阿里发布开源图像大模型 Qwen‑Image:文字可嵌图、中文精度领先
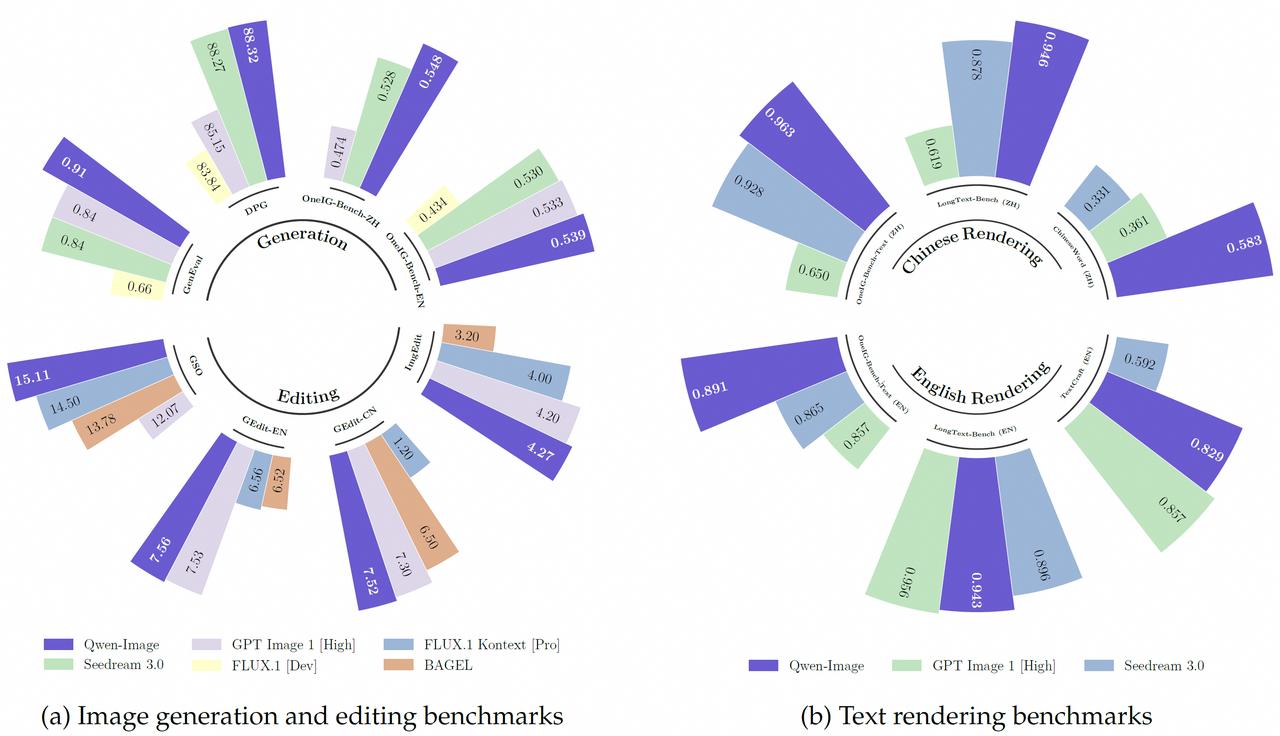
日前阿里 Qwen 团队正式发布开源图像模型 Qwen‑Image,参数规模 20B,重点强化“文字渲染能力”与图文理解能力,已上线 HuggingFace 与 ModelScope 平台。该模型基于 MMDiT 架构,定位多任务视觉语言模型,可用于图像生成、风格迁移、对象编辑、姿态操控等多种场景。
核心亮点:
· 支持复杂中英文字体原生嵌入图像,非简单覆盖,尤其在中文海报/文生图场景下,表现显著优于现有开源模型;
· 拥有基础图像生成能力,能精准控制布局、语义、风格,已在 LLaVA-Bench 等多个 benchmark 拿下 SOTA;
· Apache 2.0 免费开源,可商用,模型权重与推理代码已全量公开。
Qwen‑Image 背靠 Qwen-VL 视觉语言架构,具备一定语言理解与图像推理能力,不只是画图,还能“理解指令”与“编辑细节”,对开发者来说更像一位能沟通的图像设计助手。
Qwen‑Image 本质是对开源社区图像能力的升级补足,尤其解决了中文语义与图文嵌套长期被忽略的问题。未来若后续开放图像编辑能力,商业部署价值会更高,适合投放、设计、教育出版等行业快速接入。
但当前推理效率仍依赖大模型算力,对轻量应用场景还不够友好。实际落地仍看社区优化与硬件部署进展。
🟦 你会考虑用 Qwen‑Image 做哪类图像生成?
数码真相集 图像生成 开源模型 国产ai