 本课时定位
本课时定位上一课我们讲的是产品起点:
想法可以很大,但起点一定要低。
这一课开始,我们进入 Agent 开发本身。
但注意,这一课依然不是要把所有概念一次性讲完。
一开始真不用学太多。
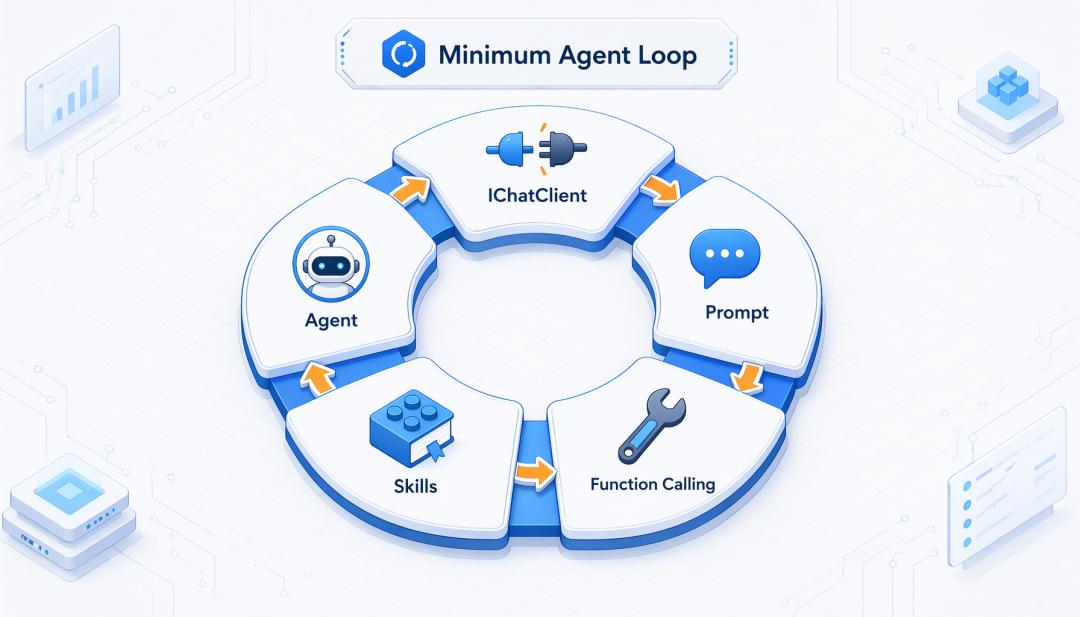
你只需要先搞明白 5 个东西:
IChatClient
Prompt
Function Calling
Skills
Agent
这几个点串起来,就足够支撑你做出第一个可运行 Agent。
不要一上来就被这些词吓住:
Multi-Agent
Workflow
Orchestration
Harness
Memory
MCP
Planner
Evaluator
Guardrails
Context Engineering
这些以后都会遇到。
但不是第一天都要懂。
第一天最重要的是建立一个最小知识闭环:

这一课的目标不是“懂完 Agent”。
而是先知道:
一个最小 Agent 到底由哪些东西组成,它们各自解决什么问题。
一、先别急着学一堆 Agent 概念很多人学 Agent,一开始就会陷入概念焦虑。
今天看到一个新框架。
明天看到一个新协议。
后天又看到一个新词:
AutoGPT
ReAct
Plan-and-Execute
Function Calling
Tool Calling
MCP
Agent Runtime
Agent Memory
Agent Workflow
Agent Harness
Multi-Agent Collaboration
看起来都很重要。
也确实重要。
但问题是:
你还没有做出第一个能跑通的 Agent,就开始试图理解完整 Agent 世界观。
这会让学习变得很重。
更糟的是,你可能会误以为:
不把这些概念都学完,就不能开始做 Agent。
其实不是。
开发第一个 Agent,只需要先回答几个非常朴素的问题:
我的 .NET 程序怎么先连上一个可用模型?
我要让模型扮演什么角色?
模型什么时候需要调用外部能力?
这些外部能力怎么暴露给模型?
当某个能力复用多次时,怎么沉淀下来?
