[CL]《Large Language Model Hacking: Quantifying the Hidden Risks of Using LLMs for Text Annotation》J Baumann, P Röttger, A Urman, A Wendsjö... [Bocconi University & University of Zurich] (2025)
LLM黑客现象揭示自动文本标注中的潜伏风险,挑战社会科学研究的可靠性与科学性。
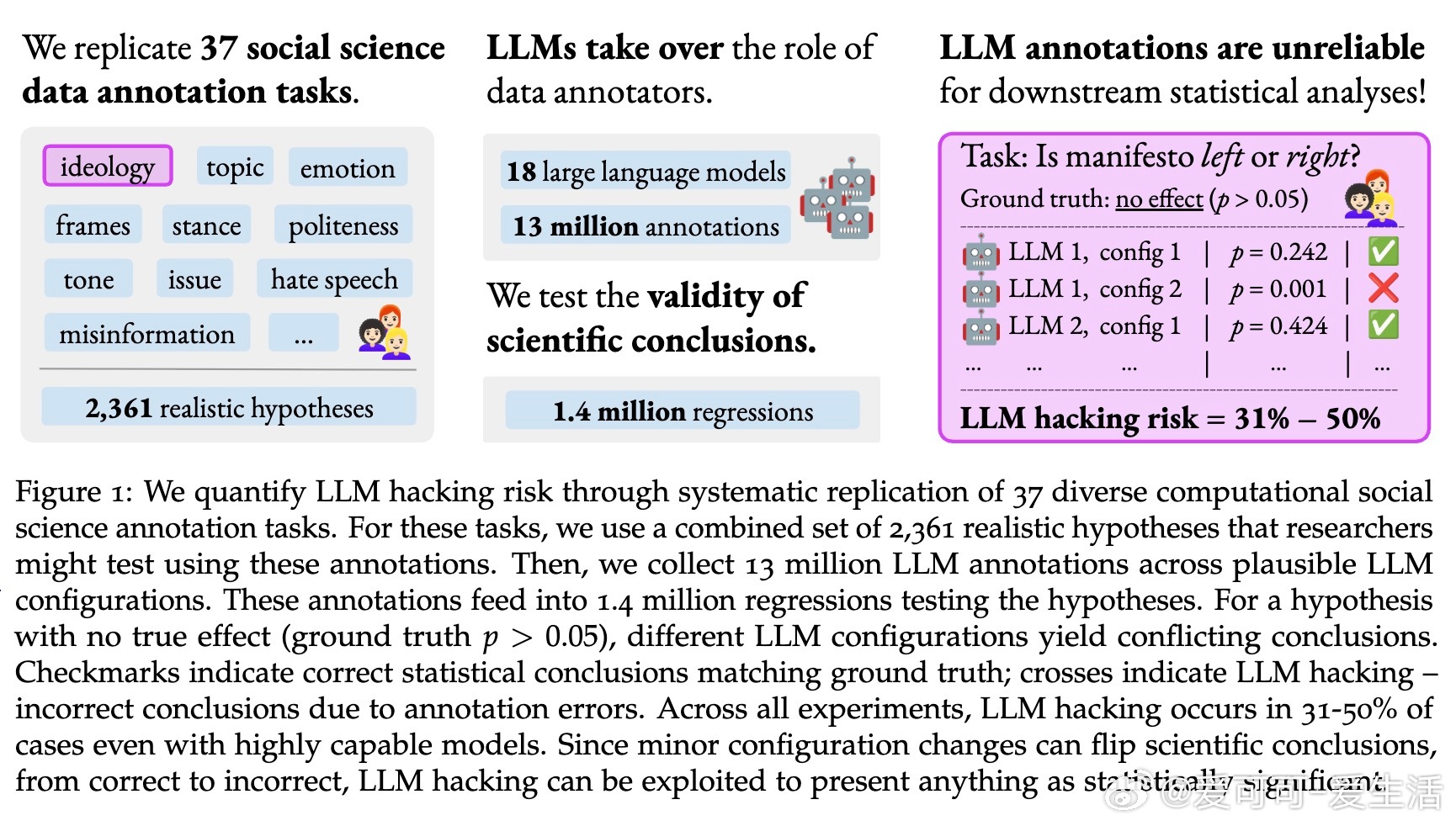
• 实证分析覆盖37个社会科学文本标注任务,使用18款大语言模型(LLM),生成逾1300万条标注数据。
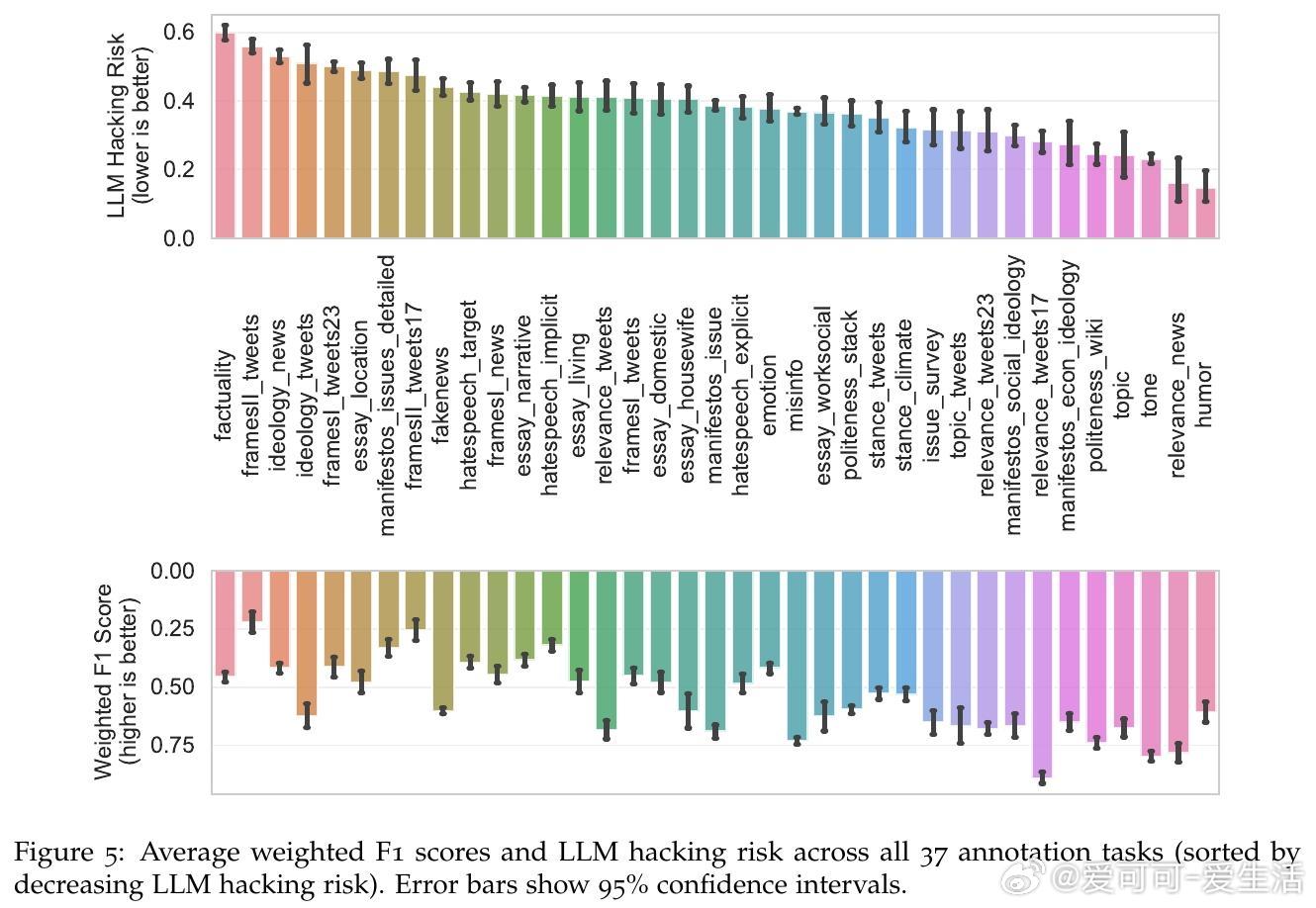
