[LG]《floq: Training Critics via Flow-Matching for Scaling Compute in Value-Based RL》B Agrawalla, M Nauman, K Agarwal, A Kumar [CMU & University of Warsaw] (2025)
floq:通过流匹配训练Q函数,实现价值型强化学习中的计算规模化提升
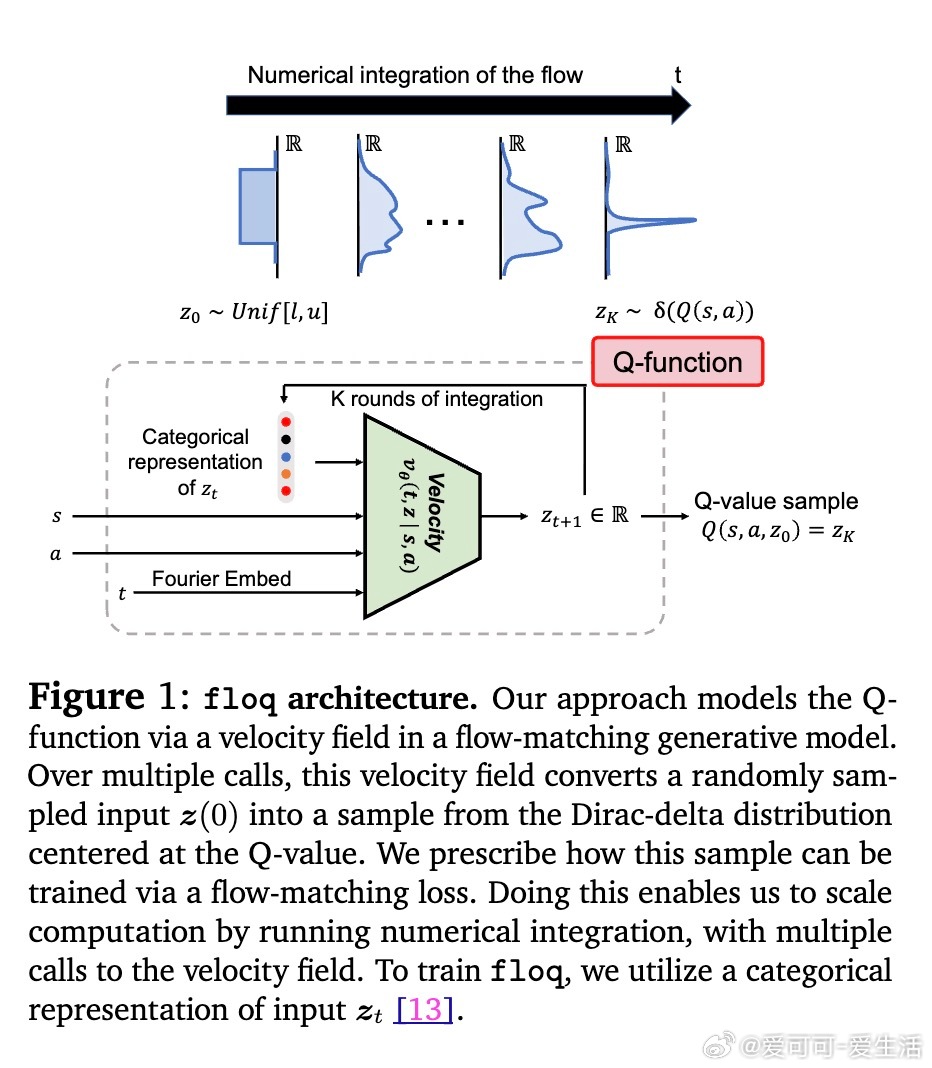
• 创新地将Q函数建模为条件于状态动作的一维潜变量上的时间依赖速度场,通过数值积分将随机初始噪声映射至Q值,打破传统单体网络架构的限制。
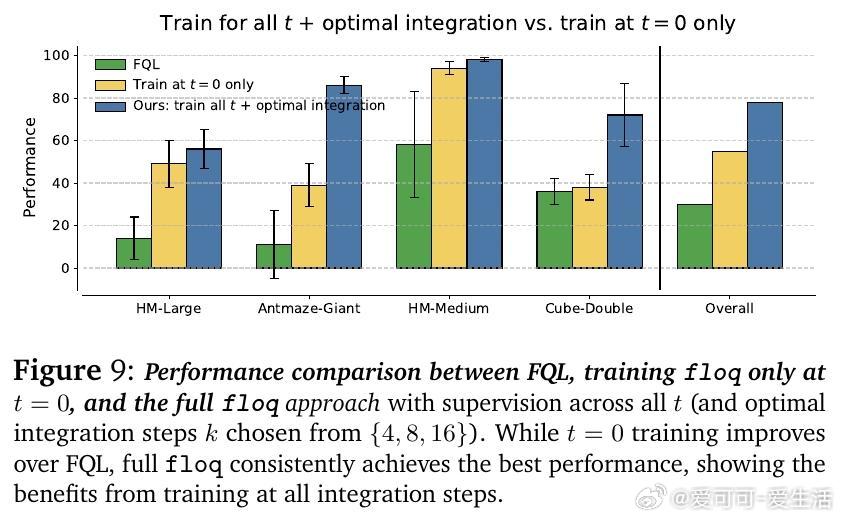
• 采用流匹配(flow-matching)训练目标,对每一步积分轨迹施加密