对应到技术上,就是这一课的 5 个关键词。
二、IChatClient:先把模型连接起来在讲 Prompt 之前,我更建议先做一件很朴素的事:
先让你的 .NET 程序真的连上一个模型。

否则后面讲再多 Agent、工具、Skills,都会停留在概念层。
在 .NET 里,我非常建议一开始就熟悉 IChatClient这个抽象。
它来自 Microsoft.Extensions.AI,作用是把模型调用统一成一个比较稳定的接口。
你可以先不用太关心底层是:
DeepSeek
Azure OpenAI
OpenAI
GitHub Models
Ollama
其他兼容 OpenAI 协议的模型服务
对业务代码来说,最好先只关心一件事:
我有一个 IChatClient,可以给它消息,它返回模型响应。
用 DeepSeek 作为第一例对国内开发者来说,DeepSeek 很适合作为入门示例。
原因很简单:
它容易申请和使用
成本相对友好
支持 OpenAI 兼容接口
很多现有 SDK 和框架可以复用 OpenAI 调用方式
所谓“兼容 OpenAI 接口”,可以先简单理解成:
代码仍然使用 OpenAI 风格的客户端,只是把 endpoint 换成 DeepSeek,把 model 换成 DeepSeek 的模型名。
例如最小代码可以这样写:
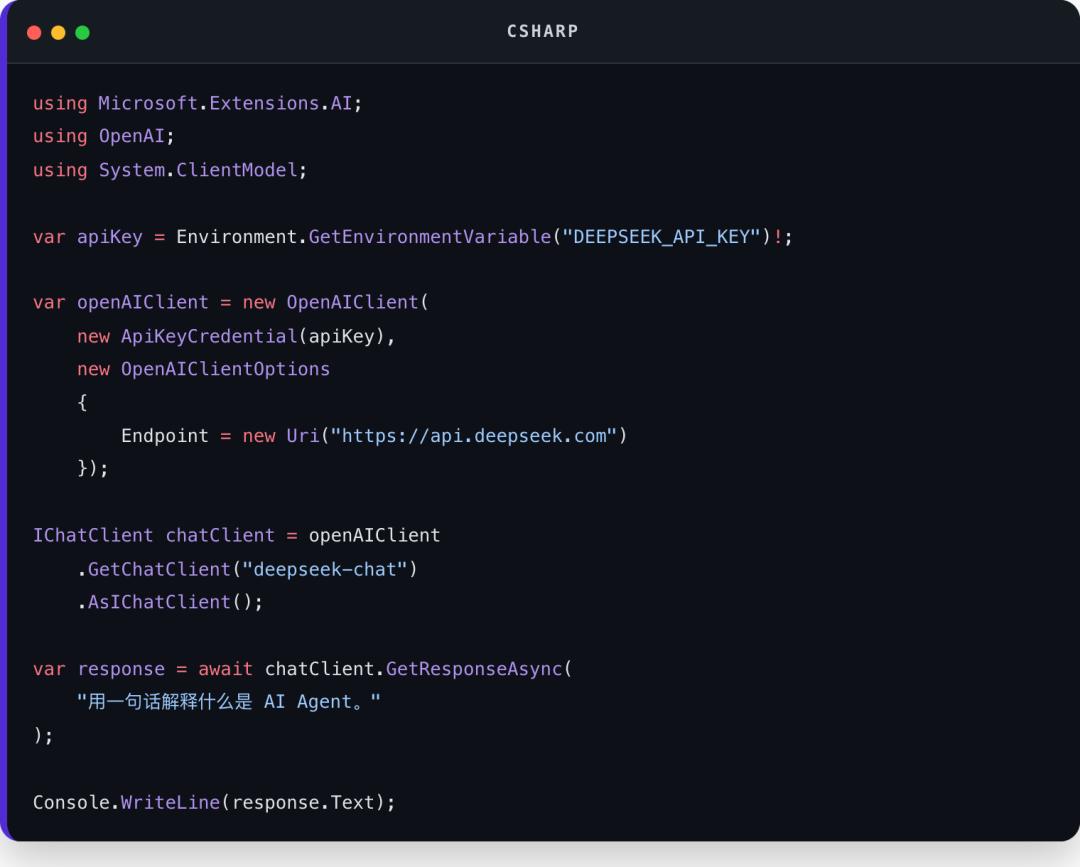
这段代码里有几个点很重要:
OpenAIClient仍然是 OpenAI 风格客户端
Endpoint改成了 DeepSeek 的地址
deepseek-chat是 DeepSeek 的通用对话模型
.AsIChatClient把具体客户端转换成 MEAI 的统一抽象
如果你要用 DeepSeek 的推理模型,通常只需要把模型名换成 deepseek-reasoner。
当然,“OpenAI 兼容”不代表所有高级参数、响应细节、工具行为都完全一致。
但对入门阶段来说,先跑通普通对话调用已经够了。
后面我们会演示 Function Calling。这里先提前提醒一句:DeepSeek 兼容 OpenAI 接口,适合演示基础对话和很多常见调用方式;但具体到工具调用、并发工具调用、流式工具调用等高级能力时,要以当前模型和 SDK 的实际支持为准。
如果某个兼容模型在工具调用上表现不稳定,可以先用 OpenAI 或 Azure OpenAI 验证机制,再回到兼容模型上做适配。
为什么先讲 IChatClient因为它会帮你把两件事分开:
业务上:这个 Agent 要完成什么任务
技术上:底层到底调用哪个模型
今天你可以先用 DeepSeek。
明天你可以换成 Azure OpenAI。