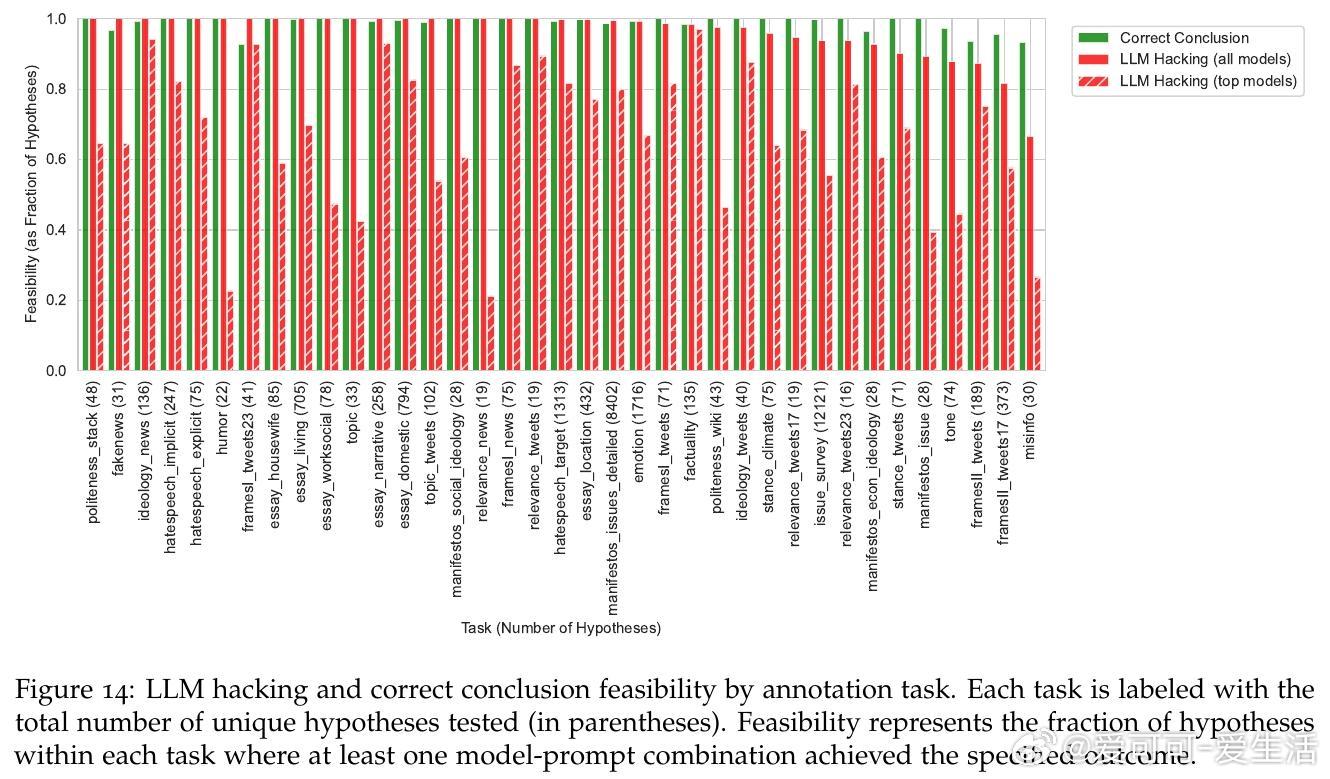
• 研究发现,基于LLM的标注导致约三分之一的假设检验结果错误,高达50%的错误率出现在小规模模型中。
• LLM黑客指配置选择(模型、提示设计、温度设置等)引发的统计结论偏差,既包括无意误差,也可被故意操控制造假阳性、假阴性、效果方向颠倒等问题。
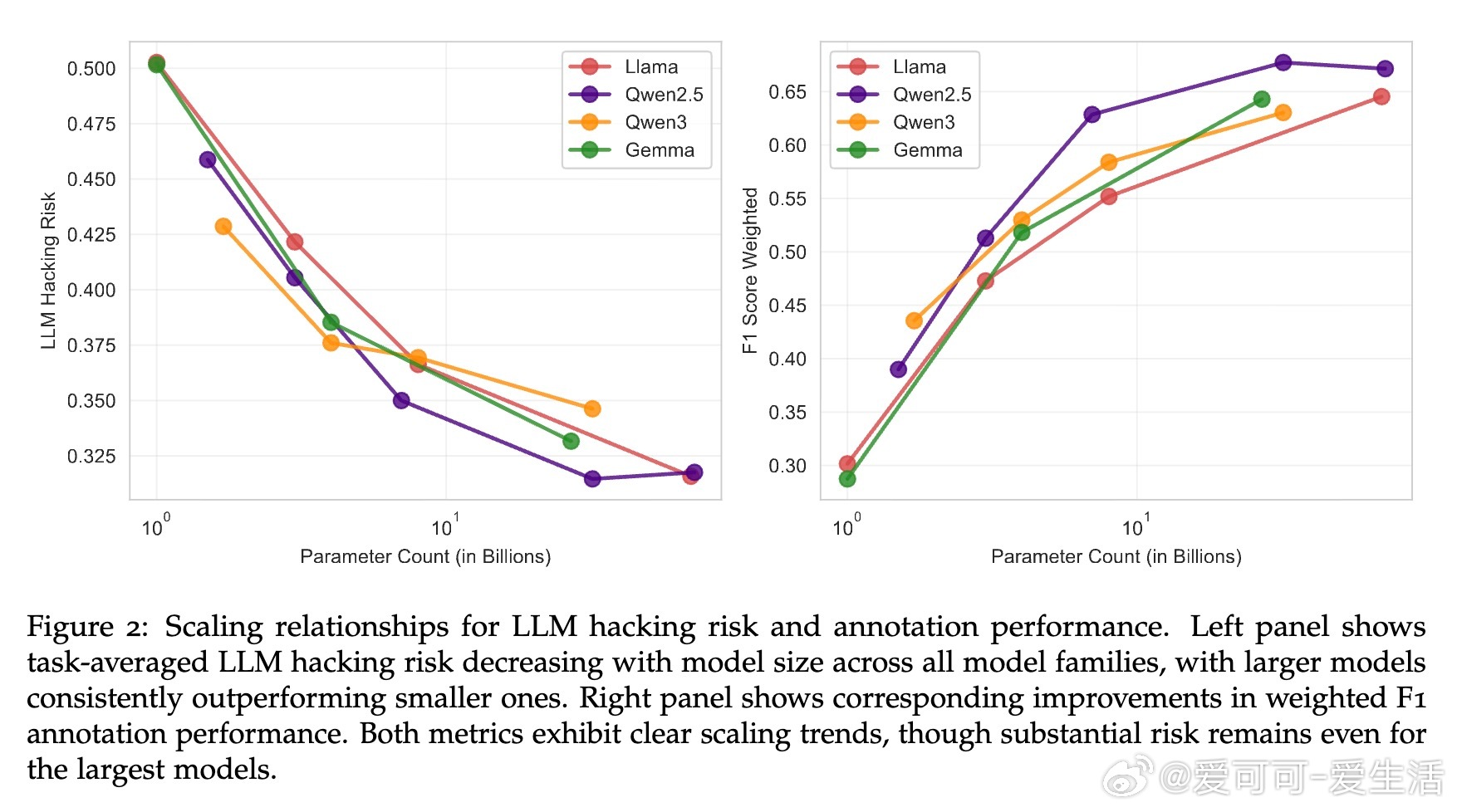