集监督,类似于语言模型的逐步预测或扩散模型的逐步去噪,实现迭代计算的优势最大化。
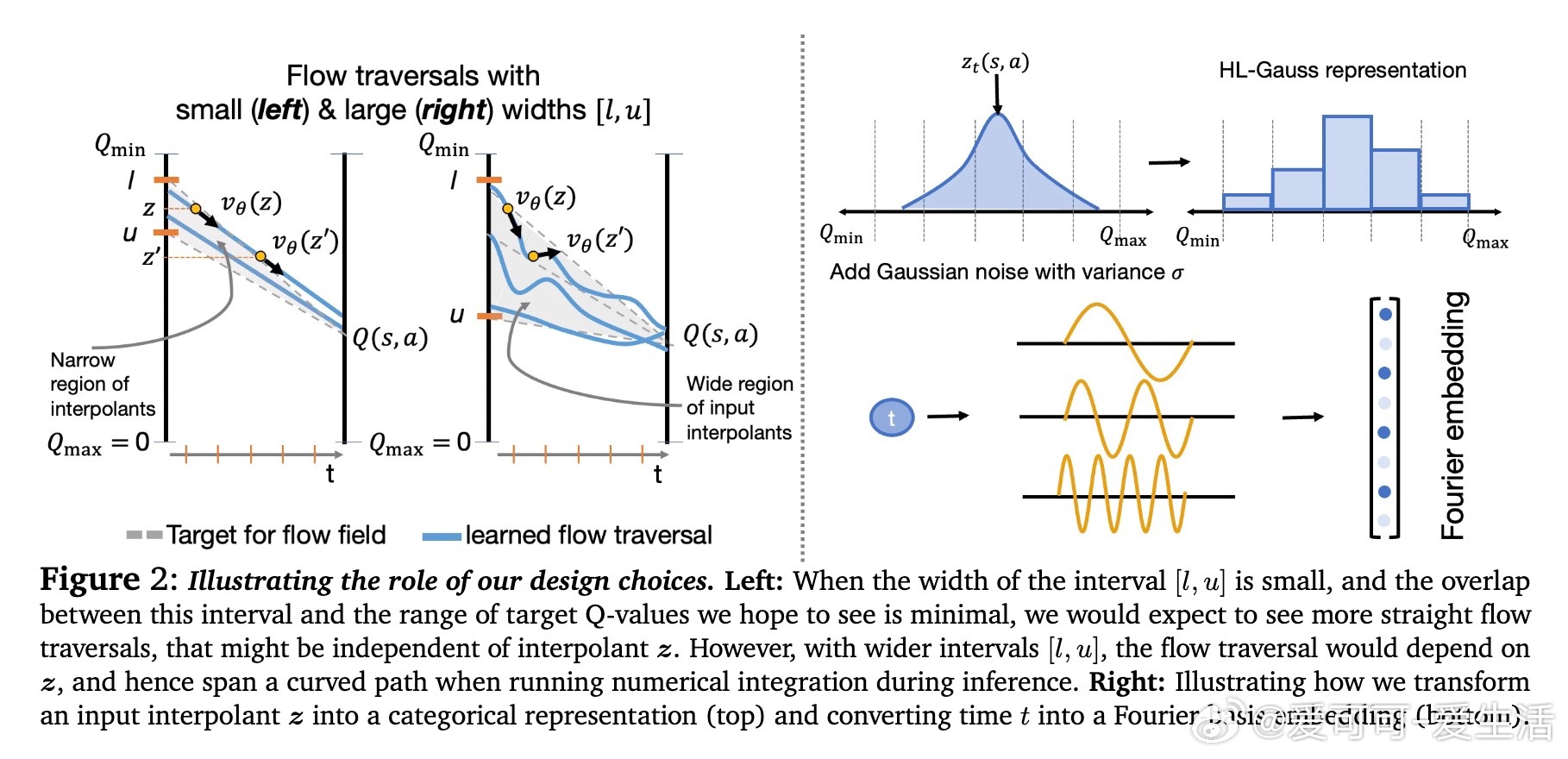
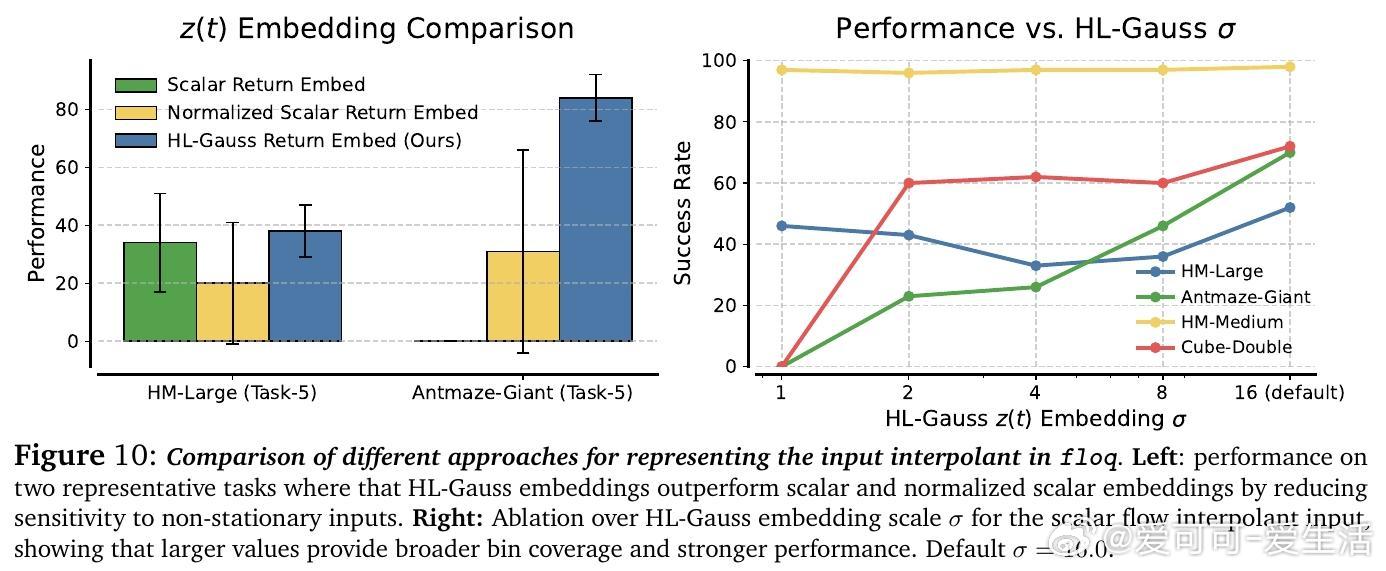
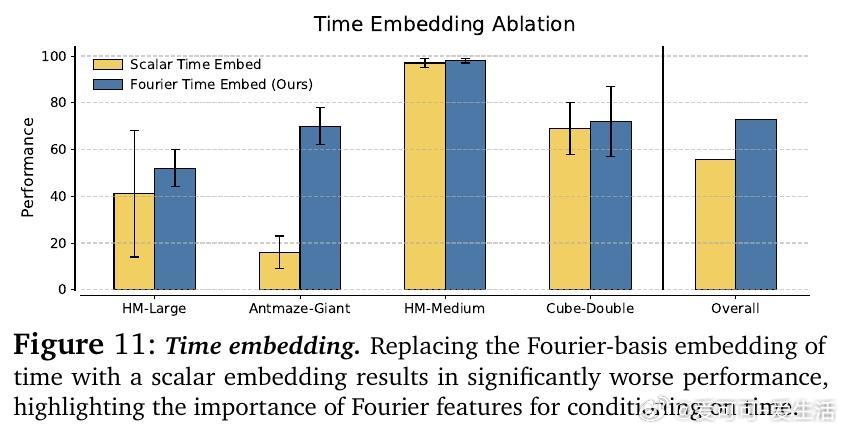
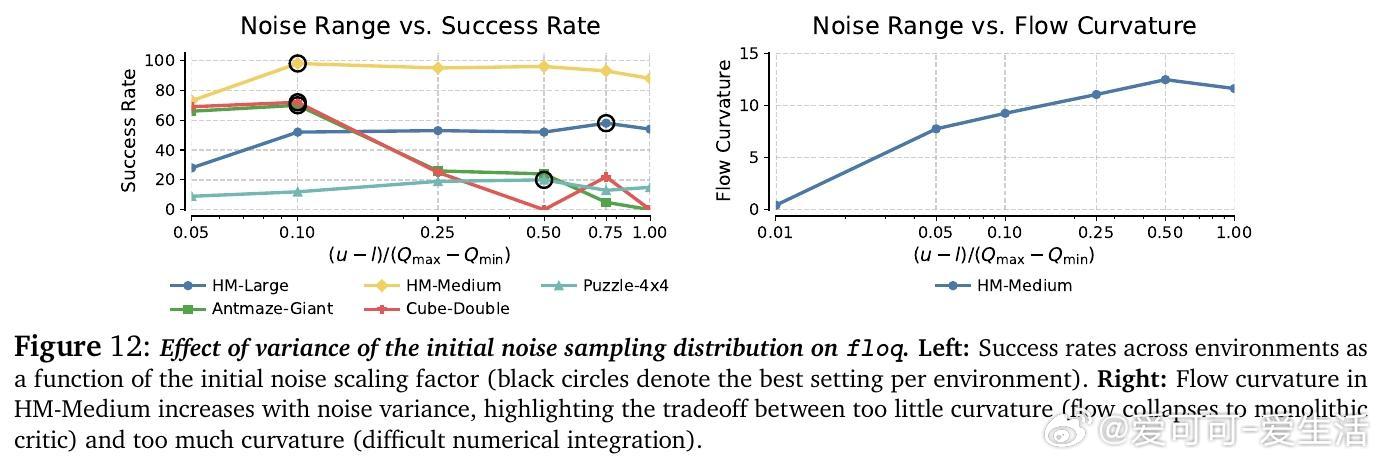
