导读 深挖多模态 AI 的底层动能——全链路数据破局之道在当今人工智能的演进历程中,多模态大模型(LMM)的竞争已然步入“深水区”。从单纯的文本交互到视频理解、情感识别以及跨模态生成的全面爆发,技术的每一次飞跃,其底层逻辑都高度指向了同一个核心命门:高质量、多维度数据的持续供给。然而,理想与现实之间存在着巨大的鸿沟。据行业统计,超过 70% 的 AI 研发团队在项目启动初期就倒在了数据采集这一关。
IP刚购买即遭封禁,封禁率甚至高达 80%;百万级规模的数据采集周期动辄耗时三五个月,远超项目预想的交付周期;更具挑战性的是,好不容易采集到的海量文本、图像与语音数据往往处于“孤岛”状态,难以实现精准对齐,直接导致模型训练后的精度出现断崖式下降。可以说,数据已成为 AI 多模态创新中名副其实的“生死线”。
本次分享由 IPIDEA 技术总监朱守志老师深度复盘。朱老师结合其深耕 HTTP 代理技术十余年的实战经验,以及服务超过 50 家 AI 头部企业的深厚沉淀,首次从架构层面系统性地公开了如何构建“工具矩阵+智能调度”的全链路解决方案。这套方案不仅将 IP 存活率稳定提升至 95% 以上,更在实际应用中将采集效率提高了 40%,直接推动模型训练周期缩短了 36%。本文将以此为核心,全方位拆解多模态 AI 时代下的数据破局之道。
主要内容包括以下几个部分:
1. 企业与品牌介绍:专注全球网络基础服务
2. 数据命门与破局之道:破解 AI 多模态的三大困局
3. 核心工具能力拆解:全模态素材的高效引擎
4. 未来展望与生态协同:迈向 AI 数据湖时代
5. 结语
分享嘉宾|朱守志 江苏艾迪信息科技有限公司 技术总监
内容校对|郭慧敏
出品社区|DataFun
01
企业与品牌介绍:专注全球网络基础服务

1. 行业深耕与品牌积淀:从资源提供商到方案解决商
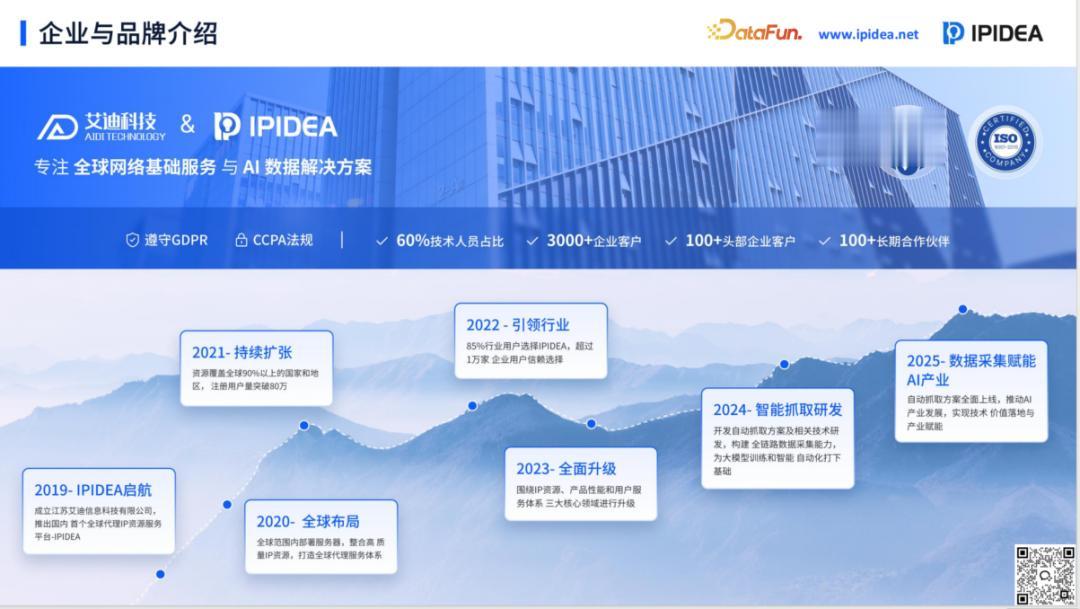
IPIDEA 的发展史,某种程度上是中国网络基础服务进阶的缩影。自 2019 年品牌正式启航以来,IPIDEA 便致力于解决全球范围内的网络访问与数据流通难题。在 AI 大模型兴起之前,行业对 IP 资源的需求相对单一,但随着 AI 对数据质量和规模要求的指数级提升,IPIDEA 的技术路线也随之发生了质变。
从最初的简单代理服务提供商,快速演进为以“工具矩阵+智能调度”为核心的全链路数据解决方案专家,IPIDEA 目前已在技术上实现了对全球 220 多个国家和地区的全面覆盖。到 2022 年,其在国内行业用户中的选择占比已突破 85%,累计注册用户超过 80 万,成为 1 万多家企业客户在处理复杂网络环境时的首选合作伙伴。2024 年,随着大模型训练需求的爆发,IPIDEA 进一步强化了自动抓取与数据清洗能力,为多模态创新夯实了底层地基。
2. 核心能力与技术底座:高占比研发投入驱动合规交付
作为一家深植于技术基因的企业,IPIDEA 深知“人才”与“合规”是业务长青的双翼。在公司约 500 名的员工结构中,研发与技术人员占比高达 60%,这种高强度的技术投入确保了其产品在面对日益复杂的全球网络对抗(如各类高级反爬算法)时,依然能保持极其敏捷的迭代能力。