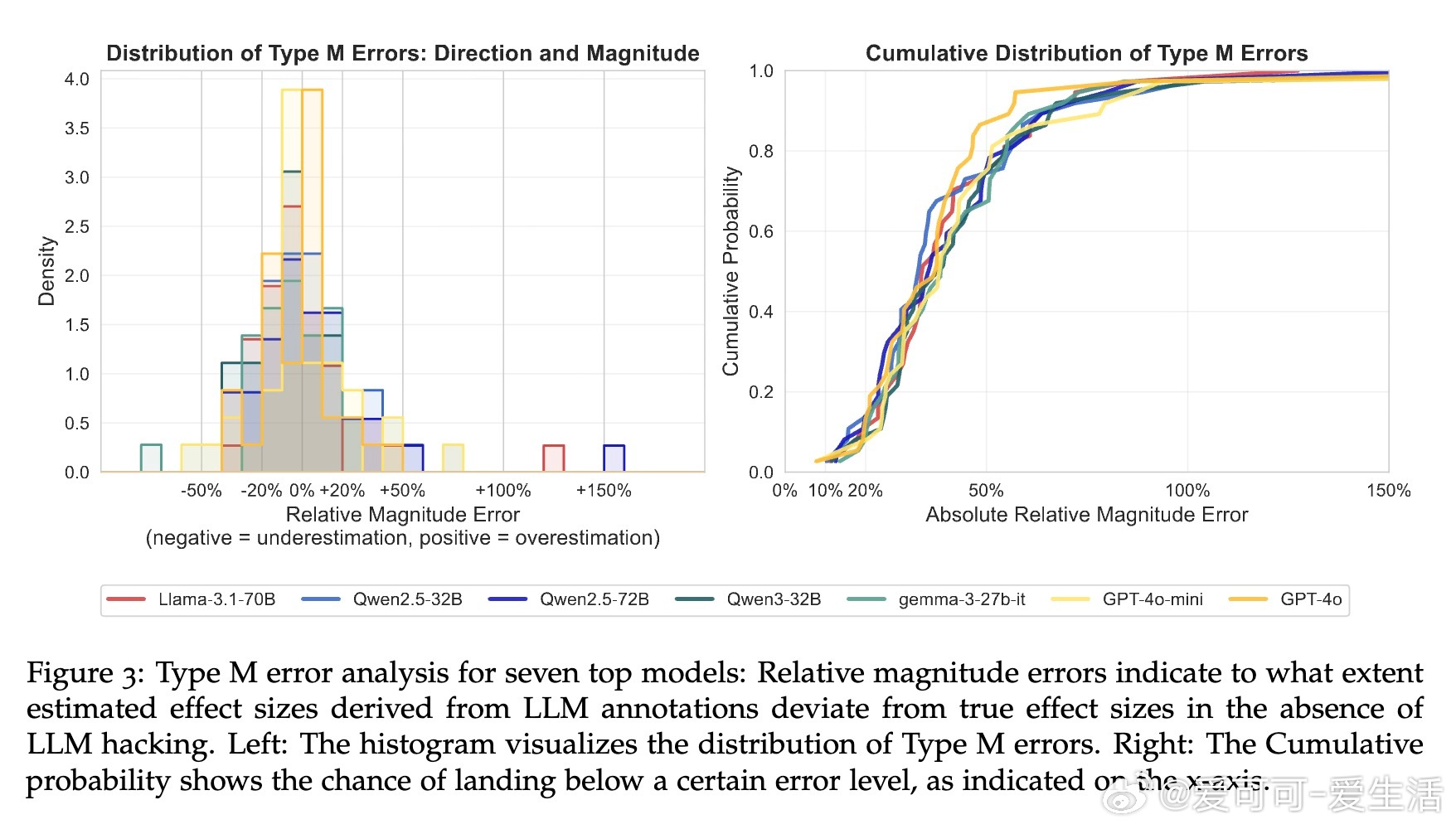
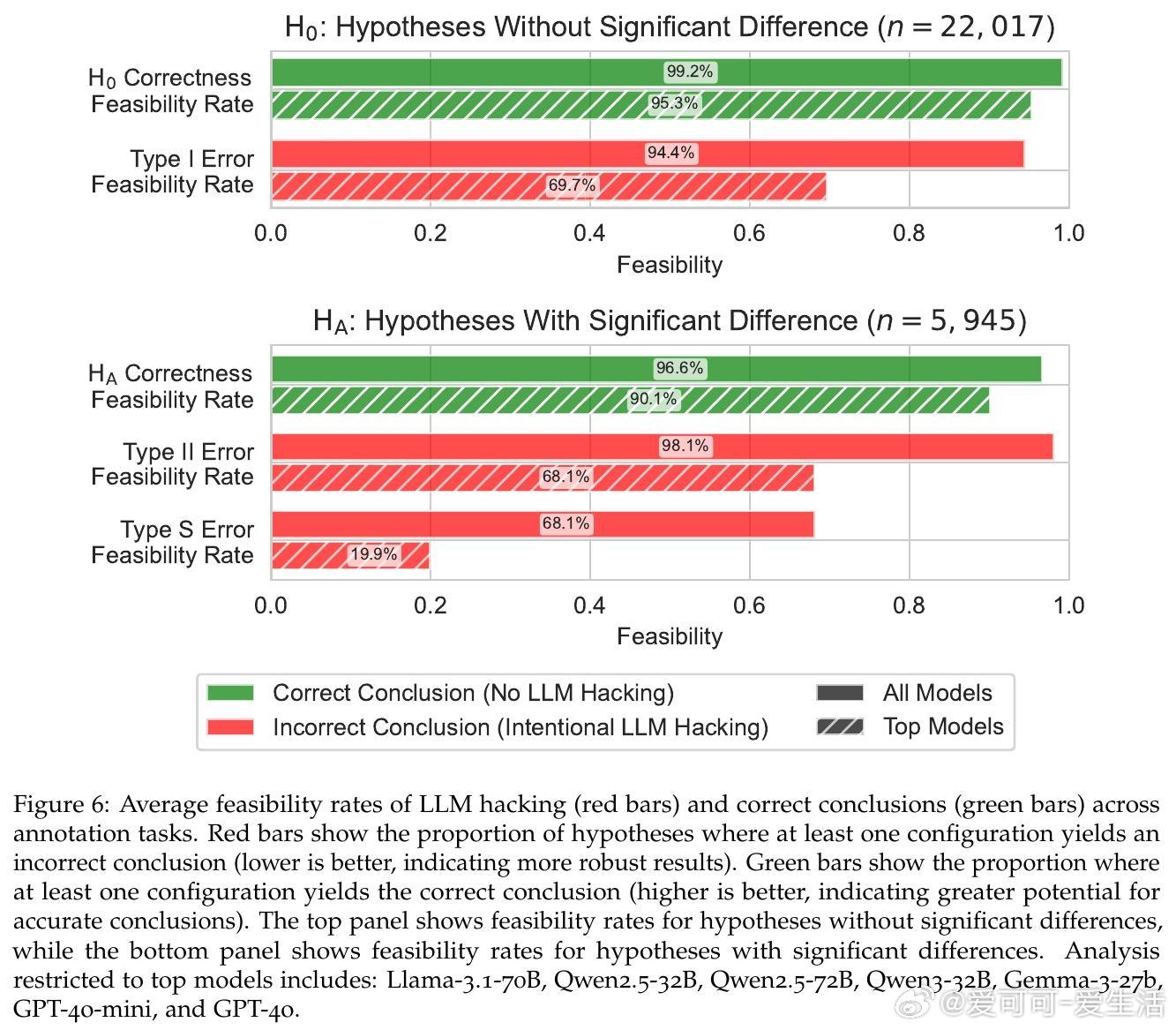
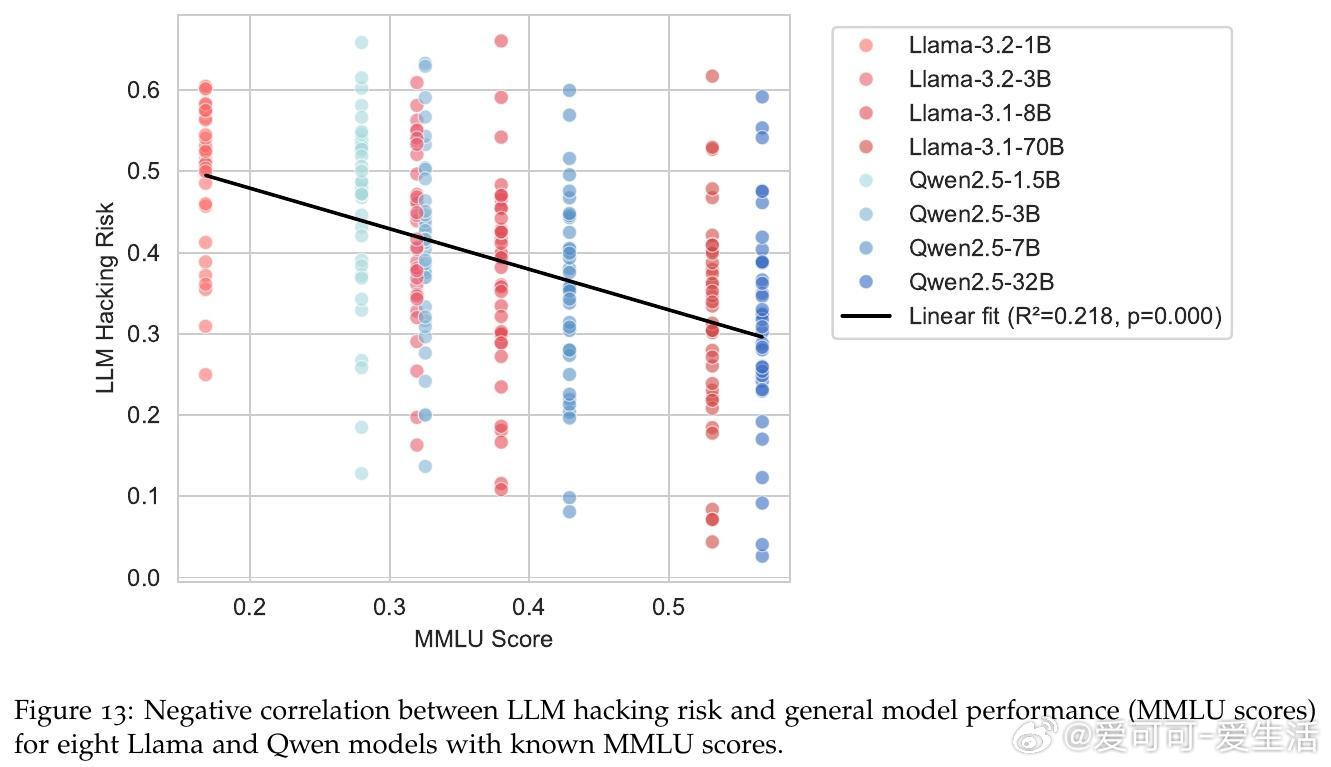
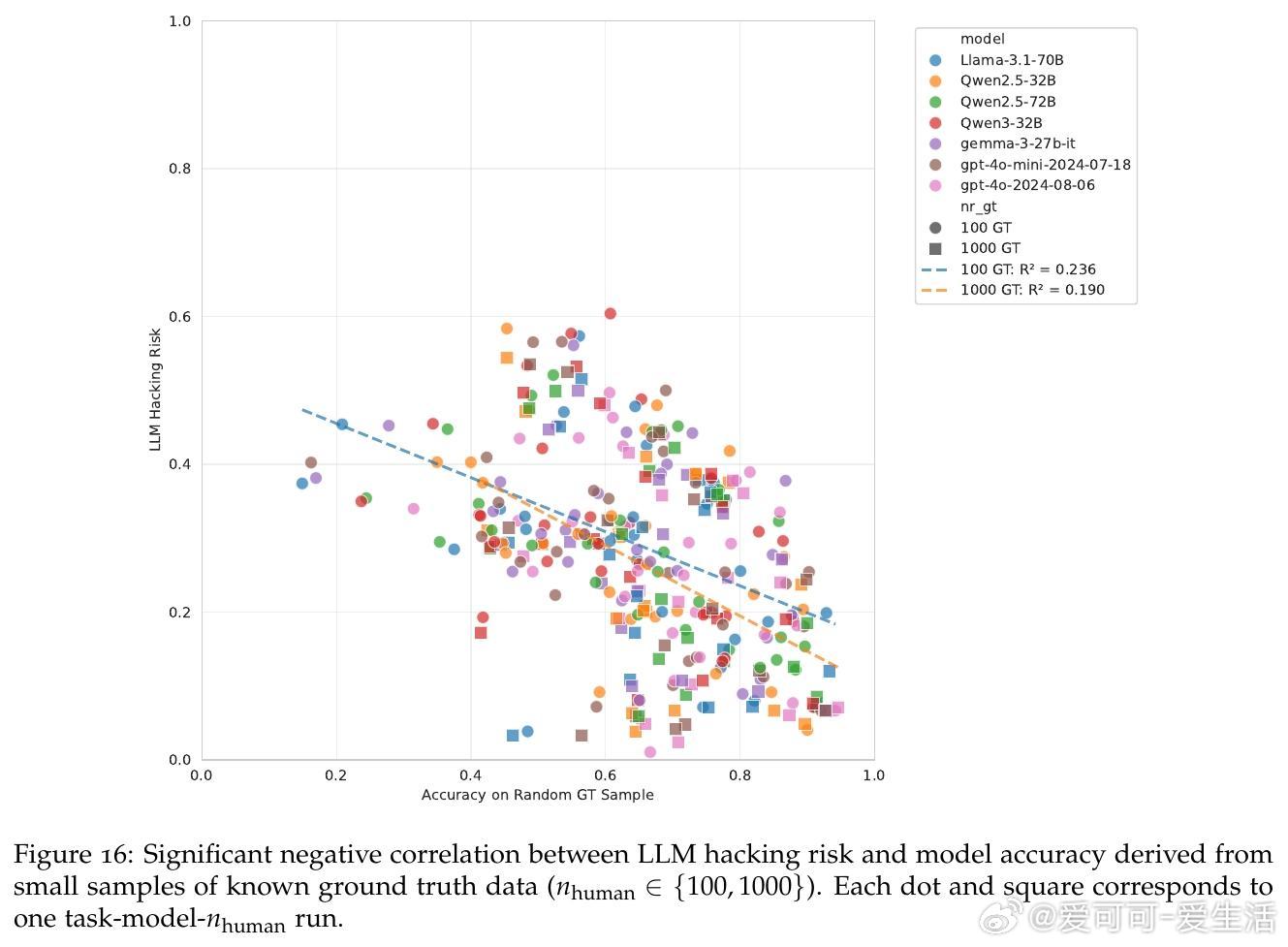
• 错误类型以漏检真实效应(Type II)居多,且即便是顶尖模型也无法完全消除风险,表明高准确率并非万灵药。
