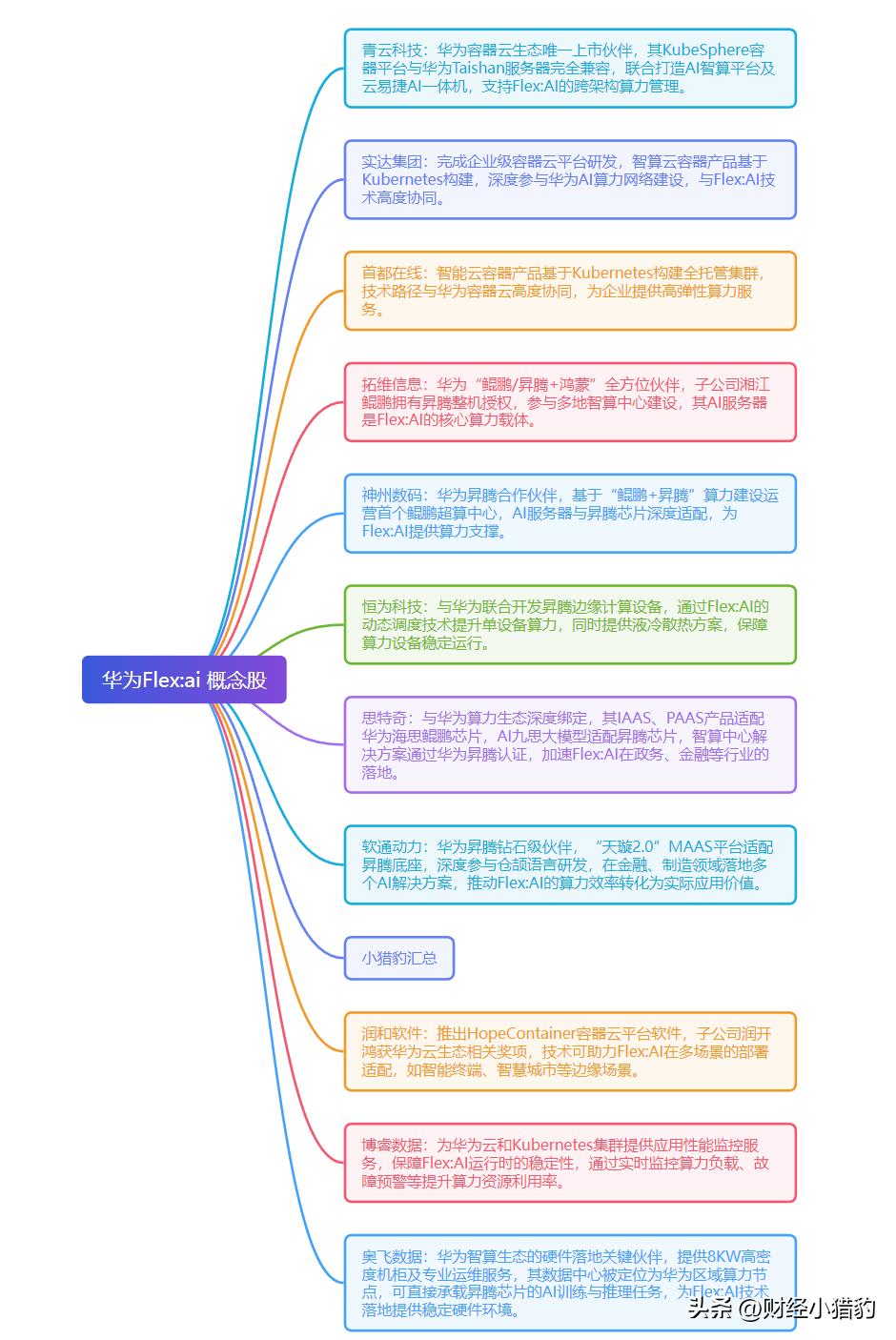
就在周五盘后,华为在上海低调发布并开源其全新AI容器技术——Flex:ai。
没有炫目的发布会,却在技术圈掀起波澜。

