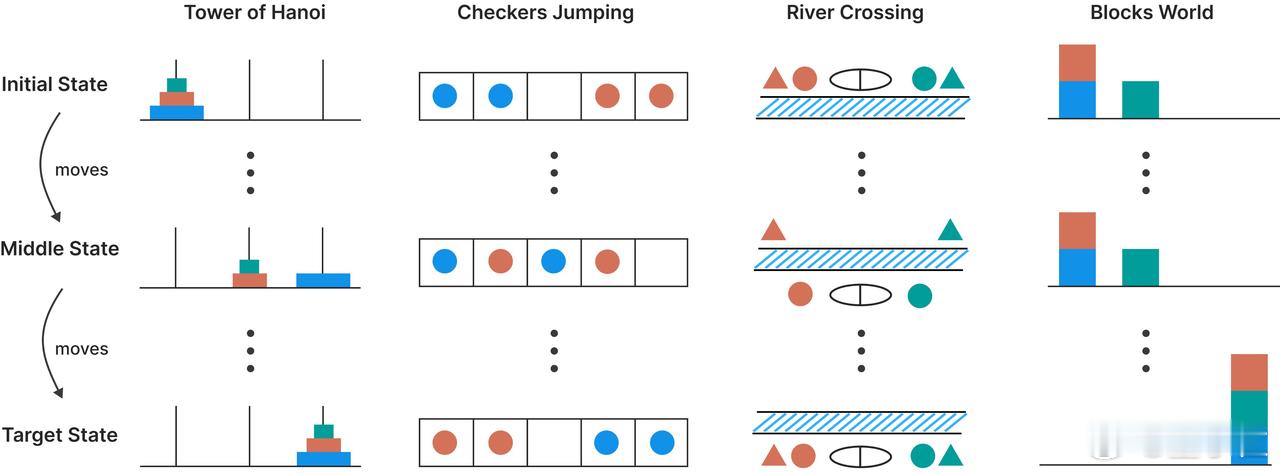
具体来说,研究团队研究设计了四种可控的谜题环境:汉诺塔、跳棋、过河问题和积木世界,来探索推理模型的思考过程。【图6】
他们通过调整谜题中的元素数量(比如汉诺塔的盘子数量),来控制问题的复杂度。问题规模越大,需要的推理步骤就越多,复杂度也就越高。
这种实验环境的好处是,可以排除数学和编程基准测试中可能存在的“数据污染”,精确地控制问题的组合复杂度,同时保持逻辑结构的一致性。让研究人员能够分析最终答案以及AI内部的推理痕迹,从而深入了解推理模型的“思考”过程。
因此,从最终结果来看,尽管这些推理模型通过强化学习训练获得了复杂的自我反思机制,但它们局限性可能仍然比想象中严重。
论文地址: