[CL]《Saturation-Driven Dataset Generation for LLM Mathematical Reasoning in the TPTP Ecosystem》V Quesnel, D Sileo [Univ. Lille] (2025)
推动大语言模型(LLM)数学推理极限的关键在于高质量的逻辑严谨训练数据。本文提出了基于TPTP公理库与E-prover饱和推理机制的全新数据生成框架,实现了数学定理的自动、系统、无误生成,并设计三大逻辑推理任务精准评测模型能力。
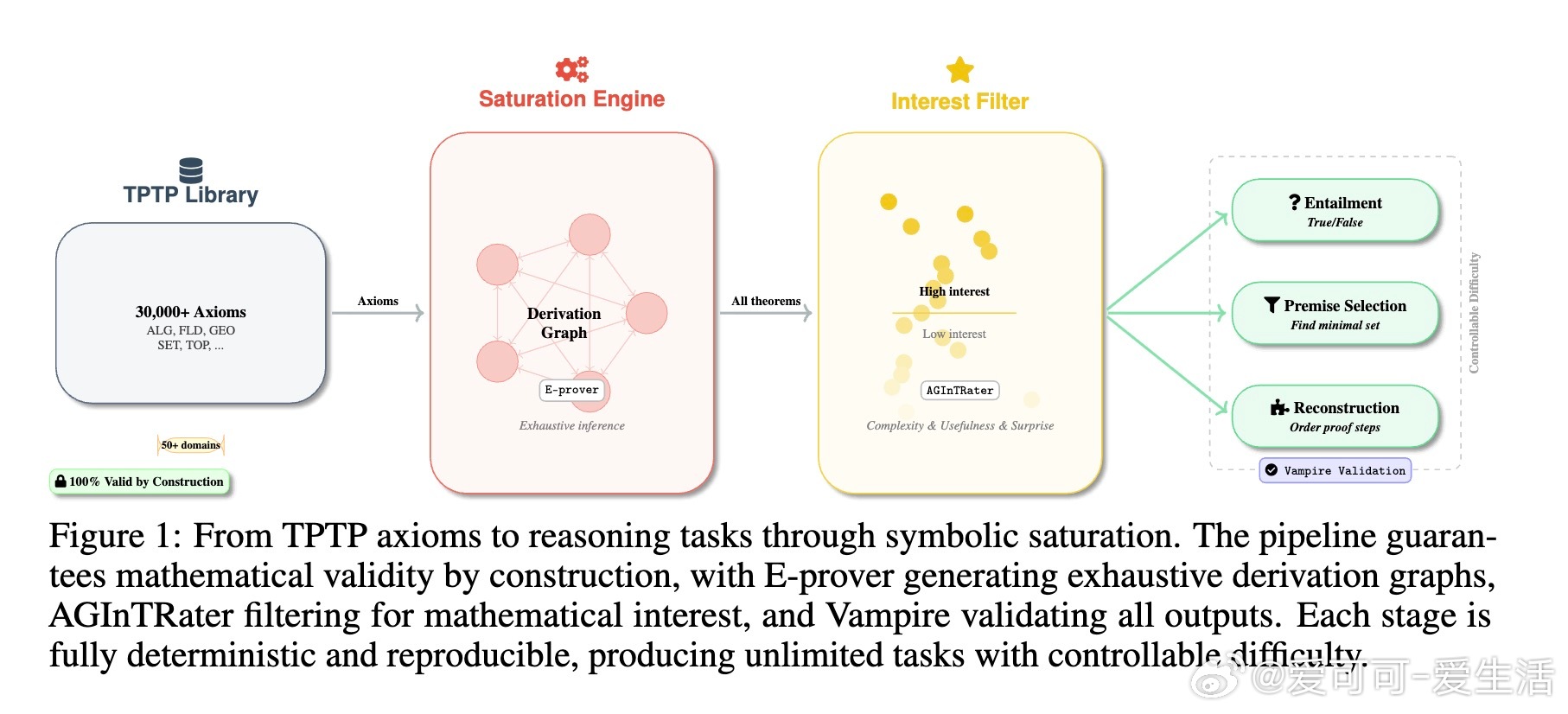
• 纯符号化生成:利用E-prover的饱和推理生成庞大、完备的逻辑推导图,确保数学定理“构造即有效”,杜绝LLM生成的事实错误。