原因很简单,它直指当前AI产业最痛的“隐性成本”。算力浪费。
据IDC最新报告,全球AI训练集群的平均GPU利用率仅为34%,部分中国智算中心在特定场景下低于这一水平。
这意味着,每投入1亿元建设AI算力,就可能有近7000万元在“空转”。
华为的Flex:ai就是为了对整个资源调度底层逻辑的重构。
一、算力利用进入“精耕时代”最近2年,大模型竞赛催生了“算力军备竞赛”,企业竞相采购各种卡,动辄千/万卡起步。
但现实是,大概是60%的AI任务并不需要整张卡。
Flex:ai 的核心突破,在于将单张GPU/NPU按10%粒度精准切分,形成多个虚拟算力单元(vCU, virtual Compute Unit)。

例如,一张昇腾910B可同时服务10个轻量级推理任务,或混合承载3个训练+5个推理作业,互不干扰。
华为实测数据显示:在典型多租户AI场景下,Flex:ai 可将集群整体算力利用率从35%提升至60%以上,相当于用原有硬件实现近70%的性能增益,这可能比单纯堆叠芯片更具经济性。
更关键的是,这种提升不依赖特定硬件。
Flex:ai 通过统一抽象层,兼容英伟达CUDA、昇腾CANN乃至寒武纪MLU等异构架构。
这意味着,即可构建真正开放的混合算力池。
二、为什么现在必须用AI原生容器?传统Kubernetes的模式虽能跑AI任务,但对GPU/NPU缺乏细粒度感知,调度粒度粗、回收延迟高、跨节点协同弱。
根据目前公开的报道,Flex:ai是专为AI负载设计,具备三大原生能力:
亚卡级分配:支持0.1卡起配,满足小模型、微调、边缘推理等碎片化需求。
多级智能调度:结合任务SLA、数据亲和性、能耗成本动态决策。
跨节点聚合:将分散在不同服务器的0.3卡、0.4卡“拼成”1张完整逻辑卡,支撑大模型训练。

这些方面市场需求是很大,根据Gartner预测:
到2026年,60%的AI训练任务将运行在支持细粒度调度的AI原生容器平台上。
到2027年,75%以上的AI工作负载将容器化部署(2023年仅为45%)。
而采用AI原生调度的企业,其TCO(总拥有成本)平均降低28%。
换言之,在特定场景下,未采用AI原生容器的企业可能面临更高的算力成本。
 三、这方面对国产算力有什么影响
三、这方面对国产算力有什么影响过去,国产算力投资逻辑高度集中于“芯片是否对标海外”。
但即便昇腾910B性能接近H100,若缺乏高效的调度软件栈,用户仍会因“低效”而却步。
Flex:ai 的开源,或许可推动国产算力从“硬件替代”迈向“生态定义”阶段。
1、国产AI芯片的价值重估
昇腾、海光、寒武纪等芯片厂商,过去受限于软件生态薄弱。
如今,通过 Flex:ai 的统一接口,可快速接入主流AI平台,大幅降低客户适配成本。
2、AI基础软件
资源调度、容器运行时、异构编译器等“看不见的软件层”,正成为决定算力效率的关键。
类似Run:ai的海外企业已获得市场认可,国内具备相关技术能力的公司也可能受到资本关注。
3、AI应用
算力发展之下,当前AI应用
写在最后在摩尔定律放缓、芯片峰值性能不断提升的当下。如何让每瓦特电力、每一块芯片、每一毫秒时间都产生价值,或许可能AI基础设施竞争的核心。
Flex:ai不仅是一项技术输出,与其追逐参数更大的模型或更快的芯片,不如关注那些能让现有算力“多跑30%任务”的底层创新
特别声明:以上内容绝不构成任何投资建议、引导或承诺,仅供学术研讨。
如果觉得资料有用,希望各位能够多多支持,您一次点赞、一次转发、随手分享,都是笔者坚持的动力~