• 近显著性阈值(p≈0.05)处错误率飙升至70%,提示研究需对边缘结果加倍谨慎。
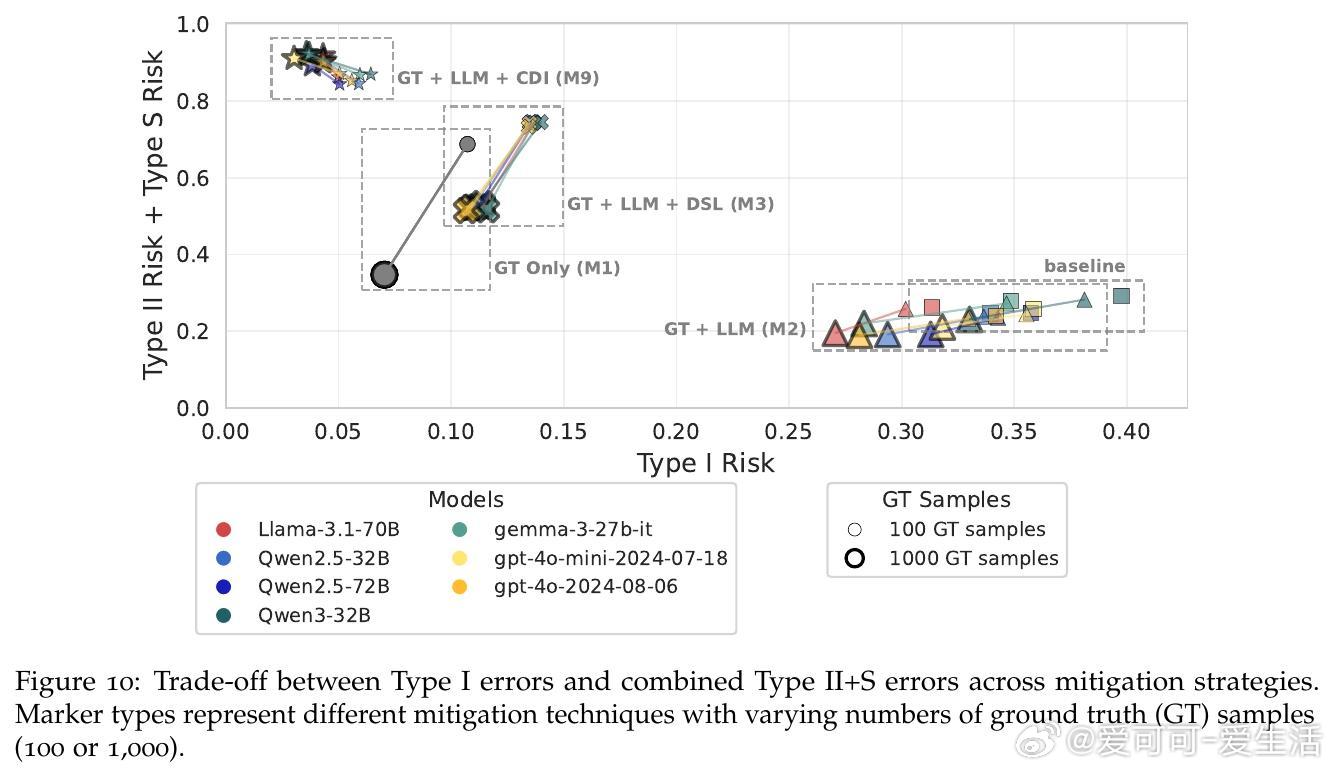
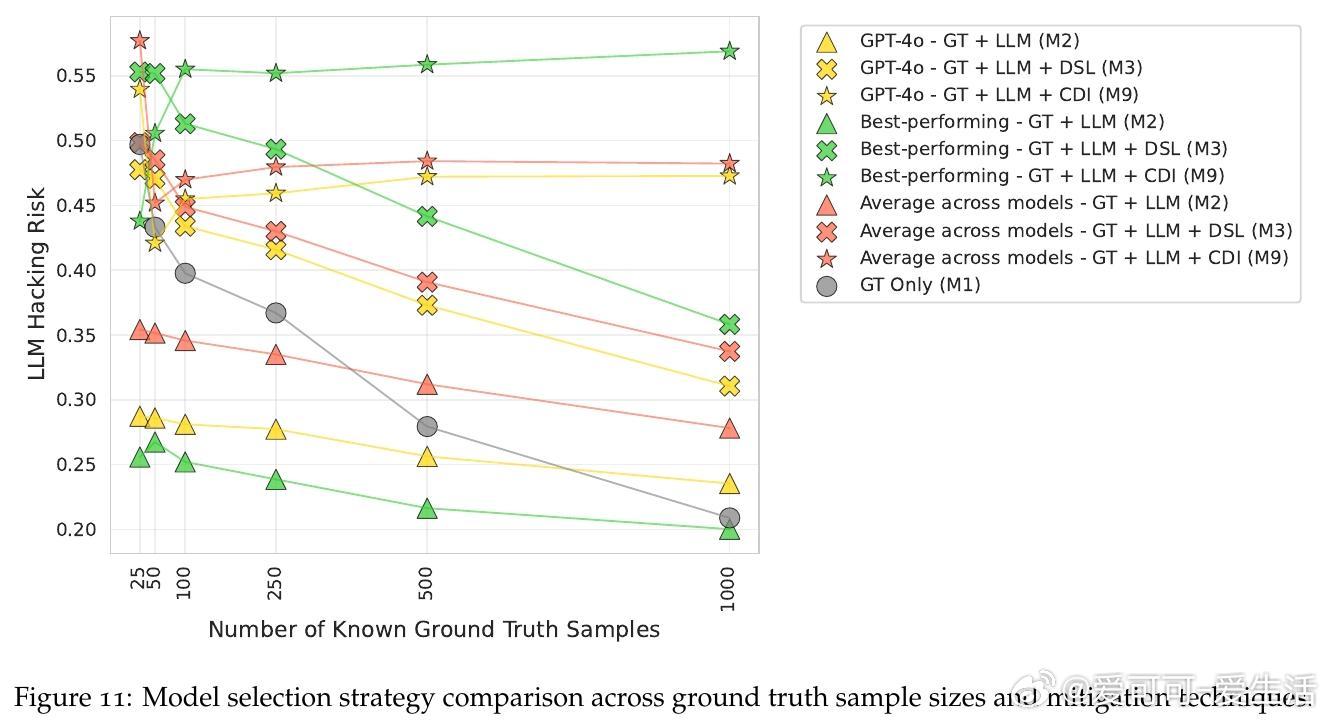
• 现行统计校正手段(如设计监督学习、置信驱动推断)存在权衡难题,降低假阳性却显著增加假阴性,整体效果有限。
