[LG]《Large Language Models Achieve Gold Medal Performance at the International Olympiad on Astronomy & Astrophysics (IOAA)》L C D Pinheiro, Z Chen, B C Piazza, N Shroff... [The Ohio State University & Universidade de São Paulo] (2025)
大型语言模型(LLMs)在国际天文与天体物理奥林匹克竞赛(IOAA)中实现金牌级表现!
研究团队全面评测了五款顶尖LLM(包括GPT-5、Gemini 2.5 Pro等)在2022-2025年IOAA理论与数据分析考试中的表现。结果显示:
🔭 理论考试:
- GPT-5、Gemini 2.5 Pro两模型均达85%以上平均分,均超越200-300名人类参赛者中的大多数,稳居金牌水平。
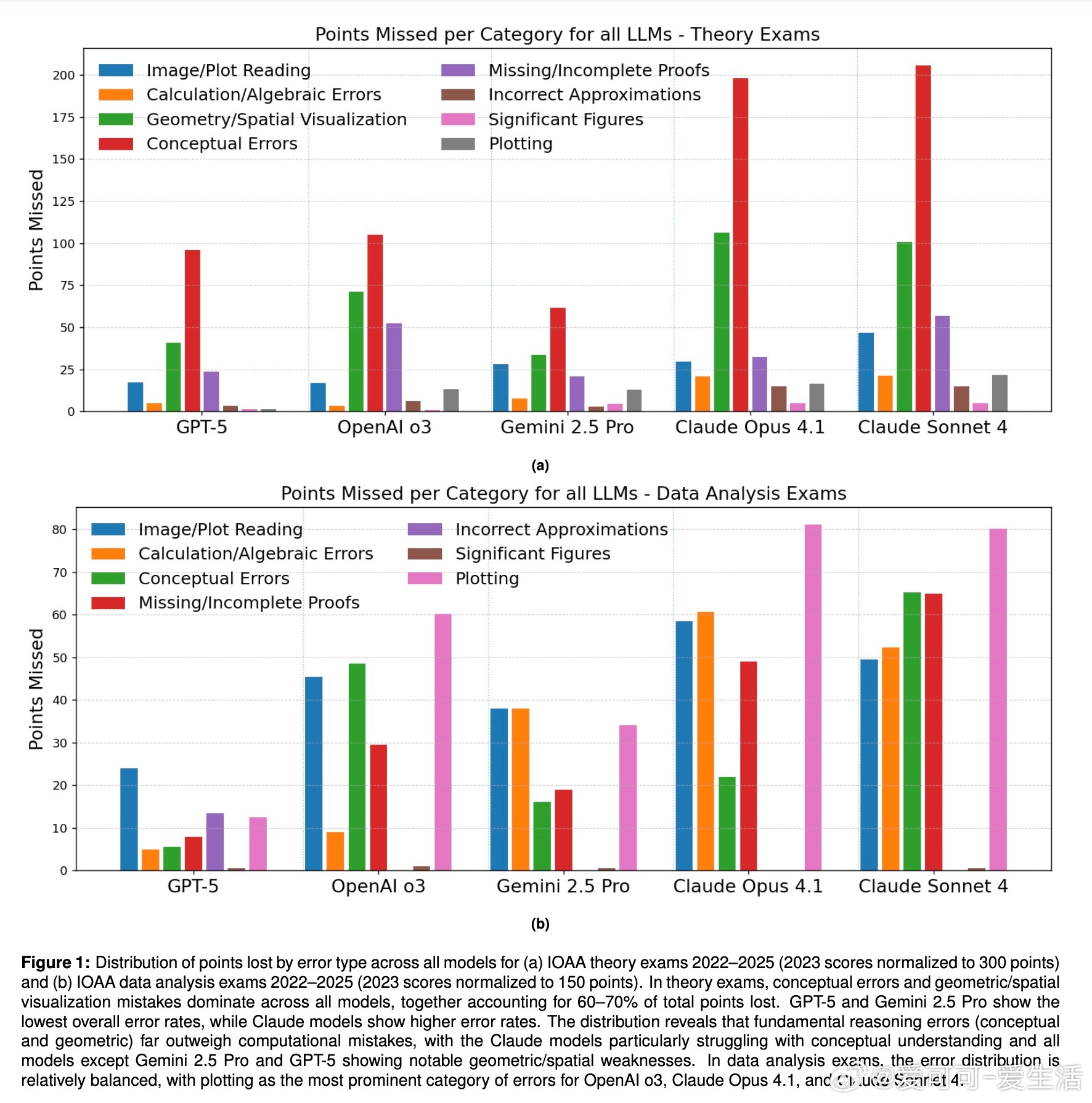
- LLM在物理与数学推理题表现优异(约90%准确率),但几何与空间推理题表现明显较弱(约50%-79%准确率),尤其在2024年强调空间几何的试题中表现差异显著。
- 主要失败原因包括:概念性错误、空间几何直观能力缺失、时间系统理解混淆等。
📊 数据分析考试:
- GPT-5表现抢眼,88.5%平均分,排名前十。其他模型表现波动较大,分数介于48%-76%。
- 数据分析题对绘图和图像理解需求高,GPT-5的多模态能力显著优于其他模型。
- 常见错误涉及图表解读失误及计算错误。
🧑🚀 对比人类:
- 理论考试中,GPT-5和Gemini 2.5 Pro多次超越顶级学生,稳获金牌。
- 数据分析考试中,GPT-5持续保持金牌水平,且排名靠前,展示出卓越的数据处理能力。
⚠️ 研究结论:
- LLMs已具备接近顶尖人类选手的理论推理能力,有望成为天文领域强有力的AI协作伙伴。
- 然而,几何空间推理、多模态视觉理解仍是瓶颈,需结合视觉草图等技术突破,提升空间想象和图像分析能力,才能迈向真正自主的天文研究助手。
📚 数据与方法:
- 评测涵盖49道理论题、8道数据分析题,均由两位IOAA专家严格按官方标准评分。
- 题目涵盖宇宙学、球面三角、恒星天体物理、天体力学、观测天文等多领域,确保评测全面且具挑战性。
- 使用LaTeX格式输入输出,模拟真实考试环境,确保结果严谨可信。
🔗 详情阅读:
本研究首次将国际天文奥赛作为综合性天文问题解决能力的benchmark,系统揭示LLM在深度科学推理中的强项与短板,为未来AI辅助天文研究指明方向。未来融合视觉草图、多模态训练有望极大提升AI空间推理与数据分析实力!
天文学 人工智能 大语言模型 IOAA 科学推理 多模态AI GPT5 Gemini2_5Pro