在合规性与安全性方面,IPIDEA 已先后获得 ISO 27001 信息安全管理体系认证及 ISO 9001 质量管理体系认证,并严格遵循欧盟 GDPR 和美国 CCPA 等全球主流隐私保护法规。目前,公司已深度服务于 3000 多家企业客户,其中包括 100 多家行业头部大厂。值得注意的是,这些头部客户的合作时长普遍在 3 至 5 年以上,这种长效的信任背书,充分证明了其在大规模、高并发场景下极高的交付稳定性。
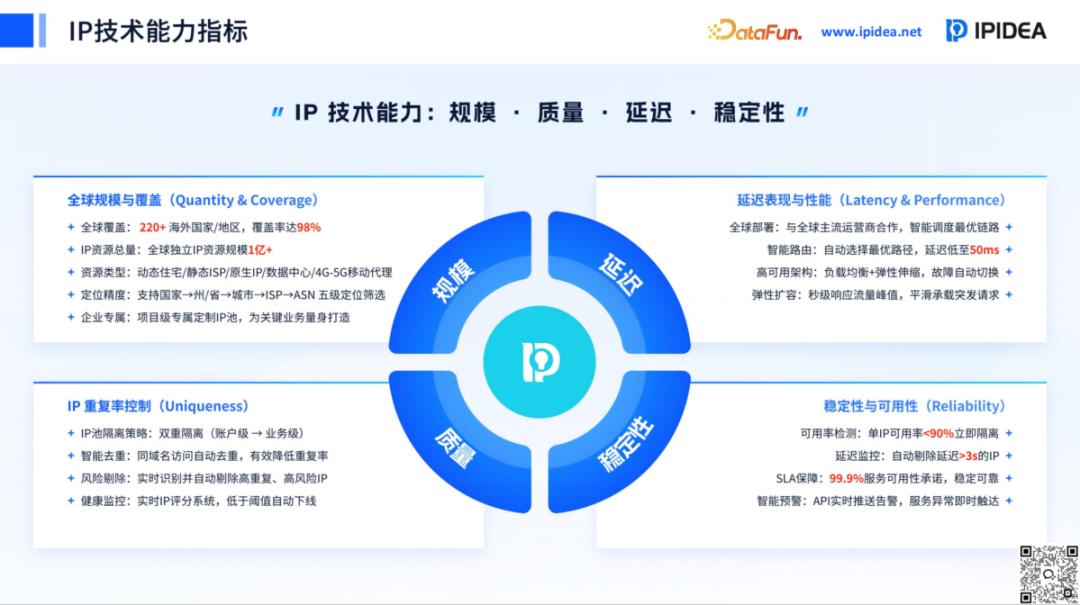
3. 全球 IP 代理网络 (IPPN) 的构建逻辑
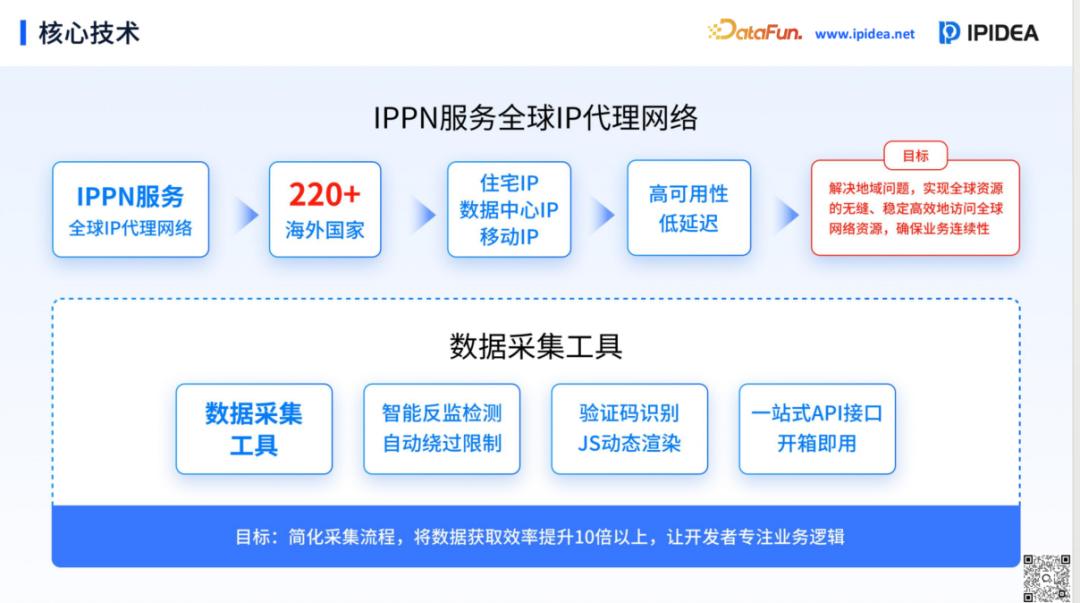
IPIDEA 的技术核心在于其自主构建的 IPPN(全球 IP 代理网络)。这并非简单的服务器堆砌,而是一个高度智能化的资源池。该网络集成了超过 9000 万个纯净代理IP,资源维度丰富,包括:
住宅 IP:来源于真实的家庭宽带节点,具有极高的信誉等级和隐匿性,是突破严苛反爬机制的首选。数据中心 IP:依托 IDC 机房,提供极高的并发速度和稳定性,适合大规模、非敏感的数据抓取。移动 IP:基于全球 4G/5G 移动基站,由于其 IP 资源的天然稀缺性,能够有效应对针对固定 IP 段的封锁。针对 AI 多模态采集,IPPN配套的工具集支持智能反监测、JavaScript 动态渲染及全自动验证码识别。这意味着开发者无需再关注底层复杂的网络握手和身份伪装,采集效率较传统模式提升了 10 倍以上。
02数据命门与破局之道:破解 AI 多模态的三大困局 1. 架构设计的哲学:模块化、可扩展与高可用