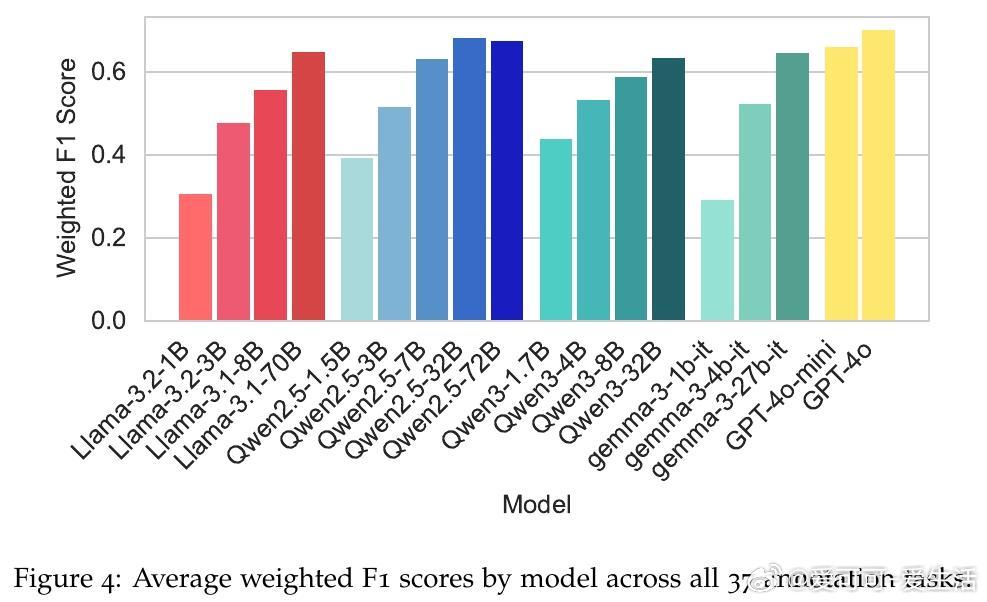
• 100份人工标注数据优于10万份LLM标注,强调人类校验在保障科学结论有效性中的不可替代作用。
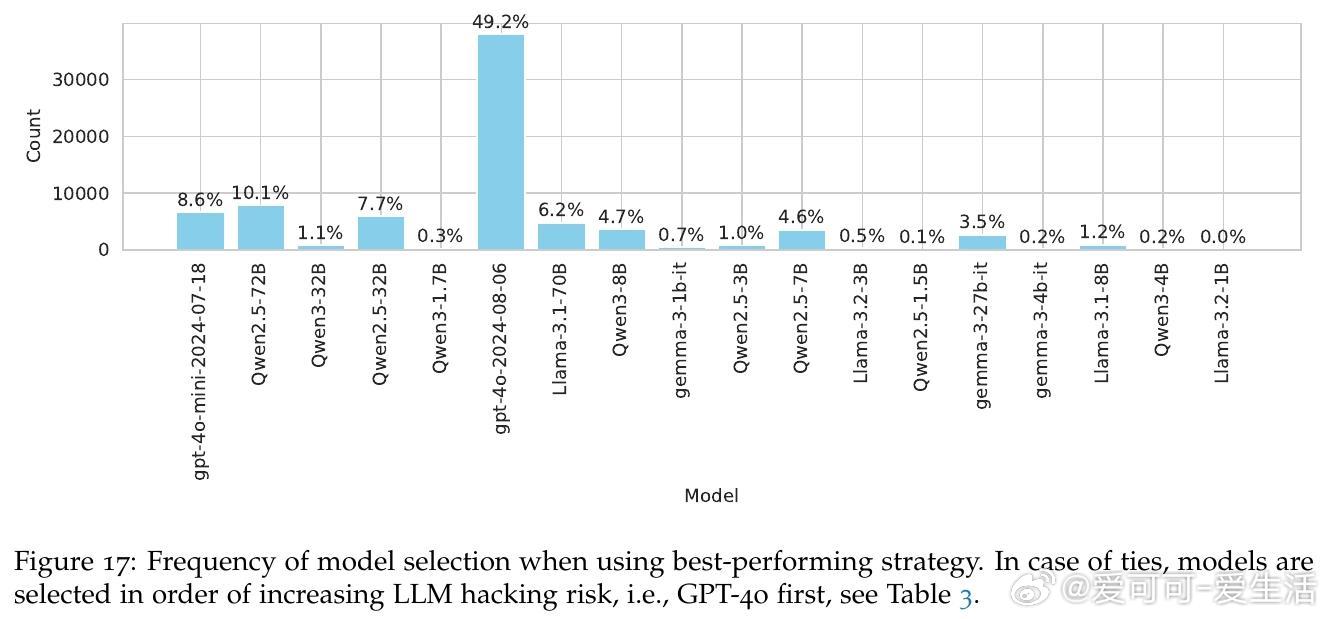
• 故意LLM黑客极易实现:通过少量模型和提示变体即可制造94.4%的假阳性和98.1%的假阴性,甚至颠覆68.3%的真实效应方向。