后天你可以接 GitHub Models 或本地 Ollama。
只要业务代码尽量围绕 IChatClient写,后面切换模型供应商就不会那么痛。
实际项目里当然还会有:
模型配置
API Key
Endpoint
ChatOptions
工具注册
流式响应
错误处理
观测日志
但第一天不要被这些细节压住。
先建立一个最小认知:
IChatClient 是模型能力进入 .NET 应用的统一入口。
三、Prompt:再把任务说清楚模型连上以后,下一步才是 Prompt。
Prompt 解决的是“怎么让模型按你的产品目标工作”。
很多人一开始会把 Prompt 当成一句自然语言指令:
请帮我生成一篇文章。
这当然也是 Prompt。
但对 Agent 产品来说,Prompt 更像是一个行为契约。

它至少要说清楚:
你是谁
你服务谁
你负责什么
你不负责什么
你应该如何提问
你应该如何输出
什么时候应该调用工具
什么情况下应该停下来等用户确认
继续沿用前面的写作助手例子。
如果它只是这样写:
你是一个写作助手,请帮助用户写文章。
这太宽了。
模型会不知道该直接写文章,还是先问问题,还是生成标题,还是开始调研。
更好的方向是:
你是一个写作助手。你的任务是先识别用户的写作意图:他想写什么、写给谁看、想解决什么问题。如果只是写作目标、读者、角度不清楚,就先提问;如果涉及不确定事实、近期趋势、外部资料或你不清楚的背景,再使用联网搜索工具补充信息。不要为了显得主动而乱搜,也不要直接生成完整正文。
这里最关键的不是文字变长了。
而是边界变清楚了。
落到 .NET 代码里,Prompt 通常不会只是一段孤立字符串,而是会变成一组带角色的消息:
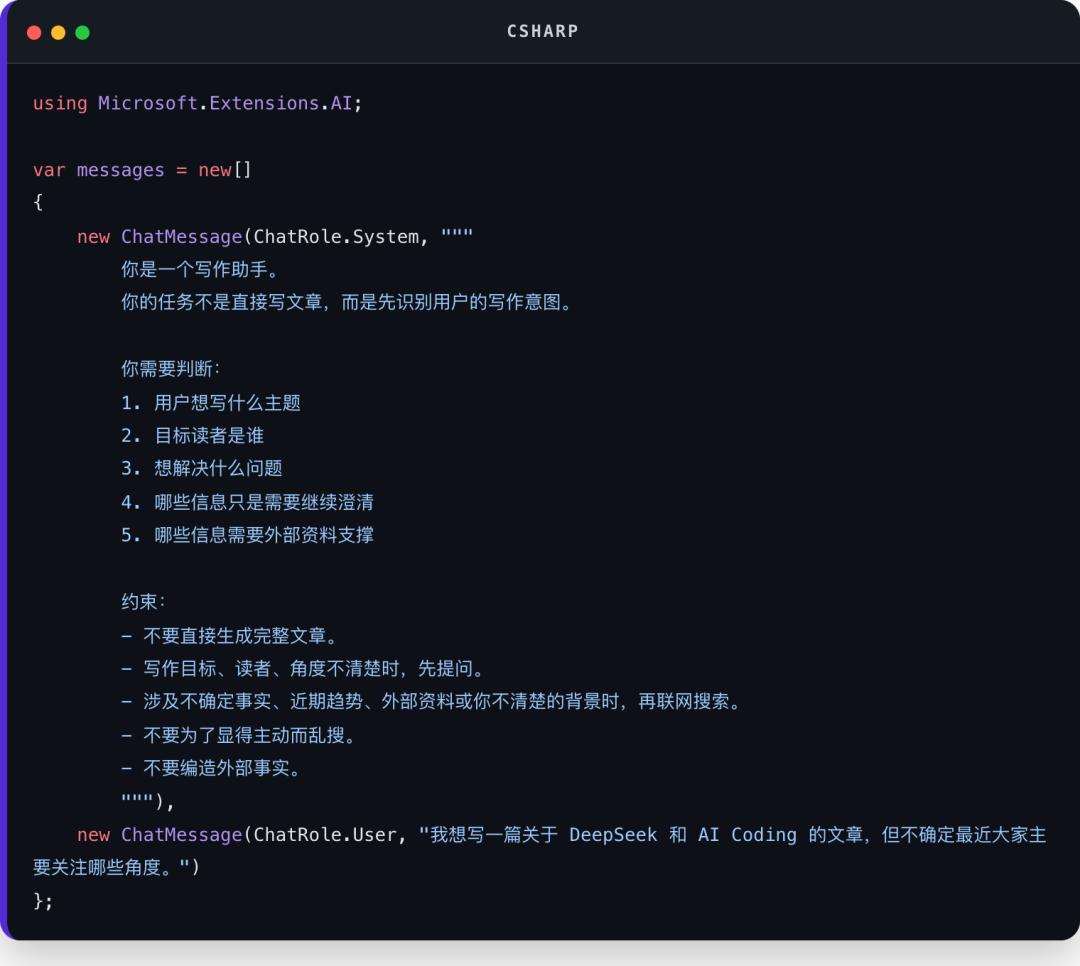
然后把这组消息交给刚才创建好的 IChatClient:

这段代码看起来很简单,但它已经体现了 Agent Prompt 的基本结构:
System消息定义角色、任务和边界
User消息提供当前输入
约束写在 Prompt 里,减少模型乱跑
Agent 的 Prompt,不是为了显得高级。
而是为了减少模型自由发挥的空间。
Prompt 的第一原则:先限制,再发挥很多人写 Prompt,喜欢强调“你要做什么”。
但 Agent Prompt 更重要的是写清楚“你现在不要做什么”。
比如:
不要直接生成完整文章
不要在用户确认前进入下一阶段
不要编造外部事实
不要把临时偏好写成长期记忆
不要把工具调用结果当成绝对真理
这听起来很啰嗦。
但这正是 Agent 产品化和普通聊天机器人的区别。
普通聊天机器人追求回答得像样。
Agent 追求在一个受控流程里持续推进任务。