1. 架构设计的哲学:模块化、可扩展与高可用在多模态大模型的训练语境下,数据呈现出“海量(Volume)、异构(Variety)、实时(Velocity)”的典型特征。为了应对这一挑战,IPIDEA 提出了一种全新的架构设计理念:模块化、可扩展分布式架构。
这种架构的核心在于将“采集”这一动作从单一的 HTTP 请求,升级为涵盖环境解锁、协议模拟、数据提取、清洗转换的全生命周期管理。通过分层设计,系统可以根据不同目标站点的防护强度、不同模态(如高清视频流 vs 社交媒体短贴)的数据特征,动态调整后端资源的分配比例。这种灵活性是破解“采集周期失控”的关键,它允许研发团队在不重构底层代码的情况下,实现采集规模的快速横向扩展。
2. 三层技术架构的深度解构:解锁、采集与解析
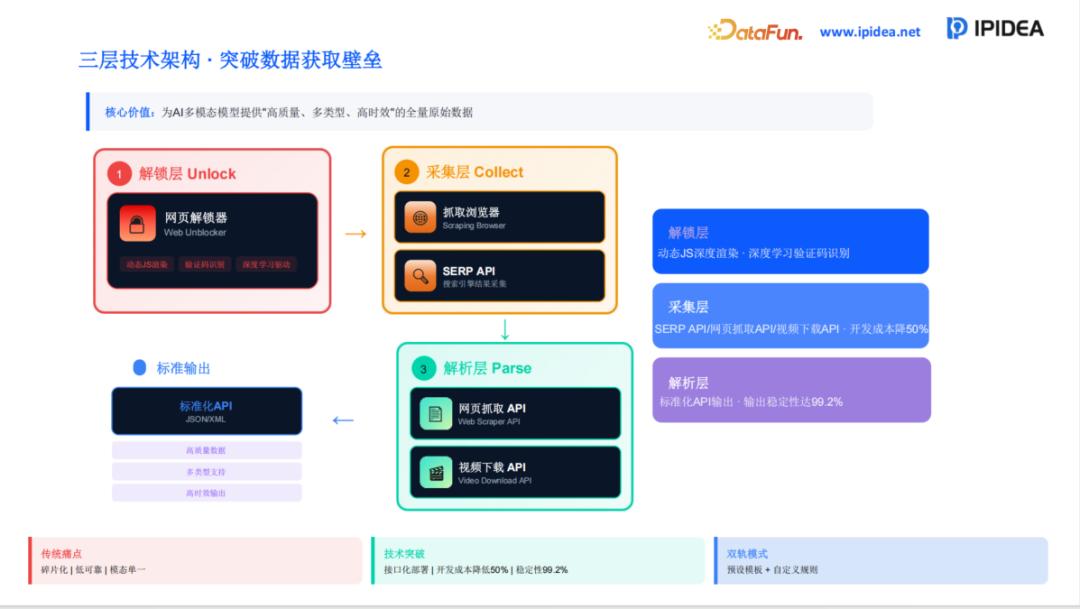
为了实现全链路的自动化,IPIDEA 将技术体系精准划分为三个互联互通的层级:
解锁层 (Unlock): 核心产品为“网页解锁器 (Web Unblocker)”。当前的互联网环境下,Web 应用普遍采用了高级的 Bot 检测机制(如 TLS 指纹识别、Canvas 渲染指纹等)。解锁层通过深度模拟真实用户的行为特征和协议栈信息,使得所有请求在目标站点看来均为自然访问,从而从根本上解决了 80% 的高封禁率问题。采集层 (Collect): 该层集成了专为大模型设计的 SERP API 和抓取浏览器。特别是在 RAG(检索增强生成)场景中,大模型对外部知识的实效性要求极高。采集层能够通过毫秒级的响应,从全球主流搜索引擎和社交平台实时获取数据,为 AI 模型提供“新鲜”的语料。解析层 (Parse): 采集到的原始数据(HTML、二进制视频流)往往是杂乱无章的。