昨天Google I/O发布会,热度还是挺高的,我们的发布会总结文章也10万+了。
全网都在聊Gemini 3.5,聊Gemini Omni等等。
但是有一个小东西,是我觉得可以拎出来单独写一篇的,因为我觉得这个东西可能比其他的所有新模型新功能,对于大众和我们这些普通人的影响,都要重要。
那就是,OpenAI官宣选择与Google合作,接入Google SynthID,完善AI图片检测链路,然后推出了一个AI图片检测的工具,来强化内容溯源,尽可能用最低的成本,让每一张AI生成的图片,都可以被识别出来。

关注我比较久的老粉丝可能都知道,我非常非常关注这一块的东西。
上个月GPT-image-2刚上线的时候,我写过一篇文章,叫
那篇文章里我说了一个判断,就是当造假的成本趋近于零,且没有有效的识别手段的时候,信任的成本就趋近于无穷大。
然后过去其实还写过一些这样的社会现象,比如去年双十一写的
很多的商家,可能万万没想到,现在的薅羊毛的买家,会恶心到,直接用AI来P图,然后发一张残次品的图片过去,跟买家申请仅退款。
比如这个。

商家放大一看。
一脸懵逼的发现,哥们甚至水印都忘了P掉。

有商家就一脸懵逼的收到了鞋子的退款。

然后点开详情图一看。
得,又是一个忘记裁掉水印的。

商家直接飞龙骑脸问,是豆包弄的?

对方还振振有词:

这都是去年双十一,发生的真实案例。
而且要知道,这都是去年的技术了,如果是今年的GPT-image-2,那个造假的逼真程度,不要说很多的普通用户,我坦诚的讲,我自己看了这么多图片,我自己也生了这么多图片,但是我也没有任何信心,可以确切的评估一张图是不是AI造假的。
就比如这种东西。

所以,当OpenAI和Google这两死对头决定合作,选择把Google SynthID图像水印也引入到GPT-image-2里面去,然后推出一个OpenAI自己做的AI图片检测工具的时候,我觉得未来的互联网黑暗森林,还是有救的。
网站在此:
https://openai.com/zh-Hans-CN/research/verify/

无需登录,直接把图扔进去就可以了。
扔进去以后就会开始验证。

大概等个几秒钟,就会出来验证结果。
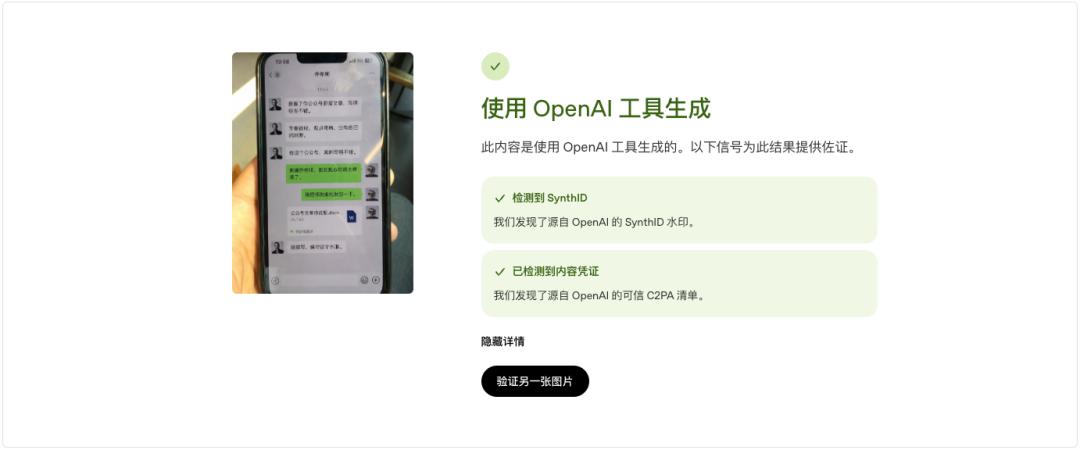
并且我测试了一些常见方法,比如发送到微信里,重新保存,依然还是会被检测出来。
甚至我直接局部截图然后改掉格式,再发到微信里重新保存,再扔到检测网站里,依然显示还是由AI生成的。