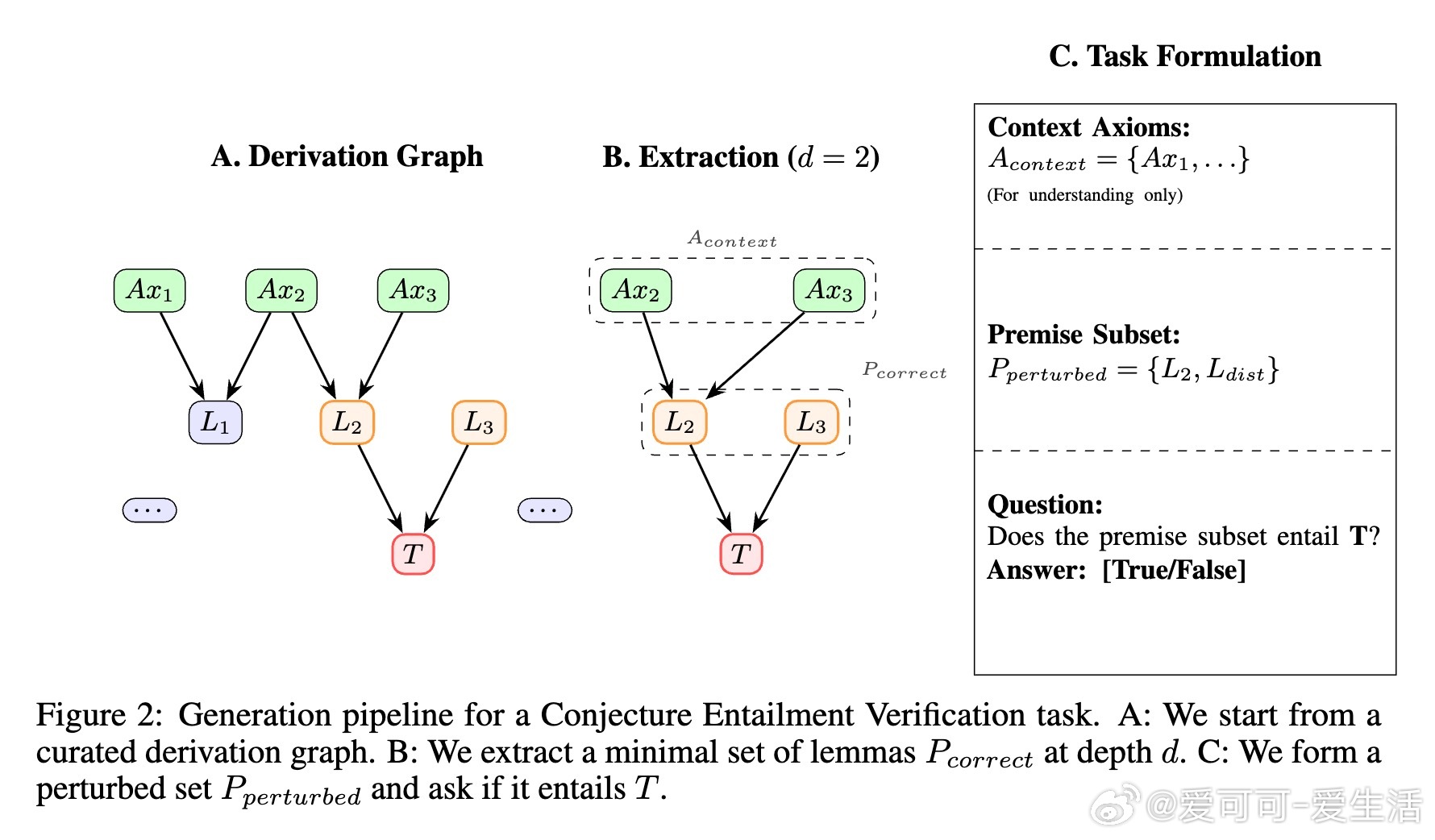
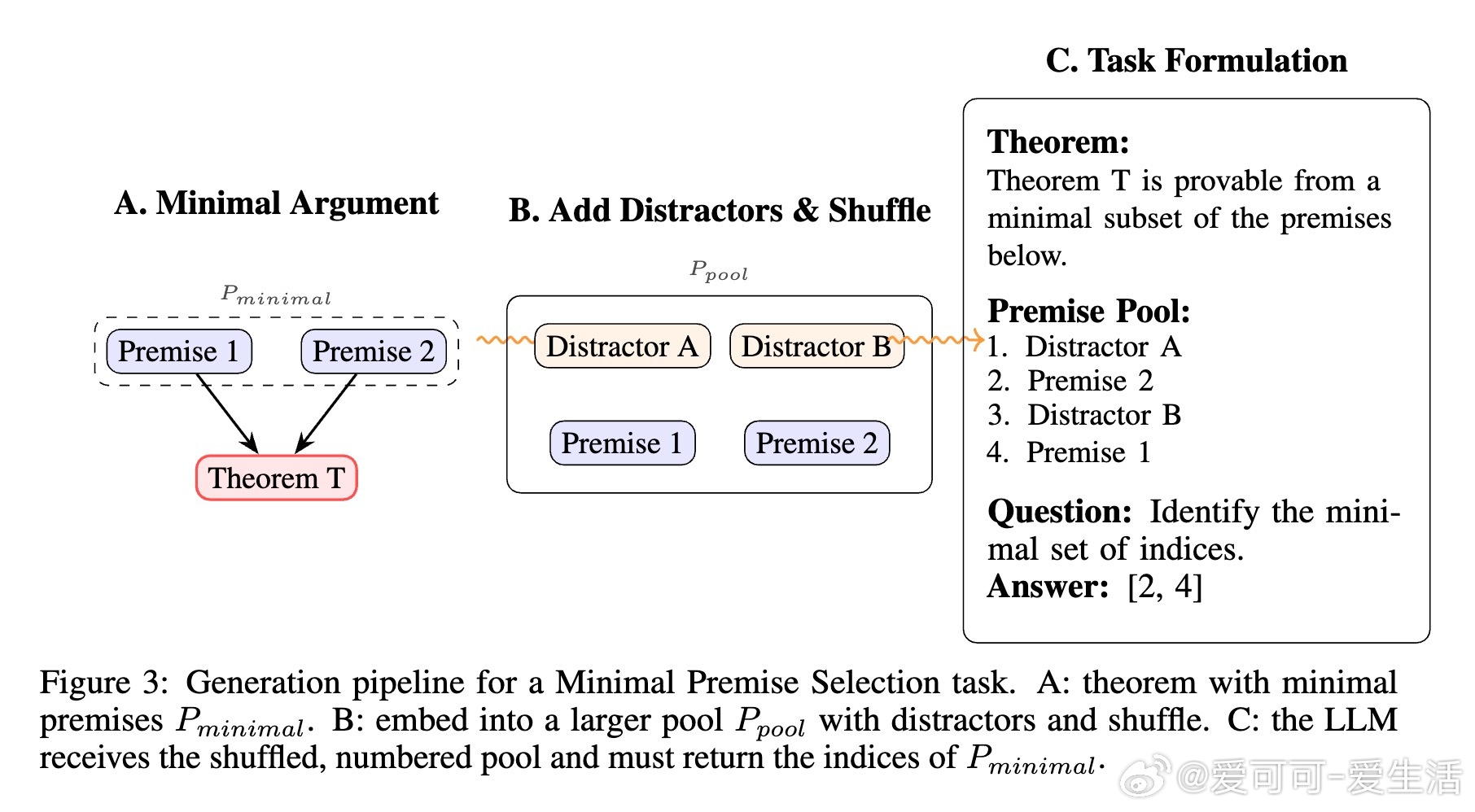
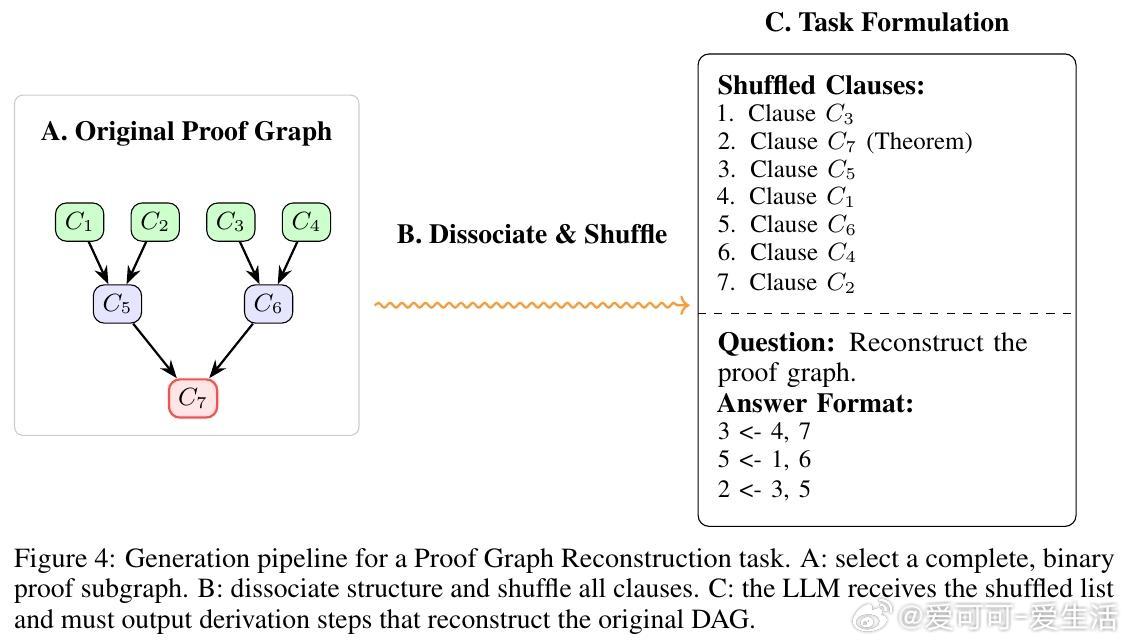
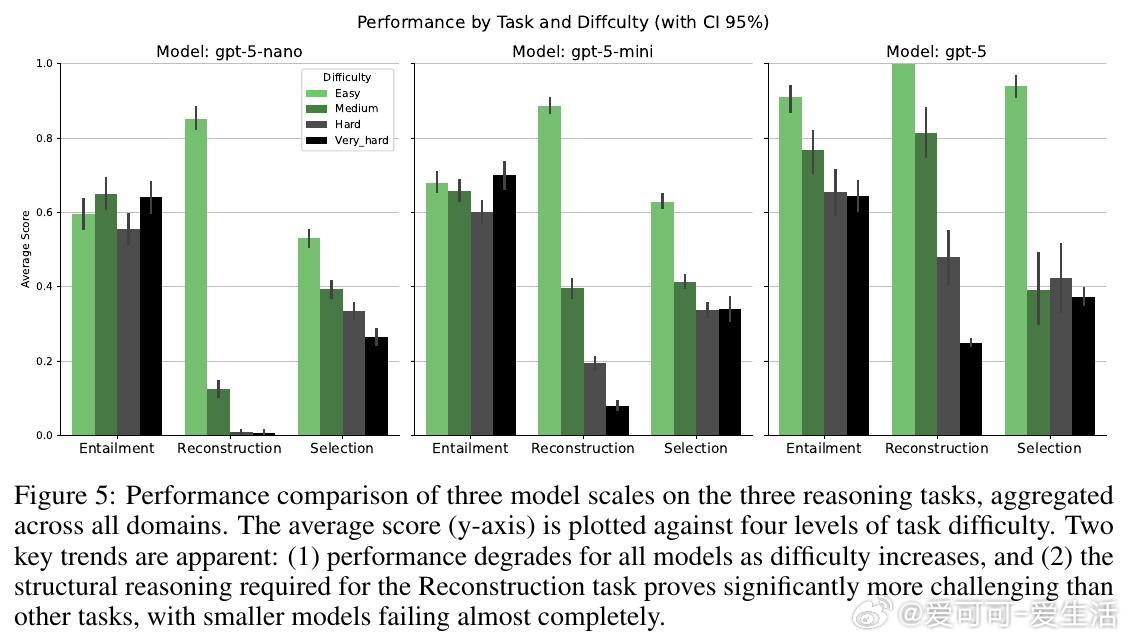
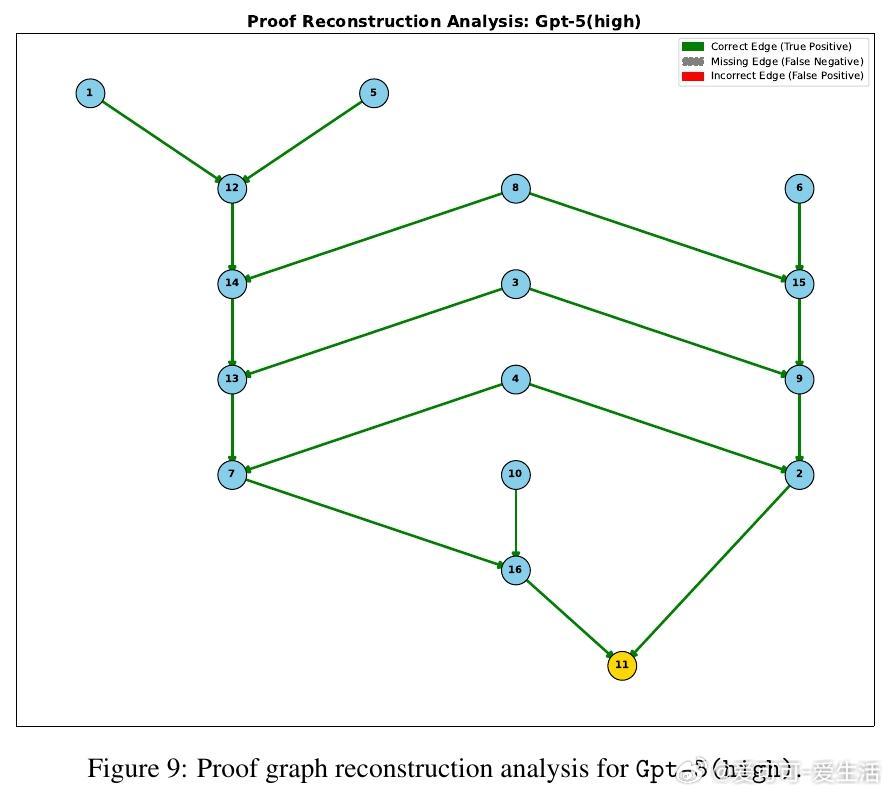