解析层负责利用 AI 算法将这些非结构化信息自动转化为标准化的 JSON 或 XML 格式,并确保数据输出的稳定性高达 99.2%。这一层级的工作为后续的数据标注节省了超过 50% 的人工成本。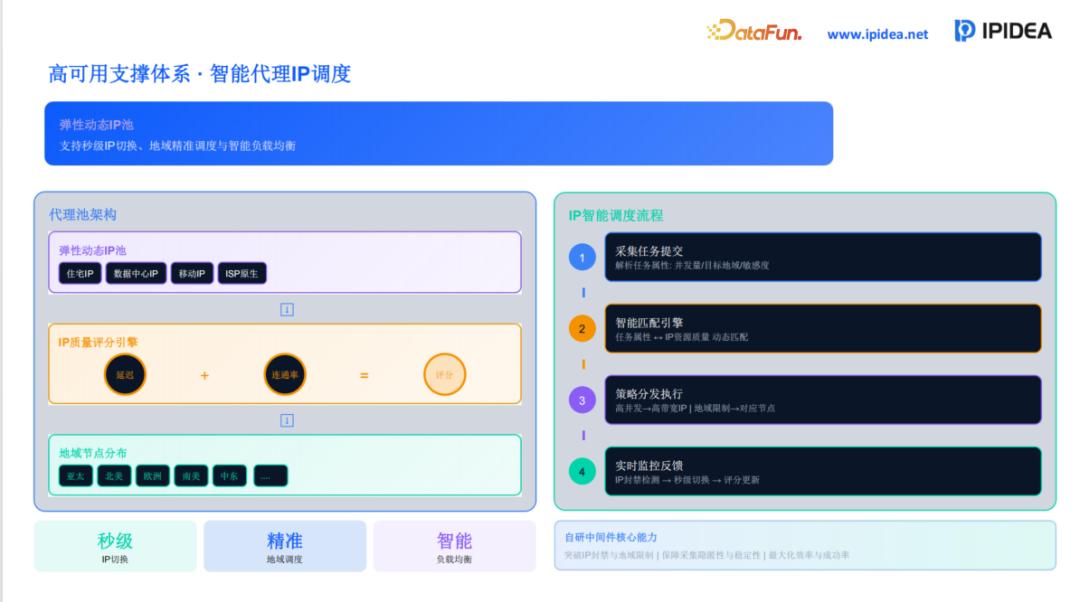
3. 智能调度支撑体系:确保高并发下的极致稳定
在大规模数据采集中,最怕的是“断流”。IPIDEA 构建了一套基于 AI 算法的智能调度体系,以应对瞬时产生的数亿次并发请求。
首先,系统引入了智能负载均衡 (Load Balancing) 技术。当监测到某一地理区域或某一类型的 IP 节点负载过高时,调度中心会自动将任务迁移至空闲节点。其次,利用 Auto Scaling (自动伸缩) 机制,服务器集群能够根据实时任务量动态增减,既保证了任务的处理速度,又优化了运营成本。
此外,该体系还内置了 IP 质量评分引擎。系统会根据每个 IP 的延迟、连通率、被目标站点封锁的频率进行实时评分。那些高分值的 IP(如优质的 ISP 原生 IP)会被优先分配给权重最高的采集任务。通过这种“自愈式”的资源调度,IPIDEA 能够保证全天候不间断的数据供给。
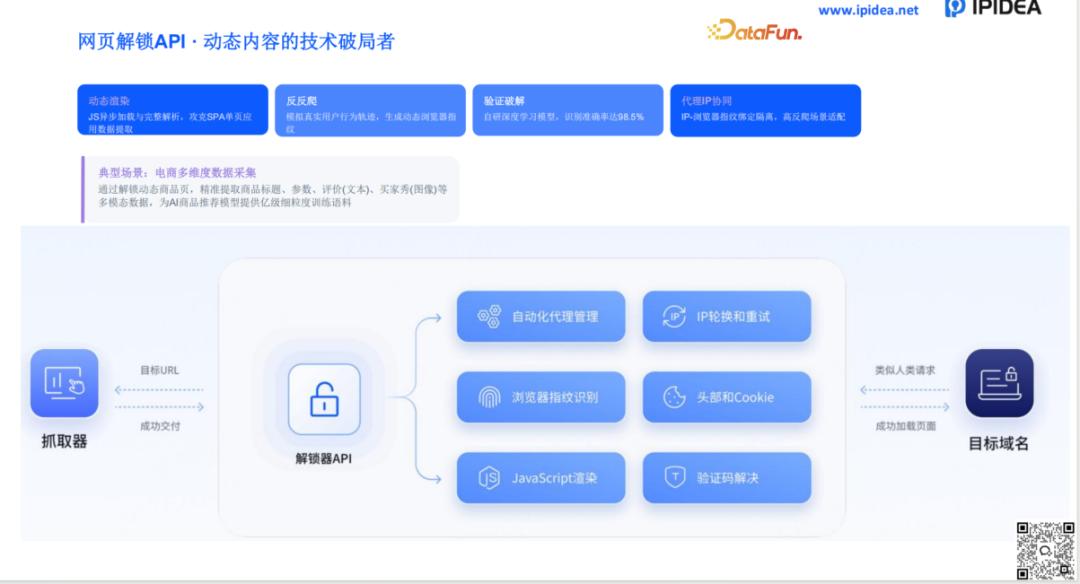
03核心工具能力拆解:全模态素材的高效引擎1. 网页解锁器:突破动态交互与加密堡垒在多模态数据挖掘中,网页不仅仅是文本的载体,更是复杂交互和动态数据的集合。现代网页大多采用 SPA(单页应用)和异步加载技术,传统的静态爬虫早已无能为力。
