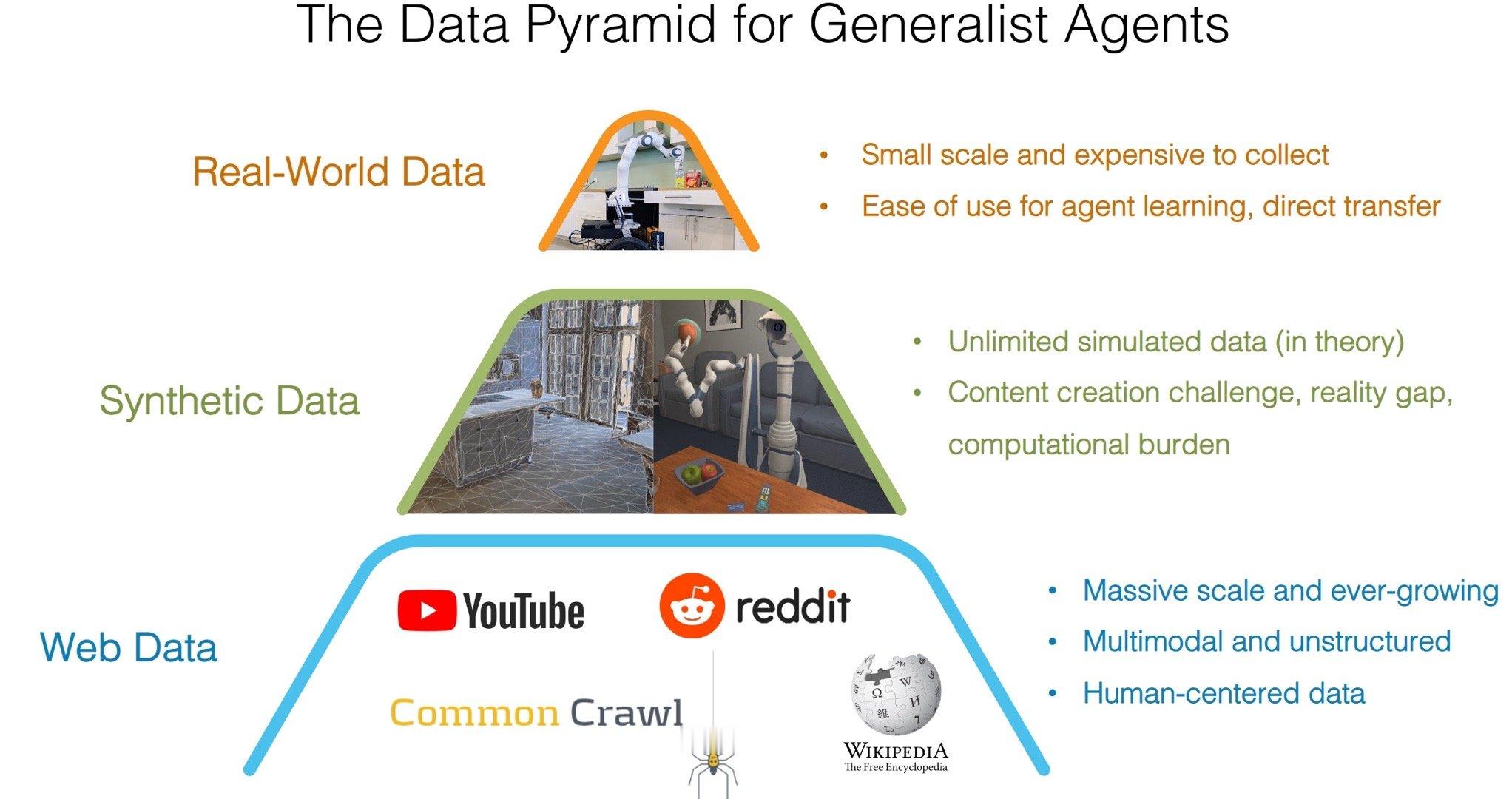
具身智能领域有一个数据金字塔的概念
底层供应量最大,成本最低的是网络数据,其次是合成数据,由算力决定上限,最后是真实数据,采集难度大,成本高。
现在具身智能从网络数据出发训练VLA模型,用合成数据进行机器人对齐,任务学习,最后用真实数据进行真实机器人的适配和验证。
而自动驾驶领域似乎是反过来的,因为有足够多的真实场景数据,所以很长一段时间,网络数据和合成数据都不被重视。
现在似乎不一样了,强化学习和世界模型都是合成数据的重要应用形式。例如小鹏就提到云端的虚拟训练,理想的重建技术,都是很好的例子。
而VLA也是逐步开始大量使用网络数据的开始。小鹏,理想,元戎都提到用了大量网络数据。
从这个角度来看,自动驾驶和具身智能对数据的应用历程似乎是反的。自动驾驶从上到下,具身智能从下到上。
不过最终目的也都是一致的,与真实物理世界可以足够稳定交互的人工智能。
汽车黑科技新能源大牛说ai创造营