• 任务细分精准:分解定理证明为“命题蕴含验证”“最小前提选择”“证明图重构”三大任务,覆盖从局部验证到全局结构重建的推理深度。
• 复杂度可控:通过调整证明深度、前提扰动与干扰项数量,精细调节任务难度,实现从简单验证到高难度结构推理的全谱覆盖。
• 公开可复现:代码及数据集开源,支持无限制扩展,助力社区持续打造符号推理训练与评测基准。
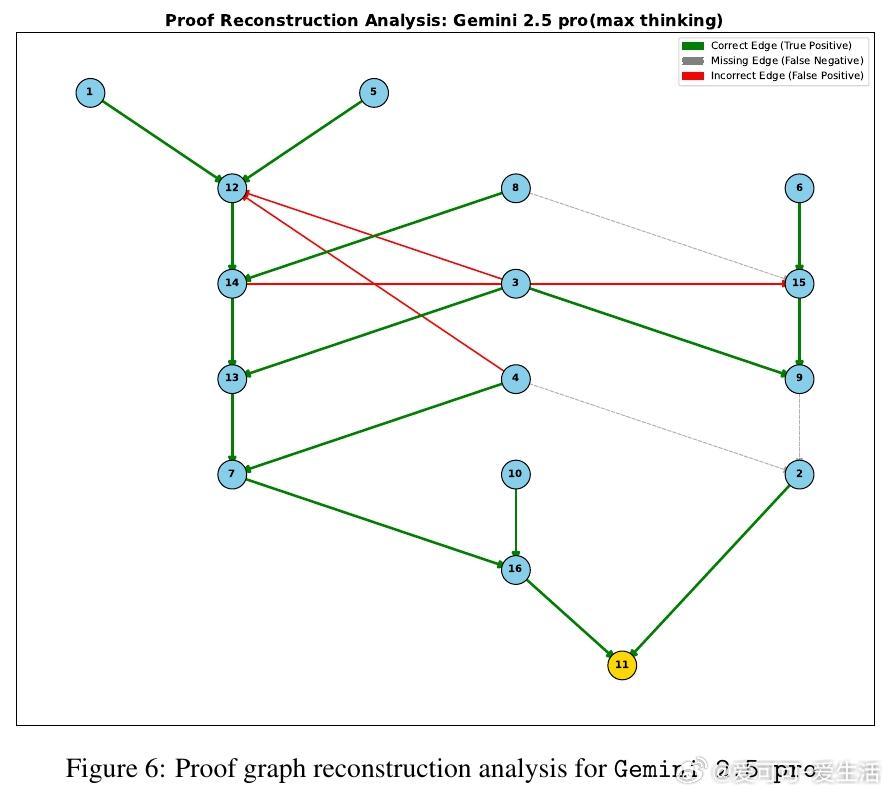
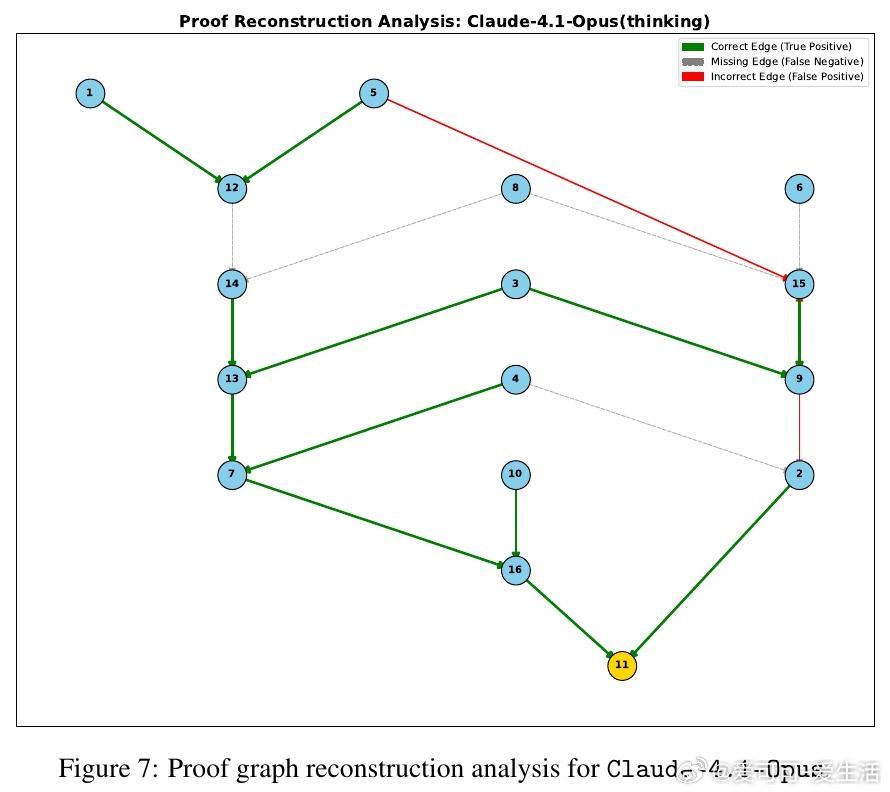
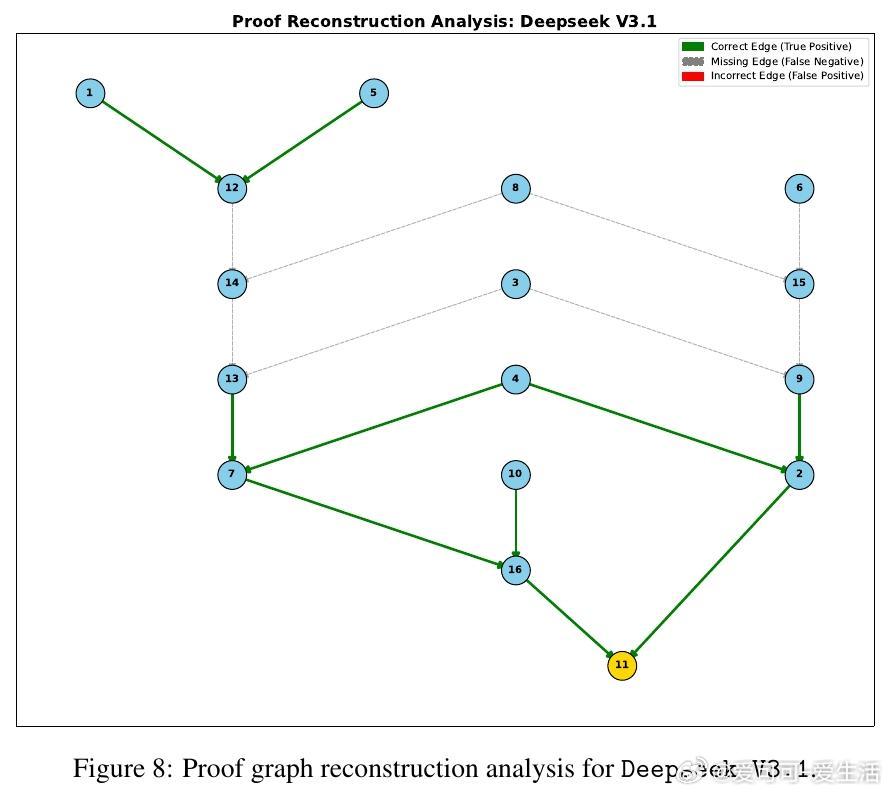
• 实验洞察:零样本测试显示,尽管大模型在浅层推理表现良好,但对多步、结构性推理(证明图重构)表现崩溃,规模扩大虽提升性能,却无法根本解决层级规划能力缺失。
• 未来方向:计划利用生成数据微调LLM以实现符号推理向自然语言推理迁移,构建迭代饱和机制深挖理论闭包,扩展至更通用的全一阶逻辑(FOL)推理任务。
心得:
1. 逻辑推理难点不在单步推断,而是模型对复杂证明结构的全局理解和规划能力。
2. 纯符号数据剥离自然语言干扰,提供了评估和训练推理能力的清晰切入点。
3. 规模虽重要,但突破结构推理瓶颈更需专门设计的训练数据与任务机制,简单放大模型难以根治。
详见🔗arxiv.org/abs/2509.06809
代码与数据👉github.com/sileod/reasoning_core
数据集地址👉hf.co/datasets/reasoning-core/rc1
人工智能大规模语言模型数学推理自动定理证明符号推理数据生成逻辑推理