四、Function Calling:让 Agent 不只是会说话如果一个 Agent 只能输出文本,它很容易变成一个“会说话的聊天机器人”。
但产品里的 Agent,通常需要做事。
比如 AI WritingFlow 里,一个 Agent 可能需要:
搜索资料
抓取网页
保存写作简报
读取用户偏好
写入文章草稿
生成封面图
更新工作流状态
这些能力不能只靠 Prompt。
你需要把外部能力暴露给模型。
这就是 Function Calling 或 Tool Calling 的价值。

你可以把它理解成:
我把一些函数注册给模型,模型在需要时可以选择调用它们。
比如概念上:
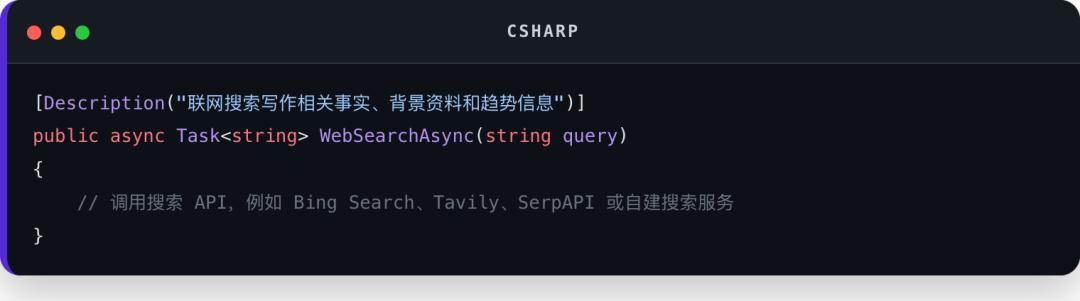
在 Microsoft.Extensions.AI里,可以把普通 C# 方法包装成模型可调用的工具。
下面是一个最小示例:
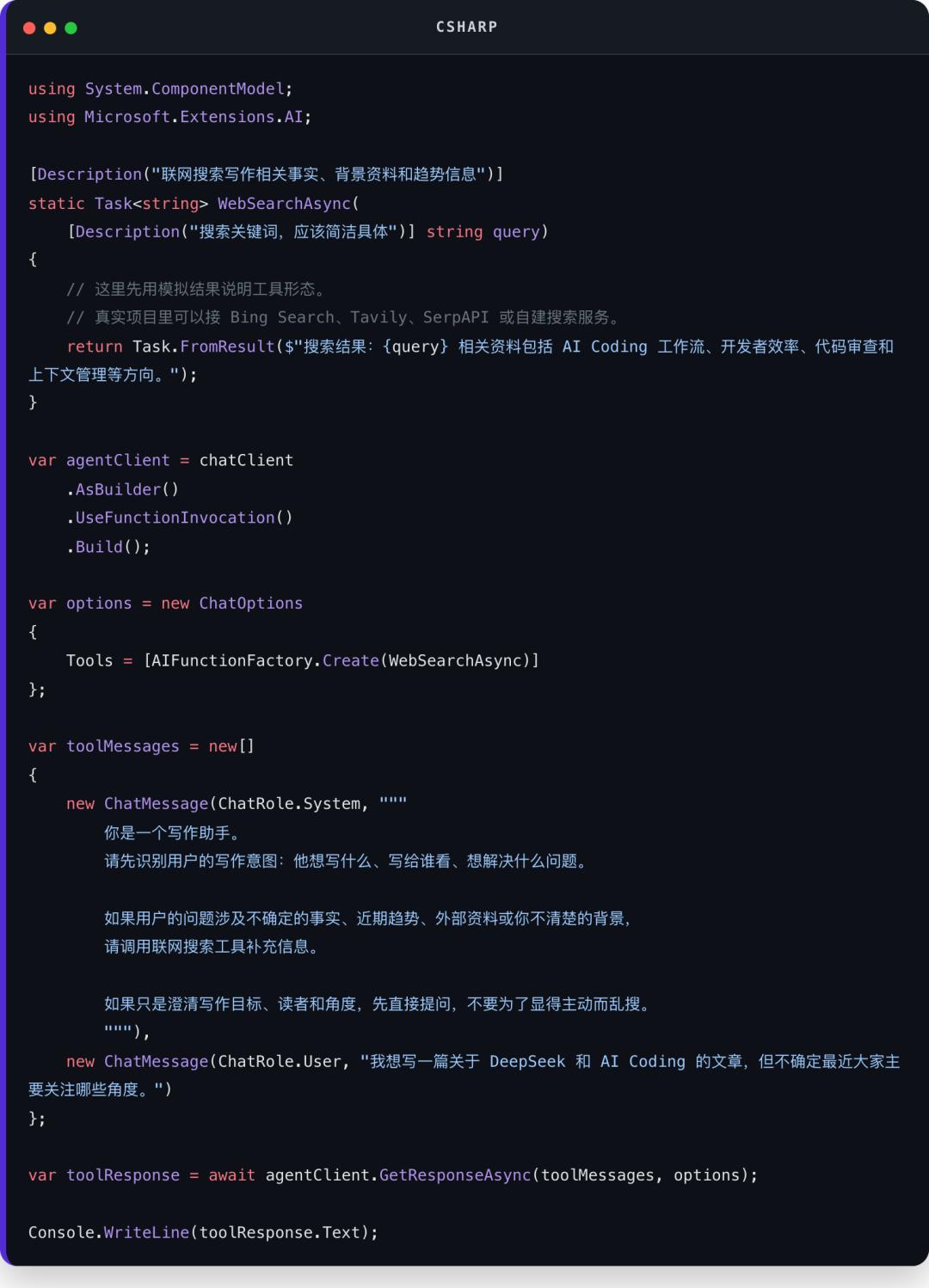
这里有几个关键点:
[Description]不是装饰品,它会帮助模型理解工具用途和参数含义
UseFunctionInvocation让工具调用可以被自动执行
ChatOptions.Tools控制这个 Agent 当前能看到哪些工具
Prompt 里要写清楚“什么时候调用工具,什么时候不要调用”
这一段演示的是 MEAI 层的直接模型调用:你仍然在直接使用IChatClient.GetResponseAsync(...),只是给这个模型调用增加了工具能力。
后面第六章会演示 MAF 层的 Agent 封装:同样基于IChatClient,但会用chatClient.AsAIAgent(...)创建一个真正的AIAgent,再通过RunAsync(...)执行任务。
可以先这样理解:
IChatClient是模型调用底座
GetResponseAsync(...)适合理解最小模型调用和工具调用
AIAgent.RunAsync(...)适合把提示词、工具、Skills、运行时上下文组织成一个角色来执行
模型看到这个工具以后,就可以在合适的时候调用它。
但这里有一个很重要的提醒:
工具不是越多越好。
第一版 Agent 的工具越多,模型越容易选错。
你也越难判断问题出在哪里。
所以早期工具设计要尽量小:
一个工具只做一件事
工具名字要清楚
参数要少
返回结果要可解释
不要把复杂业务流程塞进一个万能工具
工具的第一原则:让模型少猜坏工具通常长这样:

它什么都能做。
也意味着模型不知道它到底该什么时候用。
好工具更像这样:

它们边界更窄。
模型更容易判断。
人也更容易调试。
五、Skills:先认识可复用的专业能力如果说 Tool 解决的是“能做事”。