小红书上的帖子,我直接截屏扔进去,也可以识别出来。

同时,一些看着很离谱的像AI生成的真实照片,也不会被误测。
比如这张照片。

看着就非常的像AI,但其实不是的。
这是蒙特利尔艺术团队The Dorothy Project发起的名为Mission TARONI的艺术项目。艺术家与工程师一起合作,使用高空气球将一个包裹着深蓝色丝绸的人体模特送入了距离地面约33至35公里的平流层。
然后在设备舱上安装了Insta360,全方位记录下了这个蓝色身影在黑色宇宙背景、地球弧线与白云之间共舞的震撼画面。
你把这张图扔到网站里面之后。

OpenAI为了保险,其实不太敢直接说这不是AI生成的,所以说的还是未检测的OpenAI信号,目前也只判断是不是OpenAI自家的GPT-image-2生成的。
我测试了把NanoBanana生成的图片扔给OpenAI检测,其实也会显示未检测到OpenAI信号。

只能在Gemini自己的产品里去检测,才可以。
比如我还是直接局部截图然后微信保存再扔过去,也是可以被Gemini检测出来的。

所以大家手段其实都有,只是目前处于一个时代的进程中,老的图像模型等等问题还是比较多,大家也还比较分散,没有形成一个统一的集合体。
目前那个网站也是,只能验证OpenAI自己生成的图片,但OpenAI说了,后续会扩展到跨行业验证,也就是说,其他AI公司生成的图,只要也接入了同样的标准,也能查。

我可能未来也会做一个公益的小东西,接入这些平台,来帮大家进行遍历检测,不过会复杂一点,因为还需要考虑前几代AI图片模型的检测。
不过在这个时代,未来C2PA元数据+Google SynthID水印的方式,确实几乎可以让绝大多数的AI图片,无所遁形了,虽然还是有办法去除,但是成本还是会比较高的。
目前的技术栈和架构大概是这样的。

也给大家简单科普一下C2PA元数据+Google SynthID水印这两个名词,到底是个啥东西。
首先是C2PA元数据。
这玩意的全称叫Coalition for Content Provenance and Authenticity。

翻译成人话就是内容来源和真实性联盟。
它是一个跨行业的开放技术标准,2021年成立的,什么Adobe、微软、Google、BBC、索尼、Intel这些公司都在里面。
它做的事情,用一句话概括就是,给每一张图片发一张证明。
这个证明在技术上叫C2PA Manifest,翻译过来的话,可能清单的意思稍微准确一点。
这个清单里面,一共放了三层数据。
第一层叫Assertions,这是一组关于这张图的声明,比如「这张图是由ChatGPT生成的」「生成时间是2026年5月19日」「使用的模型是gpt-image-2」等等。
当然如果是AI的就是上面那些,如果是相机拍的照片,Assertions里面就会是「这张图是Nikon Z9拍摄的」「GPS坐标是xxx」「光圈f/2.8快门1/500」这些信息。
第二层叫Claim,就是把上面这些玩意打包在一起,形成了一个完整的声明。
第三层叫Claim Signature,大概就是签名的意思,这一步会用生成这张图的那个软件或硬件的私钥,对整个声明进行加密签名。同时会对图片本身做一次哈希运算,把图片内容和清单绑在一块。
这个签名其实就是防造假,如果有人事后篡改了图片的哪怕一个像素,哈希值就对不上了,验证的时候就会报错。
然后这整个清单会被打包成一个叫JUMBF的容器格式,直接嵌入到图片文件里面,你用肉眼看这张图,什么都看不出来,但是用C2PA的验证工具打开,就可以看到所有的过去的一些信息了。