网页解锁器的优势在于它内置了完整的渲染引擎。它能够像真实人类一样执行页面滚动、按钮点击、表单填充等操作。更重要的是,它能完美模拟各种浏览器指纹,包括 TLS 1.3协议特征、User-Agent 动态切换等。对于开发者而言,只需要发送一个 API 请求,解锁器就会在后台完成所有的反爬对抗和页面渲染,最终返回干净、完整的结构化数据。在电商竞价监控、社交媒体舆情分析等高强度对抗场景中,这无疑是一把利剑。
2. SERP API:驱动 RAG 与实时 AI 的“知识泵”
搜索引擎结果页(SERP)是人类文明最新动态的汇总,也是AI模型获取即时知识的最高频入口。IPIDEA 的 SERP API 针对 Google、Bing、Baidu 等全球主流引擎进行了深度适配。
该工具不仅能抓取搜索排名,更支持对结构化片段(Featured Snippets)、相关问题(People Also Ask)、图片搜索及地图信息的全量提取。对于正在研发国产大模型的团队来说,SERP API 结合 Redis 分布式缓存架构,实现了毫秒级的响应速度。这意味着大模型在回答“今天发生了什么”这种时效性极强的问题时,可以瞬间触达全球热点,确保生成内容的真实性与准确性,极大降低了模型的“幻觉”现象。

3. 视频下载 API:解决多模态最难啃的“硬骨头”
视频数据是多模态创新的核心燃料,也是公认最难处理的数据类型。视频平台往往拥有最复杂的加密协议、动态分段技术以及严格的带宽限制。
IPIDEA 的视频下载 API 支持 TikTok、YouTube、Instagram、Twitch 等全主流视频平台。它不仅仅是一个下载工具,而是一个“视频数据提取器”。它能自动识别视频的最优分辨率,提取视频原声(用于语音训练),解析视频标题、描述、评论及发布者信息(用于图文对齐训练)。通过深度解析视频流的元数据,该工具能直接输出适配AI训练格式的数据包。这对于 Sora 类视频生成模型、视频内容理解模型的研发团队来说,极大地缩短了数据预处理的繁琐环节。