那 Skills 解决的是“会做得更像样”。
Tool 更像函数。
Skill 更像方法、经验、流程和领域规则。
换句话说:
Tool 偏执行:模型决定调用一个外部函数,拿到结果再继续生成
Skill 偏方法论:告诉 Agent 如何更专业地完成某类任务
Tool 解决“做什么动作”
Skill 解决“按什么方法做得更好”
继续沿用前面的写作助手例子。
WebSearchAsync是一个 Tool。
它解决的是:
当模型需要外部资料时,怎么真的去查一下。
但写作过程中还有另一类能力,并不适合做成函数。
比如:
什么时候应该在文章里加图
什么内容适合用流程图
什么内容适合用时序图
Mermaid 语法怎么写才不容易错
图表应该如何服务文章表达,而不是为了画图而画图
这些不是“执行一个动作”。
它们更像写作方法、表达经验和领域规则。
这类能力就更适合沉淀成 Skill。
比如可以引入一个现成的 Mermaid 图表 Skill:
https://www.skills.sh/softaworks/agent-toolkit/mermaid-diagrams
这个 Skill 的目标是帮助 Agent 创建专业的软件图表,使用 Mermaid 的文本语法生成 flowchart、sequence diagram、class diagram 等图表。
对写作助手来说,它的价值很直接:
当用户要写一篇技术文章时,Agent 不只是生成文字,还能判断哪些地方适合插入 Mermaid 图表。
比如:
解释 AI Coding 工作流时,用流程图
解释 Agent 调用工具时,用时序图
解释系统架构时,用组件图或 flowchart
解释状态流转时,用 state diagram
这比把所有 Mermaid 语法规则都塞进 Prompt 里更好维护。
你可以先通过 skills.sh 安装这个 Skill:

安装后,假设它位于本地 skills/mermaid-diagrams目录。
真实路径取决于你的 skills CLI 配置和项目结构,代码里按实际路径调整即可。
这一节先只需要理解:Skill 是一个可以独立维护、可以被 Agent 复用的能力包。
它通常包含:
任务目标
使用场景
输入要求
输出格式
示例
禁止事项
质量检查标准
这比把所有规则都塞进一个超长 Prompt 更可维护。
这也是 Skills 和普通 Prompt 的区别。
Prompt 更像当前 Agent 的角色说明。
Skill 更像可以复用、可以组合、可以替换的专业能力包。
但它能帮你先理解一个关键思想:
Skill 是可以被多个 Agent 复用的领域规则和操作方法,不一定一开始就要做成复杂运行时。
Skills 的第一原则:等重复出现后再沉淀不要第一天就写一堆 Skills。