• 设计关键技术包括:选择覆盖目标Q值区间且适度宽泛的初始噪声分布,利用高斯直方图编码(HL-Gauss)防止输入非平稳性导致训练不稳定,及基于傅里叶特征的时间编码强化时间条件感知。
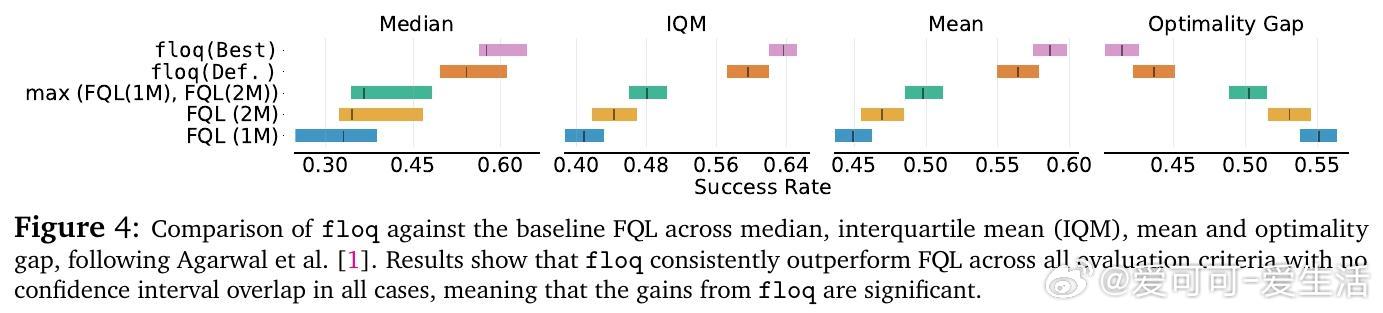
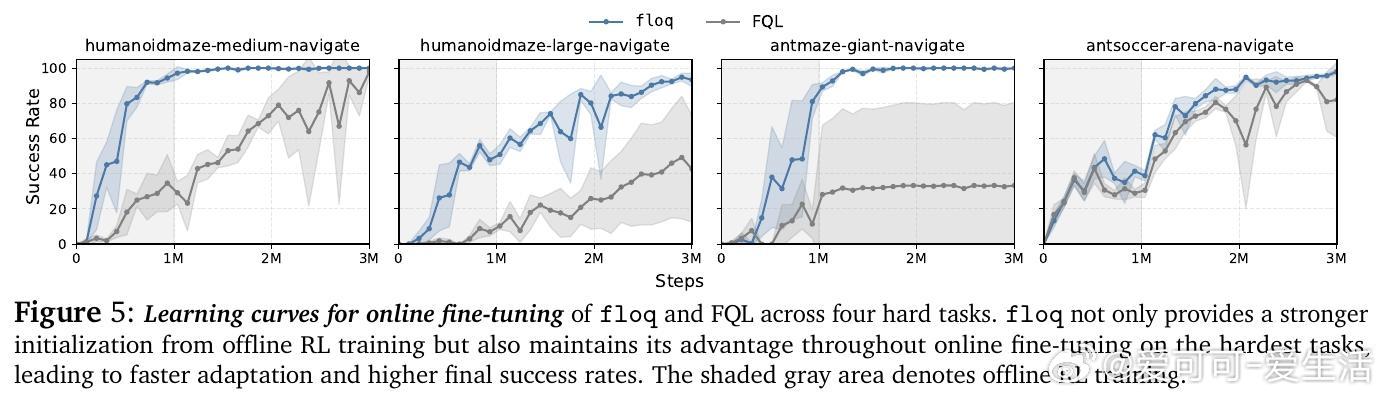