04未来展望与生态协同:迈向 AI 数据湖时代1. 技术升级:从自动化采集向智能化预测演进随着 AI 技术本身的进步,数据采集也将进入“以 AI 治 AI”的新阶段。IPIDEA 目前正在研发基于机器学习(ML)的 IP 信誉预测引擎。
传统的调度逻辑是“失效后重试”,而未来的智能化调度则是“风险预判”。通过对全球数千万个节点进行画像分析,系统能够精准预判某个 IP 在特定时间段、针对特定站点的存活概率。这种前瞻性的风险建模,配合动态信誉评分体系,能够将任务成功率推向极致,实现 99.5% 以上的可用性保障,为大模型的持续训练提供如电力般的稳定供应。
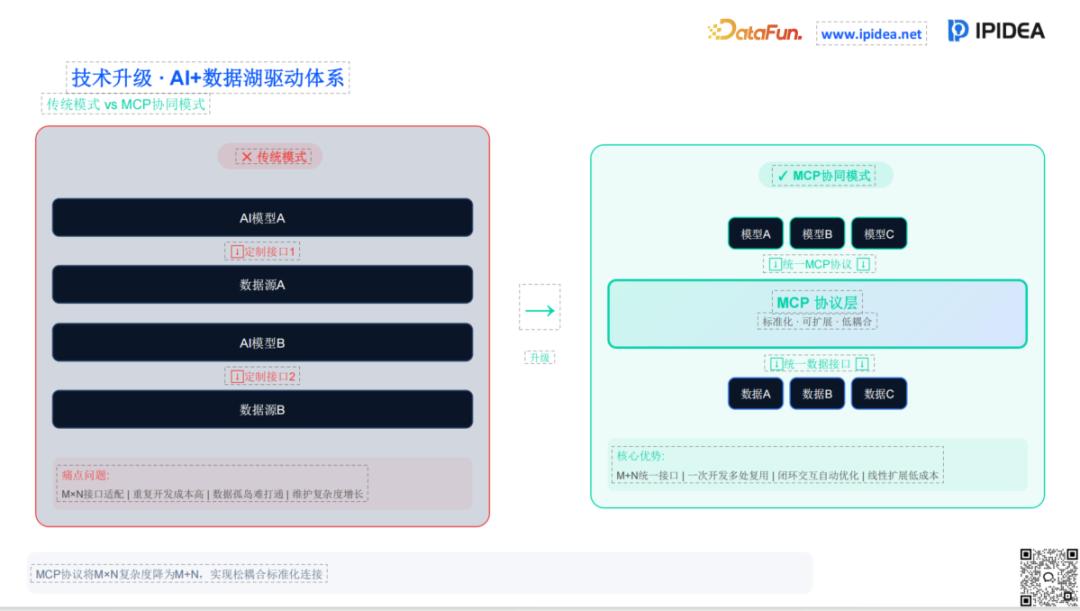
2. MCP 协同模式:重构 AI 开发的成本逻辑
在过去,AI 研发面临着极其低效的“M×N”开发模式:即每增加一个模型或一个数据源,都需要投入大量的研发人效进行接口对接与适配。这种模式导致了严重的数据孤岛现象,维护复杂度随业务增长呈指数级上升。
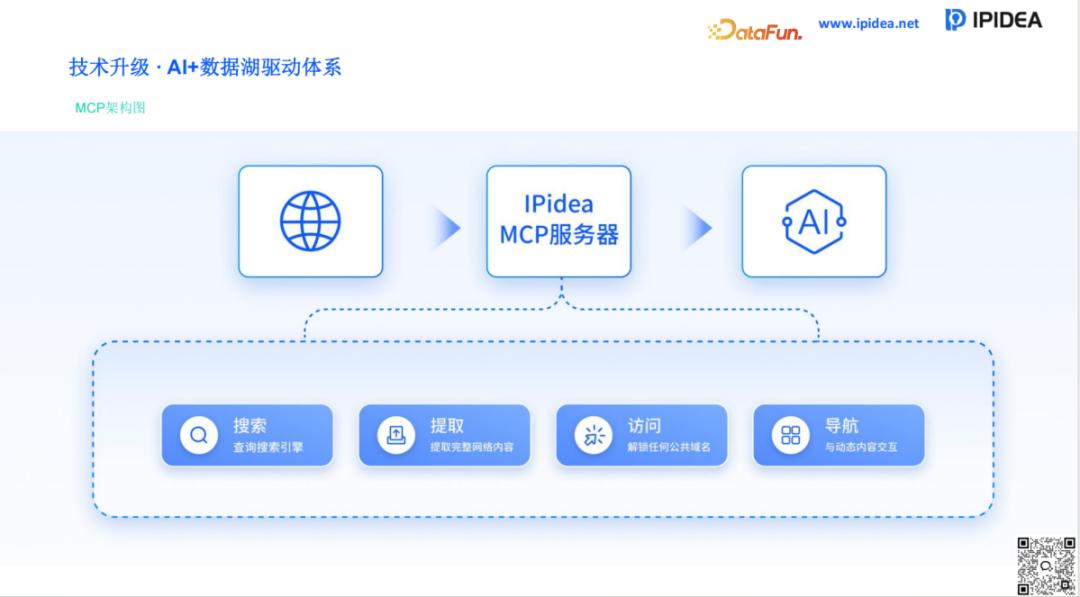
IPIDEA 积极倡导并推动的 MCP(Model Context Protocol)协同模式,旨在打破这一瓶颈。通过在模型与数据源之间引入一层标准化的 MCP 协议层,将复杂度直接降低为“M+N”。在这一模式下,无论底层数据来自哪个平台、何种模态,都会被统一抽象为标准的“上下文资源”。模型通过统一接口即可实现对全网数据的无缝调用。这种“一次开发,多处复用”的松耦合设计,将极大地降低 AI 项目的准入门槛和维护成本。