• 研究呼吁从“便捷黑箱”转向“需严格校准和验证的复杂工具”,并提出详尽使用指南,倡导预注册配置、全透明报告以防止滥用与误用。
心得:
1. 自动化便利背后隐藏着决策自由度引发的系统性偏差,科学研究必须重视数据生成阶段的风险管理。
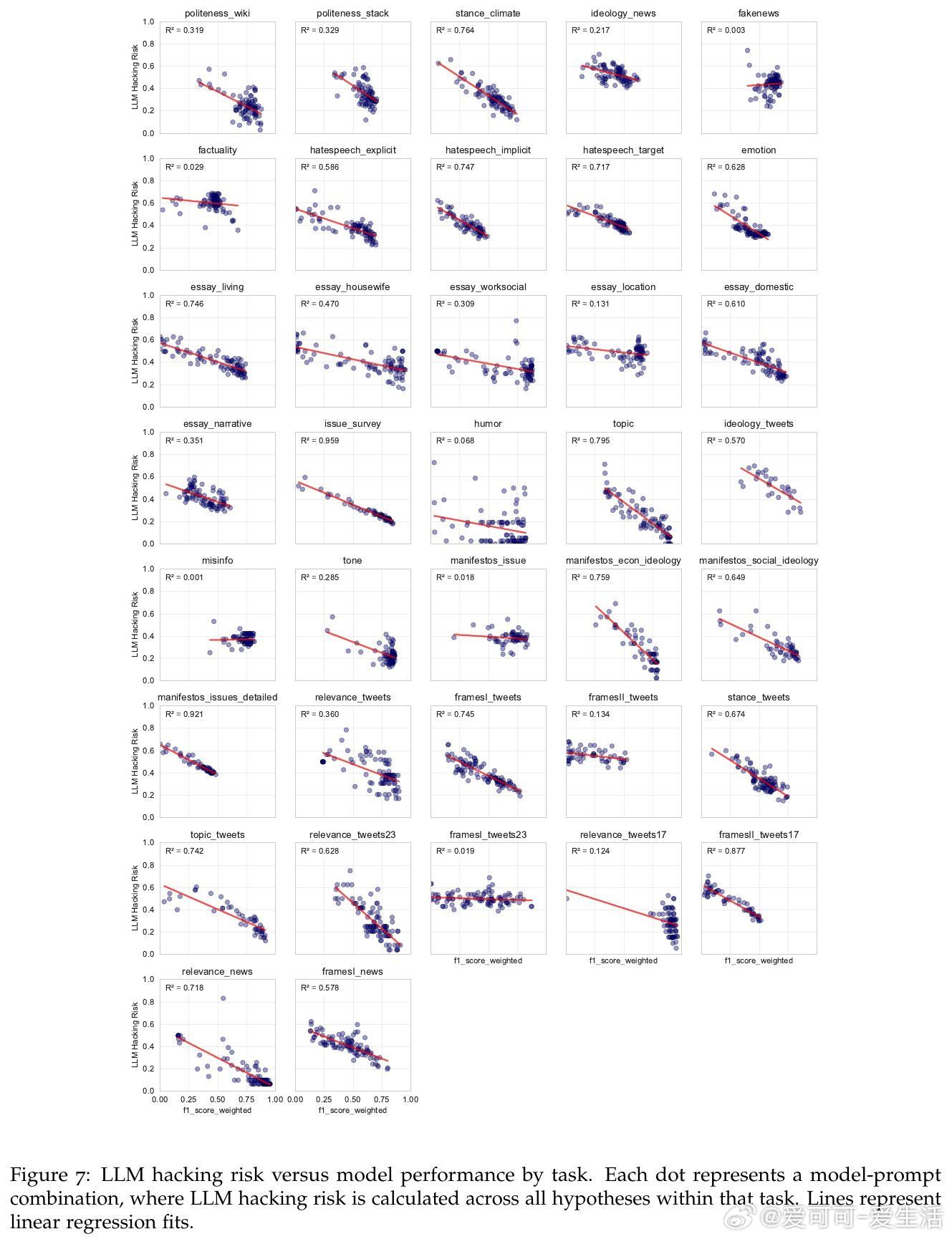