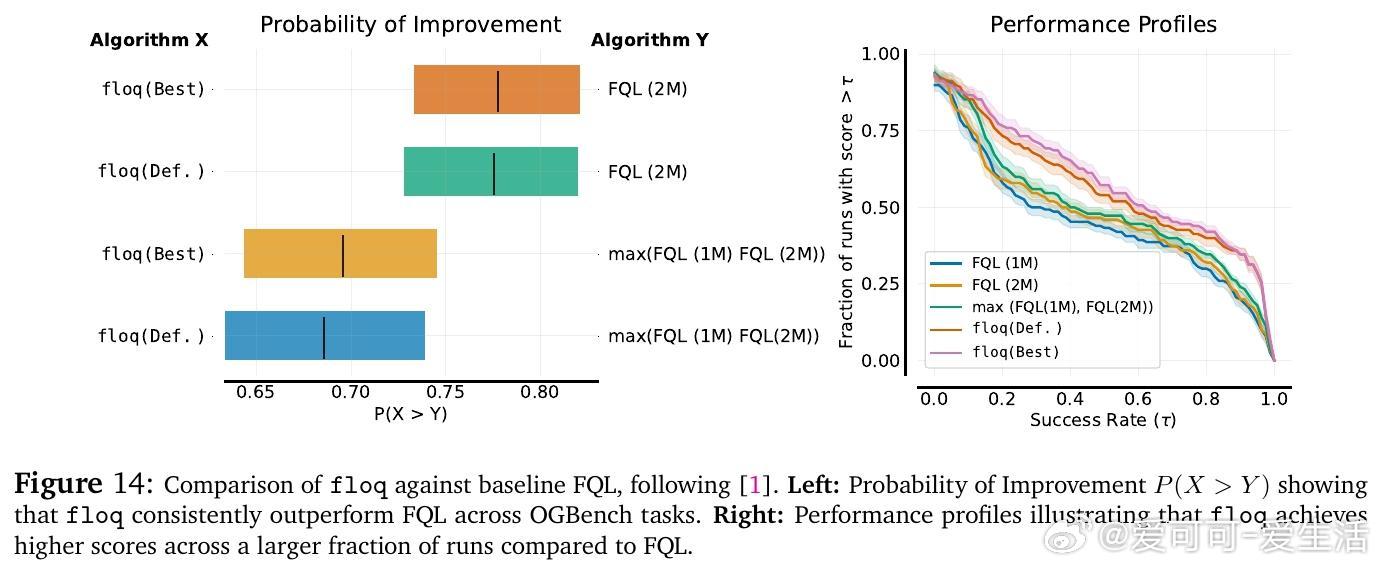
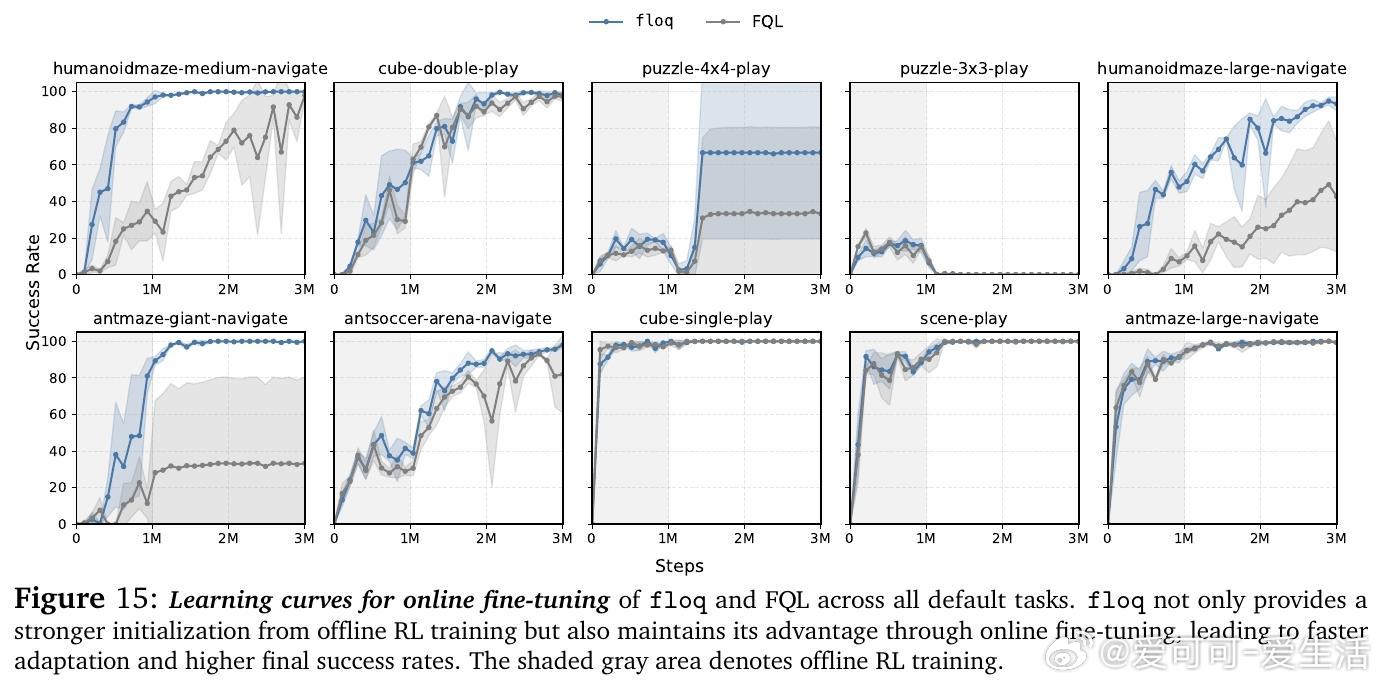
• 在OGBench离线强化学习50个复杂任务上,floq较传统单体Q网络提升近1.8倍性能,尤其在难度较大的任务上优势显著;在线微调阶段同样表现出更快适应和更高最终成功率。
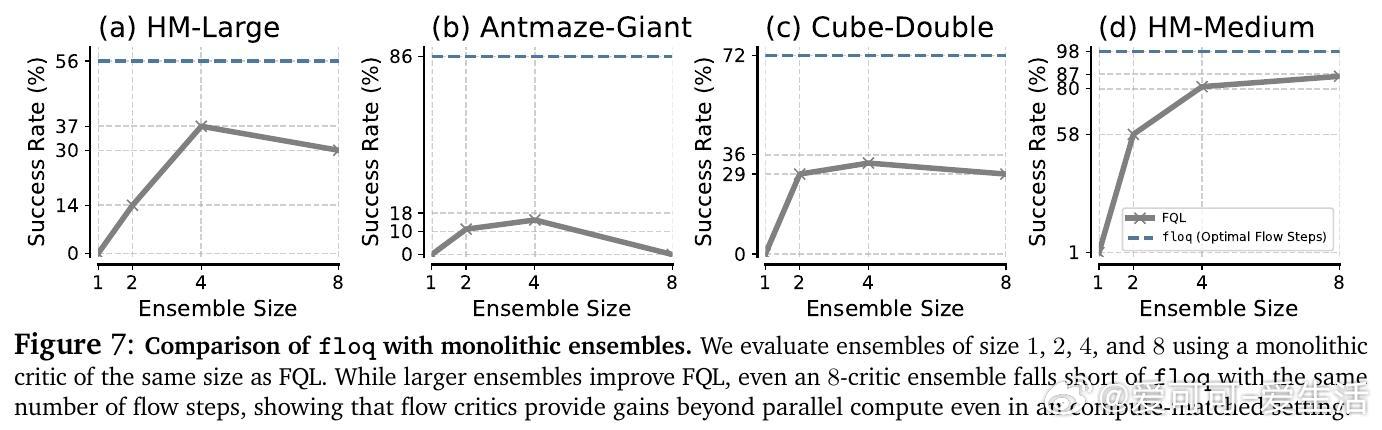