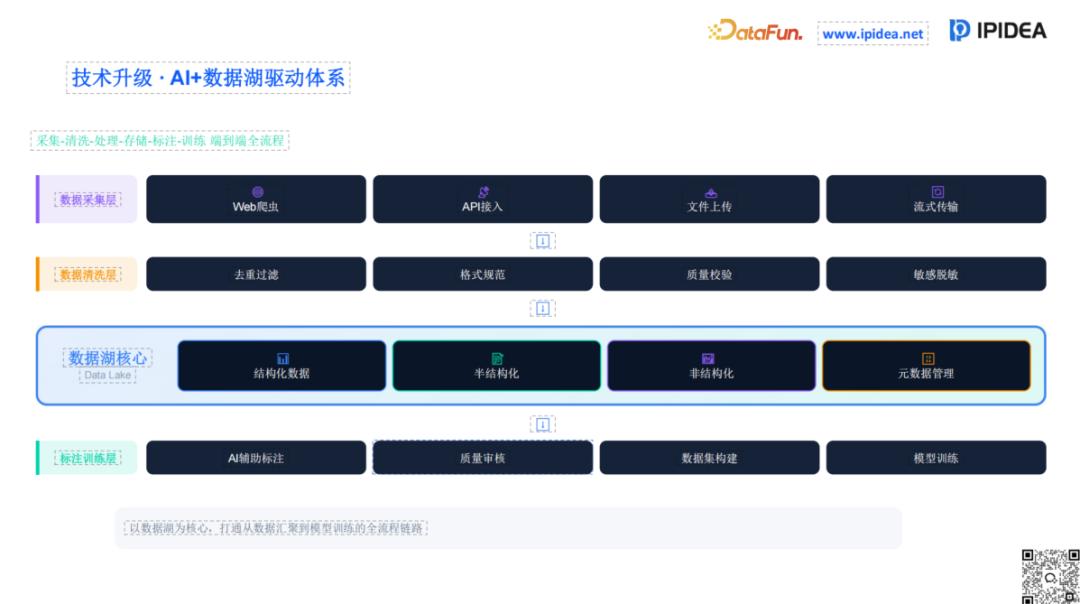
3. 打造端到端全流程“AI+数据湖”驱动体系
最终,数据竞争的胜负手在于全链路的整合效率。IPIDEA 向行业展示了一个宏大的蓝图:以数据湖为核心的全流程链路。
在这个体系中,数据经历了从“野外采集”到“实验室精炼”的全过程:
数据采集层:整合 Web 爬虫、API 接入、流式传输,实现全量、异构数据的实时汇聚。数据清洗层:利用 AI 模型自动执行去重过滤、格式规范化、质量校验及敏感信息脱敏,确保入库数据的“纯度”。数据湖核心 (Data Lake):实现结构化、半结构化与非结构化数据的统一存储与元数据管理。标注训练层:引入 AI 辅助标注,通过质量审核后构建数据集,直接输出至模型训练端。这种端到端的一体化方案,能够让企业不再纠结于碎片化的工具选型,而是将全部精力集中在业务创新与模型迭代上。
05结语在 AI 多模态创新的漫长征途中,数据从未像今天这样成为决定生死的核心资产。IPIDEA 通过“工具矩阵+智能调度”的深度布局,不仅是在提供一种技术方案,更是在重构 AI 时代的生产力底座。当开发者不再受困于 IP 封禁、采集延迟和格式混杂的泥沼,多模态 AI 的创新火花才会被真正点燃。未来,IPIDEA 将继续以全球化的视野和专业的技术,守卫好数据这一“命门”,助力每一位 AI 探索者在多模态的浪潮中化困局为胜局,开启智能进化的新纪元。
以上就是本次分享的内容,谢谢大家。