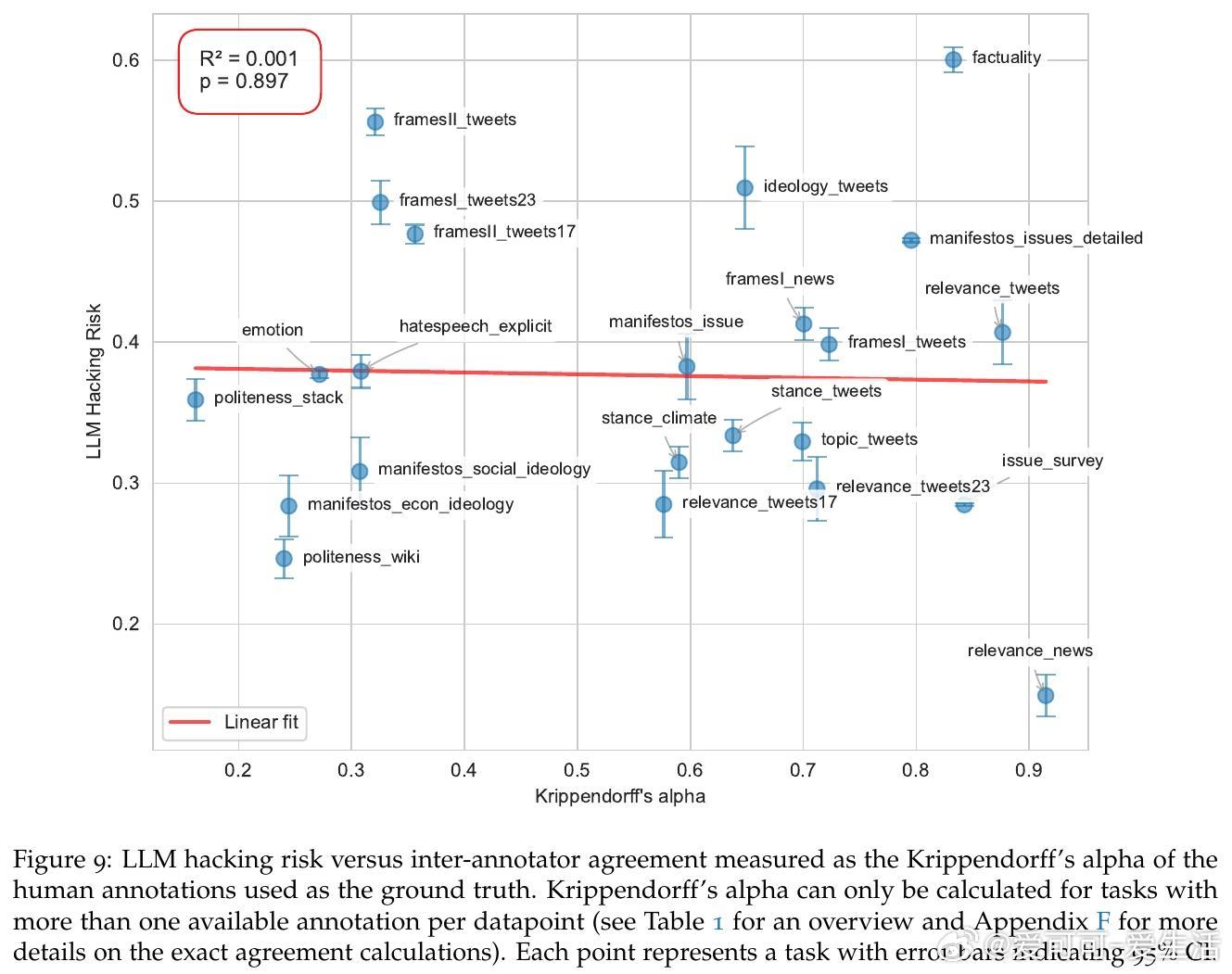
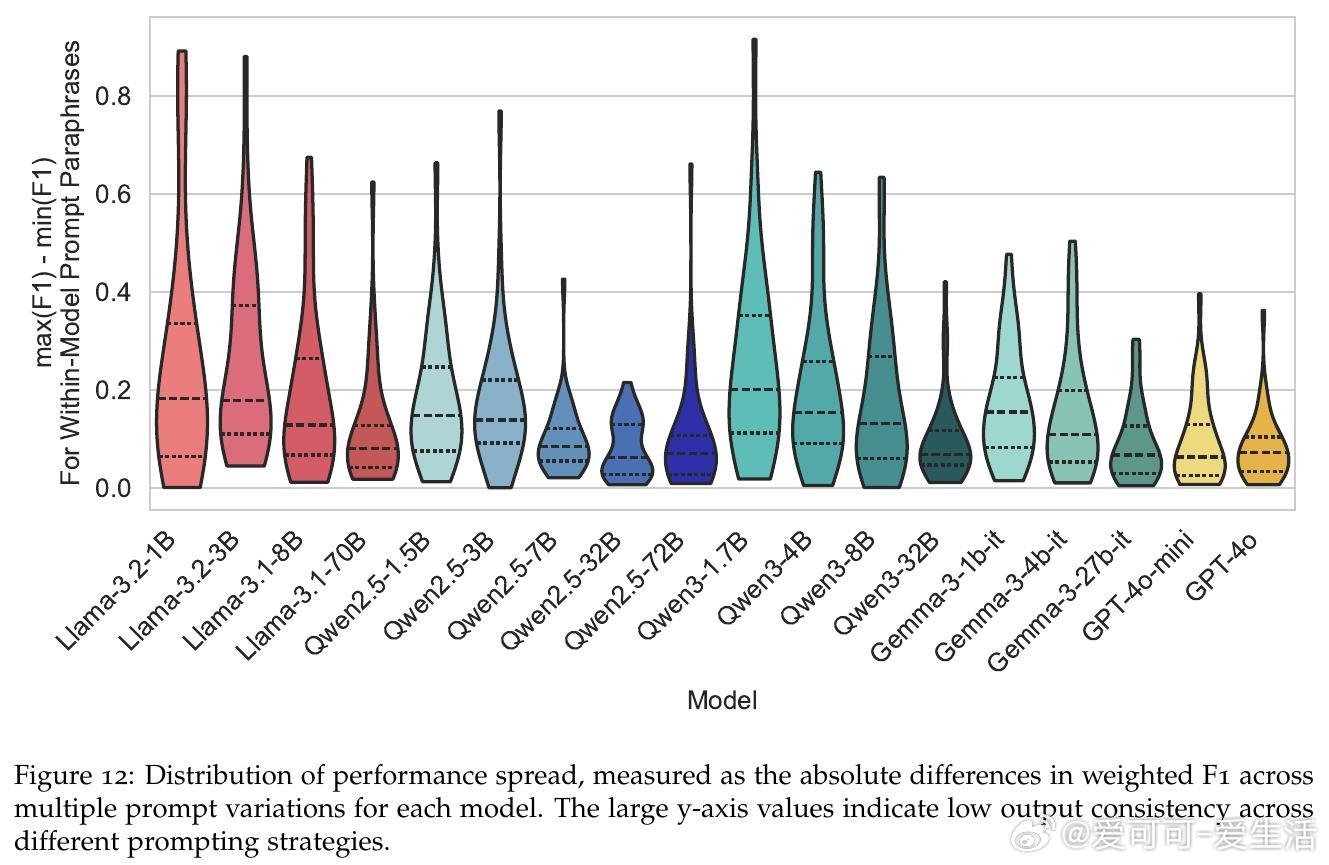
2. 配置敏感性和任务特性对结果影响远大于提示工程,提示设计并非万能解药。
3. 人工标注依然是保障统计推断可信度的基石,自动化应作为辅助而非替代。
详见🔗arxiv.org/abs/2509.08825
人工智能社会科学大语言模型数据标注科学方法模型验证统计学