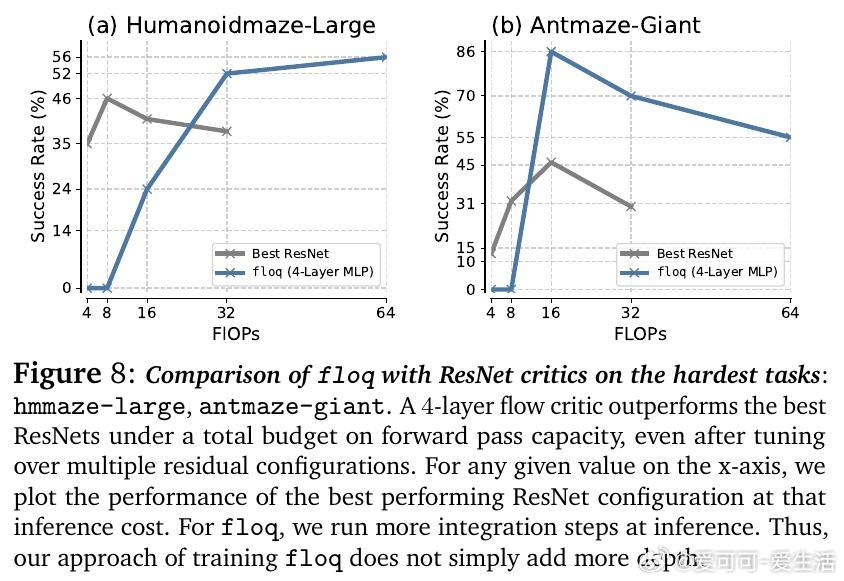
• 对比同等计算预算的Q网络集成与基于ResNet的序列计算,floq凭借其密集中间监督和迭代积分机制,显著提升表达能力和泛化表现。
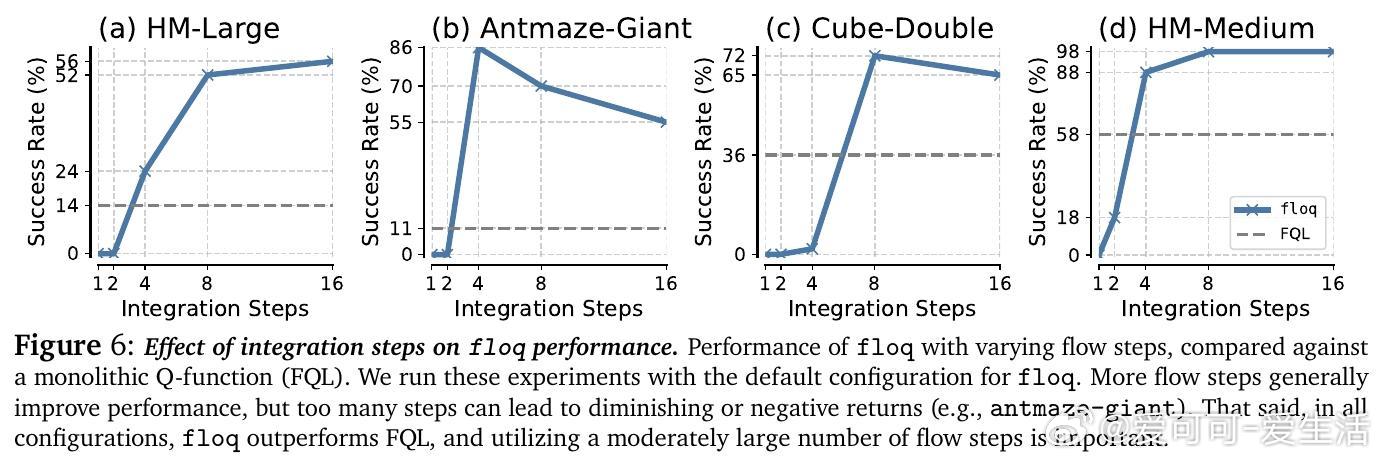
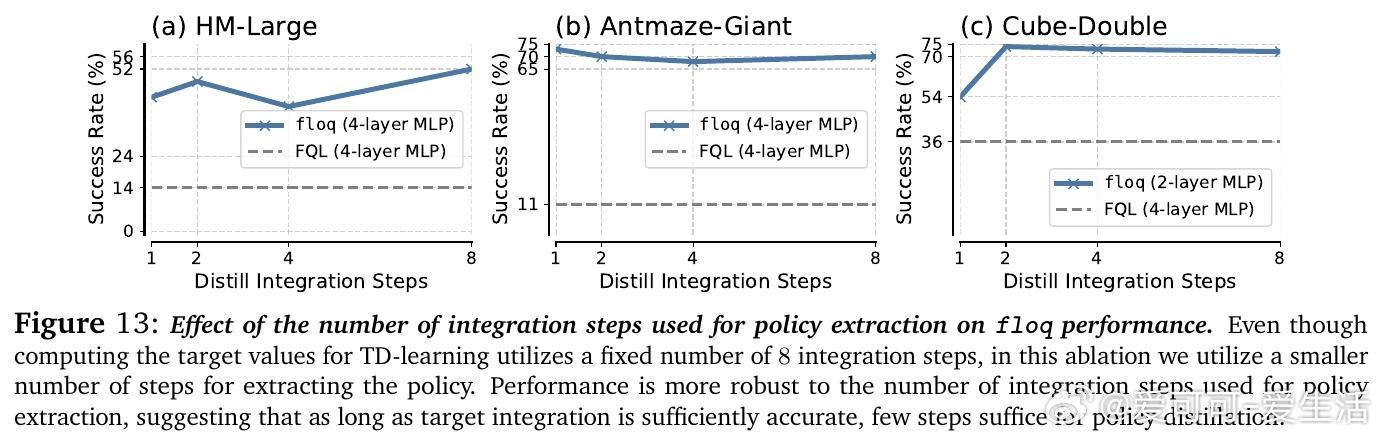