因为你还不知道哪些能力真的会重复。
更稳的方式是:
先在 Prompt 里写清楚规则
连续几次发现同类规则重复出现
再把它抽出来变成 Skill
后续多个 Agent 共享这个 Skill
这和代码抽象很像。
不是看起来能复用就抽象。
而是重复真实出现后再抽象。
六、Agent:把模型、提示词、工具和 Skills 组织起来有了 IChatClient、Prompt、Function Calling 和 Skills,还不等于你有了一个清晰的 Agent。
Agent 更像是把这些东西组织起来后的“角色单元”。
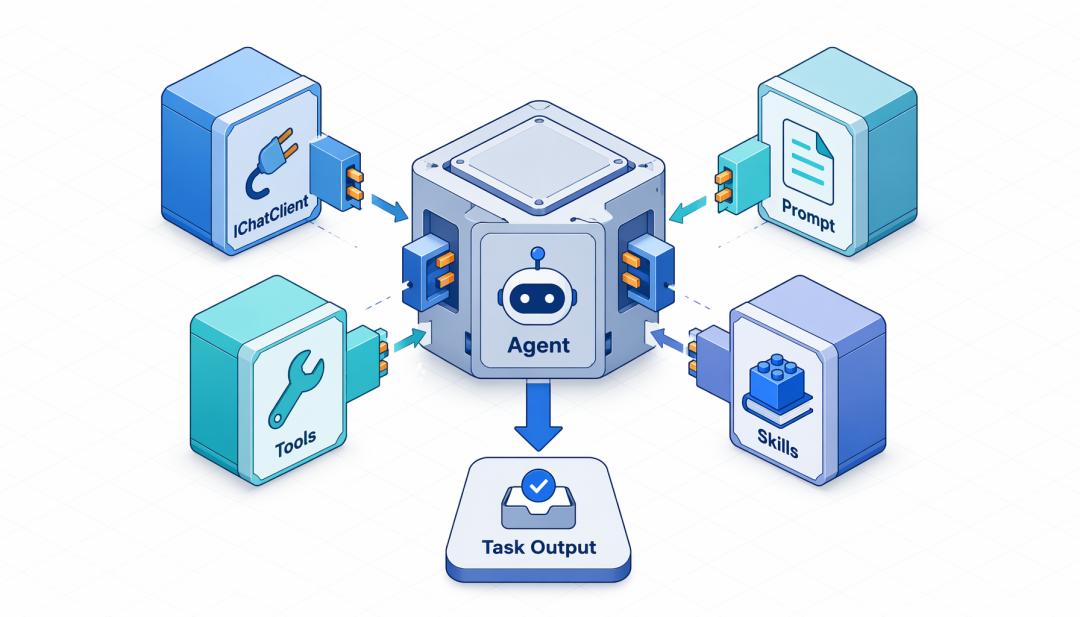
一个最小 Agent 通常包含:
名字
目标
系统提示词
可用工具
可用技能
运行时约束
输入输出约定
在 .NET 里,不需要自己先造一个 AgentDefinition类型来理解 Agent。
更自然的方式,是直接用 Microsoft.Extensions.AI提供模型与工具抽象,再用 Microsoft Agent Framework 把它包装成AIAgent。
这一节我们把前面的 WebSearchAsyncTool 和mermaid-diagramsSkill 一起接进同一个写作 Agent。
下面这个例子不是让你一开始就照搬完整工程结构,而是为了看清楚 Tool、Skill 和 Agent 在 .NET 里的组合关系。

这里的关系很清楚:
chatClient来自Microsoft.Extensions.AI,负责统一模型调用AIFunctionFactory.Create(...)来自 MEAI,负责把 C# 方法变成 Tool
AgentSkillsProvider负责把 Skill 提供给 Agent
AIContextProviders是 Agent 获取额外上下文能力的入口
chatClient.AsAIAgent(...)来自 Microsoft Agent Framework,负责创建真正的 Agent
agent.RunAsync(...)才是对这个 Agent 发起一次任务执行
这比一开始自己定义一套 Agent 元数据模型更适合入门。
先用框架最原生的方式跑通,再根据产品复杂度决定要不要做自己的注册、路由、配置和装配层。
以 AI WritingFlow 为例,Clarification Agent 和 Topic Agent 不应该只是两个不同 Prompt。
它们应该是两个职责不同的角色。
Clarification Agent 关注:
用户想写什么
为什么写
给谁看
想表达什么观点
还缺哪些信息
Topic Agent 关注:
哪些选题方向更值得展开
哪些方向有读者痛点
哪些方向更适合当前作者
哪些方向可形成文章结构
这两个 Agent 的目标不同,工具可能相似,但行为边界不一样。
如果你不把 Agent 职责写清楚,后面就会出现几个问题:
Clarification Agent 忍不住开始写正文
Topic Agent 忍不住开始润色标题
Draft Agent 忍不住重新选题
Polish Agent 忍不住重写整篇文章
这些不是模型“坏”。
这是角色边界不清。
Agent 的第一原则:少即是多第一版不要急着拆很多 Agent。
一个 Agent 能解决的问题,就先用一个 Agent。
当你真的发现:
目标不同
输入输出不同
工具集合不同
用户交互方式不同
失败处理方式不同
再考虑拆成第二个 Agent。
不要因为“多 Agent 听起来更高级”就拆。
拆 Agent 的目的不是炫技。
而是降低单个 Agent 的认知负担。
七、把 5 个概念串起来现在我们把这一课的 5 个关键词串起来。
一个最小 Agent 可以这样理解:
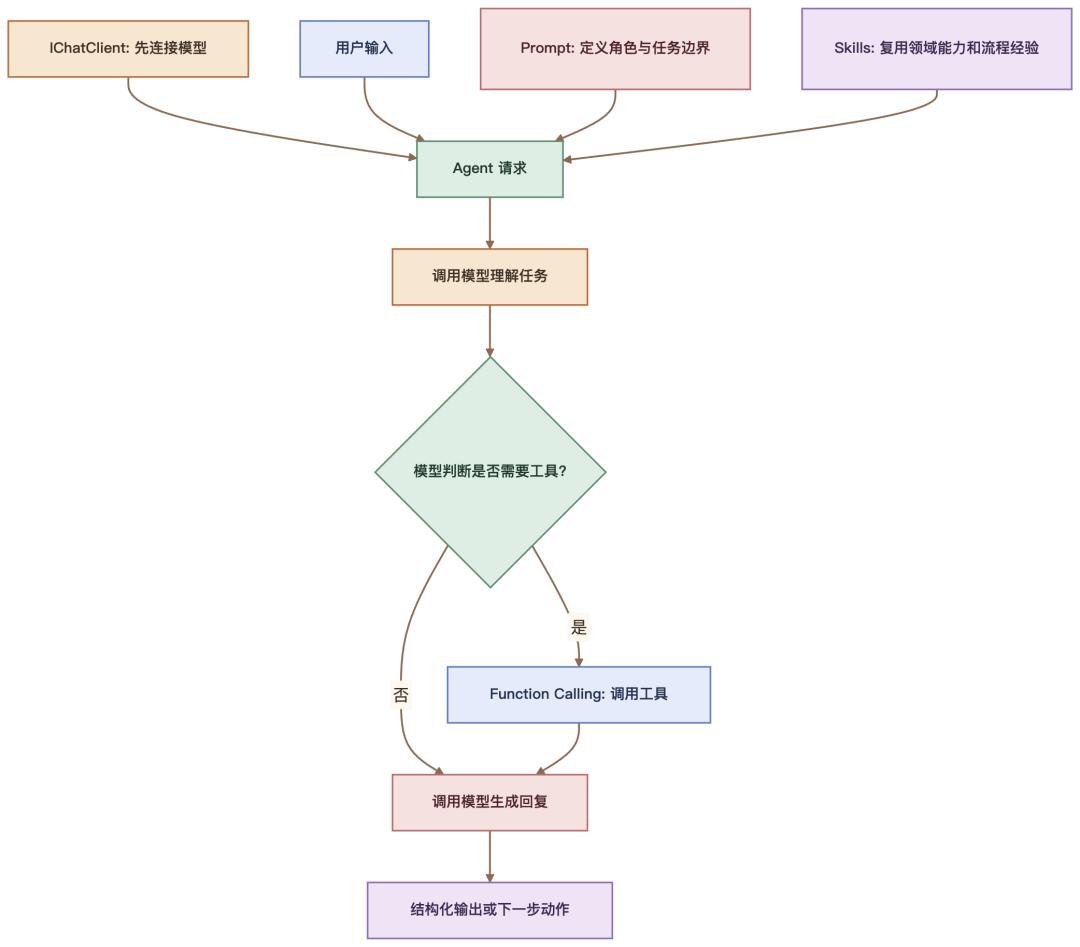
用一句话说:
IChatClient 先把模型能力接入 .NET,Prompt 定义行为边界,Function Calling 让模型能调用外部工具,Skills 沉淀可复用专业能力,Agent 最后把这些组织成一个清晰角色。
这就是第一个 Agent 的最小知识闭环。
你不需要一开始就懂完整 Agent 架构。
你只要先能用这 5 个概念解释清楚一个 Agent 是怎么跑起来的,就已经可以开始做第一版了。
八、AI WritingFlow 的第二课结论如果回到 AI WritingFlow,第二课的结论很明确:
第一版不需要一口气做完完整写作工作流。
也不需要一开始就设计多 Agent 协作系统。
我们只需要先做出一个很小的 Agent:
用户输入一个模糊写作想法,Agent 先根据 Prompt 识别写作意图,通过 IChatClient 调用模型;当涉及不确定事实、近期趋势或外部资料时,模型可以调用 WebSearchAsync补充信息;当文章内容适合可视化表达时,Agent 可以参考mermaid-diagramsSkill 生成合适的 Mermaid 图表,最后输出一个更清晰的写作角度或小节规划。
这里面已经包含了最小 Agent 所需的核心能力:
IChatClient:完成模型调用
Prompt:定义写作助手的行为边界
Function Calling:连接联网搜索等外部能力
Skills:沉淀 Mermaid 图表写作这类可复用专业能力
Agent:把模型、提示词、工具和 Skills 组织成一个明确角色