大概就是这样,这套东西OpenAI从2024年就自己在开始做了,最早是给DALLE 3加的,后来给Sora也加上了,这次的升级是,OpenAI正式成为了C2PA的合规生成器产品,也就是说,其他平台可以标准化地读取、保留、传递OpenAI附加在图片上的这些加密元数据了。

而且其实不只是AI公司在搞这个,相机厂商也在搞。
Leica的M11-P,2023年就成为了全世界第一台支持C2PA的量产相机。

你拿这台相机拍一张照片,快门按下的那一刻,相机就会自动往JPEG文件里嵌一个C2PA清单,用Leica自己的证书签名。Nikon的Z9和Z8也在2024年通过固件更新加了C2PA。
再后来Sony、Canon啥的也都跟进了,Google的Pixel 10甚至是第一款默认给所有照片都打C2PA签名的消费级手机,用的是Titan M2安全芯片的硬件级密钥。
未来大概率就会形成了一个双向的体系,AI生成的图有标签,真实拍摄的照片也有标签,截图其实也可以有标签,这些的溯源,我感觉还是会有必要的。
因为现在去除C2PA还是比较简单的,但是篡改很难,所以如果未来的世界,一切的内容都有C2PA,那其实反而是,谁没有标签谁尴尬。
不过那毕竟是未来,在这个阶段,单独的C2PA还是不够的,所以OpenAI这次才原则跟Google合作,把SynthID也引入进来了。
SynthID是Google DeepMind搞的一个技术,2023年就有了,但一直在Google自己的体系里用。这次Google I/O上,Pichai就宣布了,SynthID要扩展到Google搜索和Chrome浏览器里,而且,OpenAI、Nvidia、Kakao、ElevenLabs等等,都要接入。

如果非要用一个比喻去来说C2PA和SynthID的区别,那我觉得就是,C2PA是给你贴了个外部标签,SynthID是直接往你的DNA里直接写东西。
SynthID 会在 AI 生成的图像(或视频片段)中添加一个不可见的数字水印这个水印不会改变图像或视频的质量。
它会在内容创建的瞬间添加,设计上能够抵抗裁剪、添加滤镜、更改帧率或有损压缩等修改。
整个工作原理其实非常的硬核,我尽可能简单描述一下。
就是当你在AI生成图片的那一刻,会有一个嵌入器开始工作。它会在图像的频率分量和颜色通道上做极其细微的调整,调整的幅度在人眼感知的阈值之下,你肉眼看到的图和没有水印的图,完全一模一样。
但这些调整在数学上是有意义的,它们构成了一种分布在整张图上的隐形签名。

关键在于这个签名的分布方式。它不是像传统水印那样只是集中在某个角落或者某一块区域,会弥散在整张图片的每一个部分。
所以你裁剪掉任何一个区域,剩下的部分依然包含足够的信号。你压缩、加滤镜、调色、旋转、截图、转格式,水印都还在。
然后会有一个对应的检测器来专门识别这些隐形的签名,非常的准。
而且他们之前还发过一个用SynthID来给AI生成的文字打水印的论文,不过比较早了,2024年。

之前我就在那个黑暗森林文章里面提过,SynthID一直是我认为最好的AI检测效果的方式,不过之前最大问题就是只有Google他们自己玩。
现在,OpenAI带头表率,加入生态,我觉得这个信号本身,就是一个非常重要的事。
未来可以预期到,有越来越多的厂商,会加入这个生态里面去,因为你只要做多模态,你就逃不开内容追溯的问题。
最后,我想用OpenAI在Blog中说的话来结尾。
没有任何单一的内容溯源技术能够孤军奋战。
同样的,整个互联网的生态,在AI的冲击之下。
也没有任何单一的公司,能够孤军奋战。
OpenAI和Google今天做了一个好的表率。
接下来,就看其他人了。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
/ 作者:卡兹克
/ 投稿或爆料,请联系邮箱:wzglyay@virxact.com