• 支持部署时“测试时扩展”——通过增加积分步数提升Q函数容量,无需增加参数量,为价值函数的计算规模化提出新范式。
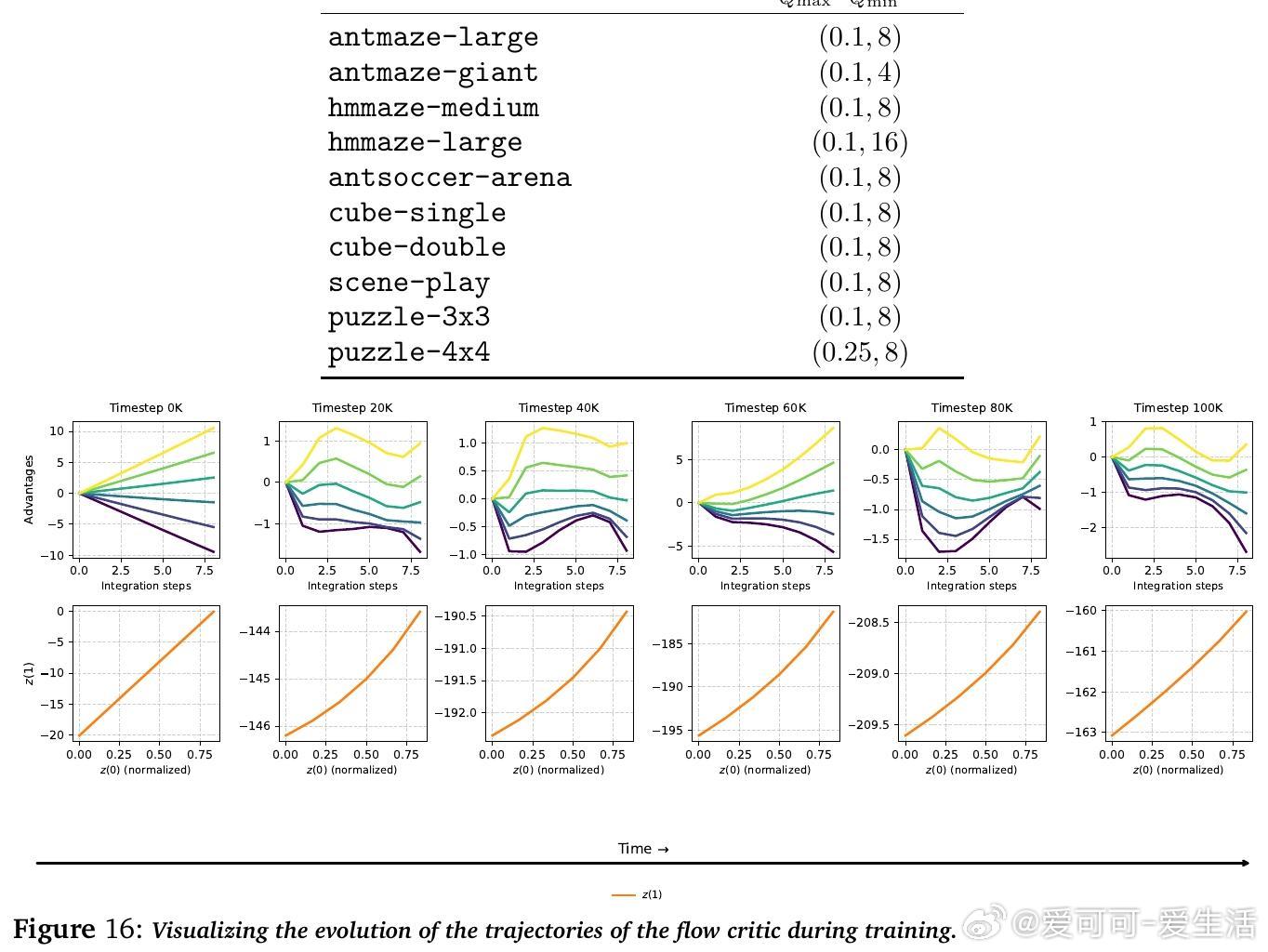
• 消融实验验证了HL-Gauss编码、傅里叶时间嵌入和适当噪声区间宽度对训练稳定性及性能提升的关键作用。
心得:
1. 迭代计算结合密集逐步监督是提升Q函数表达力和训练稳定性的核心,比单纯增加网络深度或宽度更有效。
2. 将流匹配技术从生成模型创新应用于价值估计,开辟了RL中使用微分方程积分表征和训练价值函数的新路径。
3. “测试时扩展”理念让价值函数的推理计算弹性提升,未来可结合并行集成和规划算法,实现更高效的资源利用和性能调优。
了解更多🔗arxiv.org/abs/2509.06863
强化学习价值函数流匹配迭代计算离线RL机器学习规模化