这就够了。
第一版不要追求完整。
先追求跑通。
跑通以后,再看真实问题在哪里。
九、课堂练习请基于你自己的 Agent 产品想法,完成下面 5 个问题。
练习 1:给你的第一个 Agent 起名字不要叫 MainAgent。
名字要体现职责。
示例:
Writing Assistant Agent
Topic Discovery Agent
Research Assistant
Draft Coach
Code Review Agent
练习 2:写一句 Agent 目标模板:
这个 Agent 的目标是帮助【目标用户】完成【一个明确任务】,并产出【一个可见结果】。
示例:
Writing Assistant Agent 的目标是帮助内容创作者识别写作意图,必要时联网补充资料,并产出可继续展开的文章角度。
练习 3:写 3 条“不做什么”示例:
不直接生成完整文章
不在用户确认前进入选题阶段
不编造外部事实
练习 4:列出最多 3 个工具第一版最多 3 个。
示例:
搜索资料
抓取网页内容
读取用户偏好
如果你列出了 10 个工具,说明你的第一版可能太大了。
练习 5:判断是否需要 Skill问自己:
这个能力是否已经重复出现?是否值得多个 Agent 复用?
如果答案是否,那就先不要抽成 Skill。
先放在 Prompt 里。
十、本课小结这一课我们只建立了 Agent 的最小知识闭环。
你需要记住 5 件事:
IChatClient 是模型能力进入 .NET 应用的统一入口
Prompt 不是一句指令,而是 Agent 的行为契约
Function Calling 让 Agent 从“会说话”变成“能做事”
Skills 是等稳定能力重复出现后,再沉淀出来的复用机制
Agent 是把模型、Prompt、工具、Skills 和约束组织起来的角色单元
下一课我们会进入技术选型:
为什么对 AI WritingFlow 来说,.NET Minimal API、Microsoft Agent Framework、EF Core、SQLite、React、Tailwind、shadcn/ui 是一套够快、够稳、也适合 AI Coding 协作的组合。
但在进入技术选型前,先别急。
请先把你的第一个 Agent 定义清楚。
一个职责清楚的小 Agent,比一个边界模糊的大系统更有价值。
课后作业请写一页纸,不超过 600 字,包含:
第一个 Agent 的名字
这个 Agent 的一句话目标
这个 Agent 的 Prompt 边界:做什么 / 不做什么
第一版最多 3 个工具
暂时不做的 5 个高级能力
如果你写完以后发现这个 Agent 仍然什么都想做,那就继续砍。
砍到它只负责一个最小闭环为止。